
大家好,我是Python进阶者。
一、前言
前几天在Python白银交流群【空翼】问了一个字符串格式化处理的问题,问题如下:
二、实现过程
这里【东哥】给了一个指导,如下所示:
{word:<10}:这是一个格式化字段,word是变量名,<10是格式化选项。这里<表示左对齐,10表示字段的宽度为10个字符。如果word的字符数少于10,那么它将在右侧填充空格以确保总宽度为10。如果word的字符数超过10,那么它将完整地显示,不会截断。
{count:<5}:这是另一个格式化字段,count是变量名,<5是格式化选项。这里的<5表示字段的宽度为5个字符,如果count的字符数少于5,那么它将在右侧填充空格。如果count的字符数超过5,它将完整地显示,不会截断。
使用Kimi AI问答顺利地解决了粉丝的问题。

不过接下来的经验分享,就是纯经验干货内容了。格式化字符串用的还是蛮多的,但是字符串补齐好像用的少,这里【瑜亮老师】给予了补充,补充了两点字符串补齐的应用场景如下。
【场景一】:在文件名重命名的时候,如果文件名是从1-999这种,在排序的时候因为数字的原因会出问题,一般会补0,把1变成001,这样排序就正常了。
【场景二】:还有就是在办公自动化word数据填充的时候,有时候也会用上字符串补齐。这种补齐主要是为了保证文档不会因为填充进去的字符串长度不同而导致文档样子改变。
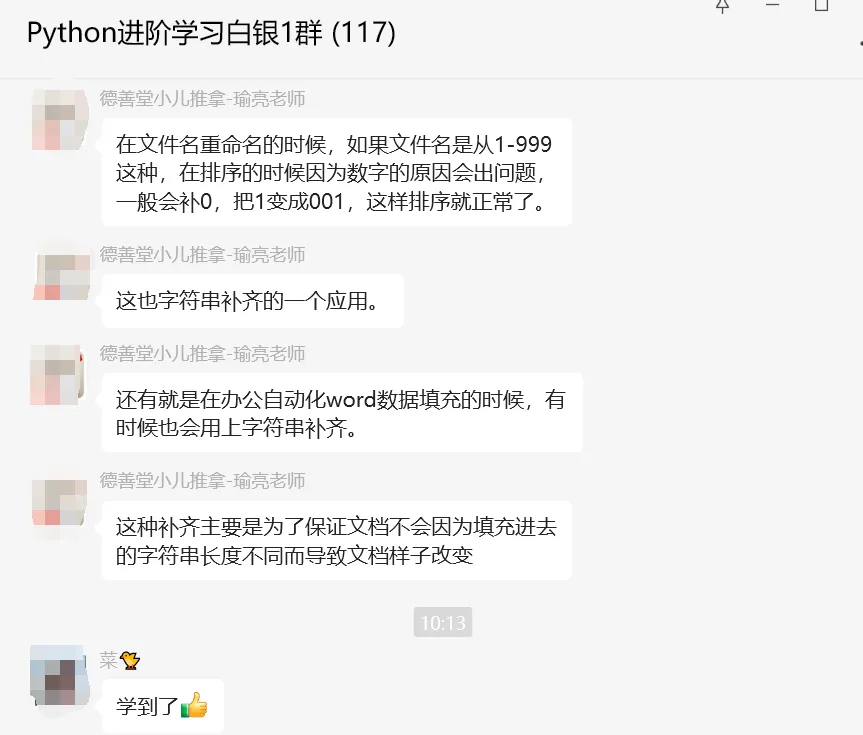
大家收获满满,纷纷表示,学到了[点赞]!
如果你也有类似这种Python相关的小问题,欢迎随时来交流群学习交流哦,有问必答!
三、总结
大家好,我是Python进阶者。这篇文章主要盘点了一个Python字符串格式化处理问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【空翼】提出的问题,感谢【东哥】、【瑜亮老师】给出的思路,感谢【莫生气】、【月神】、【冯诚】、【菜🐤】、【卍Jason卍】、【啥也不懂】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



