
爬虫最简单的架构就三个方面:
1.URL管理器:主要负责url的管理,可以添加新的url到爬取集合中,将url从待爬取移到已爬取集合等等功能,url管理器的实现方式主要分为3种,python内存中用集合set()来管理,关系数据库mysql,缓存数据库redis;
2.网页下载器:将url对应的网页下载到本地,主要的网页下载器有:urllib是python官方提供的模块,requests是一个强大的三方库;
现在就用urllib来下载网页试试:
下载1:
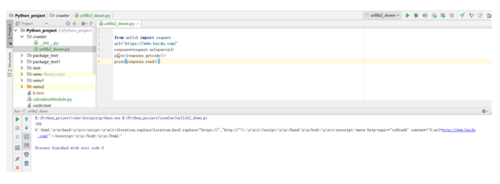
下载2:主要增加了一个请求头,有些情况下在请求的时候是需要指明请求头的一些信息的;
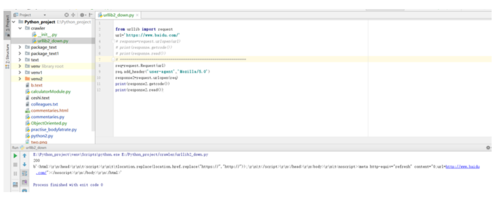
下载3:主要增加了对cookie的应用;
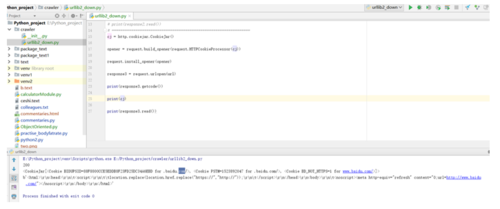
3.网页解析器:从网页中提取有价值的数据的工具,网页解析器也有很多,比如:用正则表达式,html.parser,beautifulsoup,lxml等等,其中最强大就是beautifulsoup这个第三方解析器,它可以指定解析方式,现在常用的解析方式就是dom树解析,其实就是根据节点去解析;
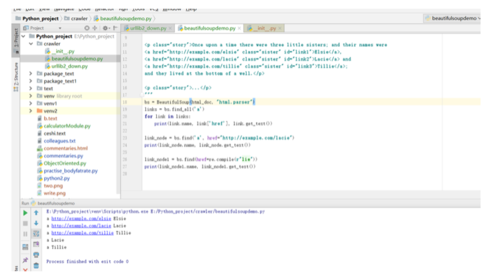
beautifulsoup的用法举例:
1.创建beautifulsoup对象,soup=beautifulsoup("文档字符串","html解析器","html文档的编码")
2.findall("节点","属性","文本"),并且支持正则表达式
3.获取信息:node.name:节点标签名称,node["href"]节点的href属性,node.get_text()节点的链接文字;
美女_百度百科
正式开始:在开始之前,我们确定目标,爬取百度百科美女词条的标题和简介
入口页:https://baike.baidu.com/item/美女
词条页面url格式:/item/青苔赋
数据格式——标题:<title> 美女_百度百科</title>
数据格式——简介:<meta name="keywords" context="美女 美女汉语词汇 美女女人分类 美女审美标准 美女中国美女出产代表地">
编码:UTF-8
美女_百度百科美女_百度百科美女_百度百科美女_百度百科
下面贴出主module的代码:代码也比较简单,没啥多讲的,只要按照思路一步一步走,就没啥问题,还是简单说一下逻辑:首先拿到目标url,这里需要注意一点就是url考进pycharm会自动被urlencode处理,因为很多字符在url里面是不能存在的,必须先经过编码过程,然后我们需要下载器,解析器,url管理器以及数据处理器这几个模块,我们在类初始化就去实例出这几个对象,然后我们把url添加进url管理器,然后在不断的轮询,通过urllib模块下载,通过BeautifulSoup解析,把新得到的urls添加进url管理器,把解析出来的数据添加进数据处理器,最后在把数据输出成html样式,输出的时候需要注意一点,因为我们的url是经过urlencode编码过的,所以要输出原样的url就必须解码出来,这里使用的是urllib的parse模块的unquote方法,解析出url,然后再把url,title,以及description以表格的形式写入html,最后得到html文件;
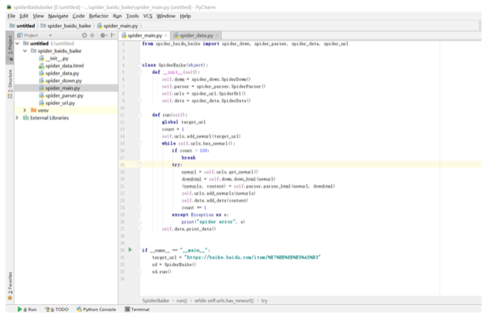
我们看看结果:

代码放在了github上面,地址:https://github.com/softwareXiaotao/spider_baidubaike
作者:hello_我的哥
链接:https://www.jianshu.com/p/0ff9a14076b6
共同学习,写下你的评论
评论加载中...
作者其他优质文章



