
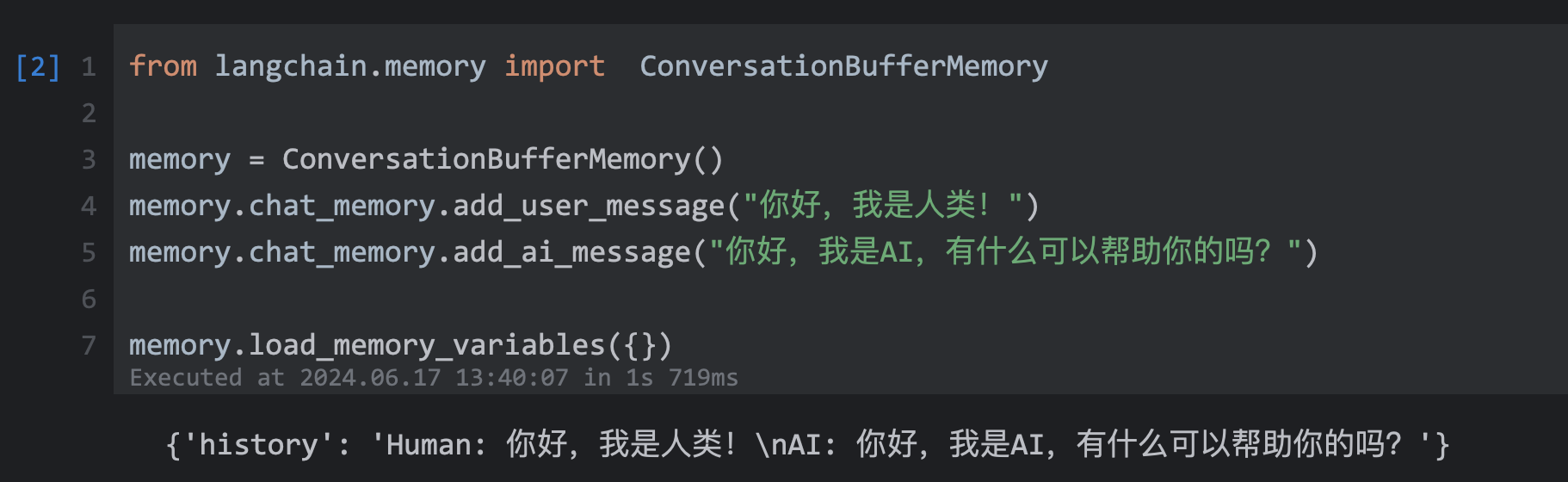
1 利用内存实现短时记忆
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("你好,我是人类!")
memory.chat_memory.add_ai_message("你好,我是AI,有什么可以帮助你的吗?")
memory.load_memory_variables({})
输出:
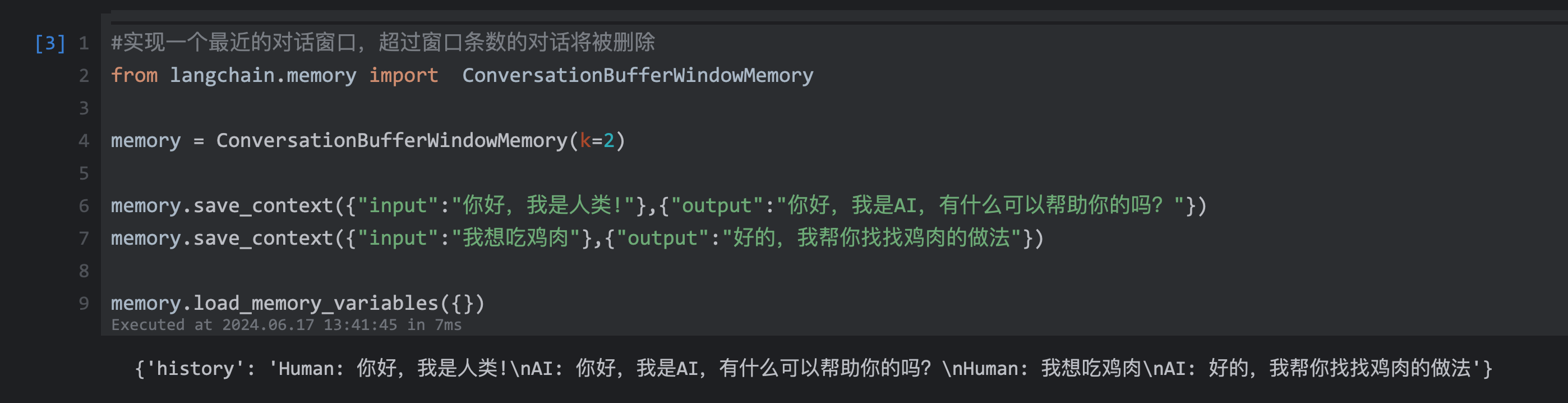
#实现一个最近的对话窗口,超过窗口条数的对话将被删除
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(k=2)
memory.save_context({"input":"你好,我是人类!"},{"output":"你好,我是AI,有什么可以帮助你的吗?"})
memory.save_context({"input":"我想吃鸡肉"},{"output":"好的,我帮你找找鸡肉的做法"})
memory.load_memory_variables({})
2 利用Entity memory构建实体记忆
3 利用知识图谱来构建记忆
4 利用对话摘要来兼容内存中的长对话
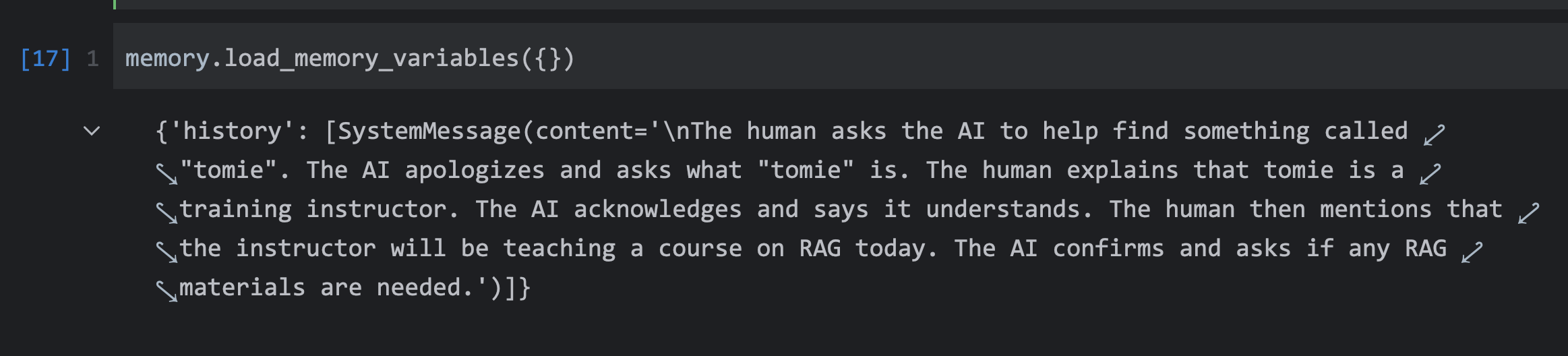
当对话持续进行且对话内容很多时,可用ConversationSummaryBufferMemory来存储对话摘要。
这是一种非常有用的方式,它会根据token的数量来自动判断是否需要进行摘要。
当token数量超过阈值,会自动进行摘要。在缓冲区中,会保留最近的k条对话,比较久的对话会被删除,在删除前会进行摘要。
from langchain.memory import ConversationSummaryBufferMemory
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
memory = ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=10,
return_messages=True
)
memory.save_context(
{"input":"帮我找一下JavaEdge"},
{"output":"对不起请问什么是JavaEdge?"}
)
memory.save_context(
{"input":"JavaEdge是一个培训讲师"},
{"output":"好的,我知道了。"}
)
memory.save_context(
{"input":"今天他要讲一门关于RAG的课程"},
{"output":"好的,我知道了。需要RAG的资料吗?"}
)
memory.load_memory_variables({})
5 使用token来刷新内存缓冲区
关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都架构师,多家大厂后端一线研发经验,在分布式系统设计、数据平台架构和AI应用开发等领域都有丰富实践经验。
各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
- 中央/分销预订系统性能优化
- 活动&券等营销中台建设
- 交易平台及数据中台等架构和开发设计
- 车联网核心平台-物联网连接平台、大数据平台架构设计及优化
- LLM应用开发
目前主攻降低软件复杂性设计、构建高可用系统方向。
参考:
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦