
1 Spark 的 local 模式
Spark 运行模式之一,用于在本地机器上单机模拟分布式计算的环境。在 local 模式下,Spark 会使用单个 JVM 进程来模拟分布式集群行为,所有 Spark 组件(如 SparkContext、Executor 等)都运行在同一个 JVM 进程中,不涉及集群间通信,适用本地开发、测试和调试。
1.1 重要特点和使用场景
- 本地开发和测试:在开发 Spark 应用程序时,可以使用 local 模式进行本地开发和测试。这样可以避免连接到集群的开销,加快开发迭代速度。同时,可以模拟集群环境中的作业执行流程,验证代码逻辑和功能。
- 单机数据处理:对于较小规模的数据处理任务,例如处理数百兆或数个 GB 的数据,可以使用 local 模式进行单机数据处理。这样可以充分利用本地机器的资源,快速完成数据处理任务。
- 调试和故障排查:在调试和故障排查过程中,使用 local 模式可以更方便地查看日志、变量和数据,加快发现和解决问题的速度。可以在本地环境中模拟各种情况,验证代码的健壮性和可靠性。
- 教学和学习:对于 Spark 的初学者或教学场景,local 模式提供了一个简单直观的学习环境。学习者可以在本地环境中快速运行 Spark 应用程序,理解 Spark 的基本概念和工作原理。
1.2 使用 local 模式
设置 SparkConf 中的 spark.master 属性为 "local" 来指定运行模式。如Scala中这样设置:
import org.apache.spark.{SparkConf, SparkContext}
object SparkLocalExample {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SparkLocalExample").setMaster("local")
val sc = new SparkContext(conf)
// 在这里编写你的 Spark 应用程序逻辑
sc.stop() // 停止 SparkContext
}
}
1.3 注意
local 模式仅适用于小规模数据处理和本地开发测试场景,并不适用于生产环境的大规模数据处理任务。在生产环境中,需要使用集群模式(如 standalone、YARN、Mesos 等)来运行 Spark 应用程序,以便充分利用集群资源和提高作业的并行度。
2 Spark应用开发
2.1 SparkContext
通常一个 Spark 程序对应一个 SparkContext 实例。SparkContext 是 Spark 应用程序的主入口点,负责与集群进行通信,管理作业的调度和执行,以及维护应用程序的状态。因此,一个 SparkContext 实例通常对应一个独立的 Spark 应用程序。
在正常情况下,创建多个 SparkContext 实例是不推荐的,因为这可能会导致资源冲突、内存泄漏和性能下降等问题。Spark 本身设计为单个应用程序对应一个 SparkContext,以便于有效地管理资源和执行作业。
然而,在某些特殊情况下,可能会存在多个 SparkContext 实例的情况:
- 测试和调试:在测试和调试阶段,有时会创建额外的 SparkContext 实例来模拟不同的场景或测试不同的配置。这样可以更好地理解 Spark 应用程序的行为和性能,以便进行优化和调整。
- 交互式环境:在交互式环境下(如 Spark Shell、Jupyter Notebook 等),有时会创建多个 SparkContext 实例来进行实验、测试或不同的作业执行。这些 SparkContext 实例可能是由不同的用户或会话创建的,用于并行执行不同的任务或查询。
- 多应用程序共享资源:在同一个集群上运行多个独立的 Spark 应用程序,并且它们需要共享同一组集群资源时,可能会创建多个 SparkContext 实例来管理各自的作业和资源。这种情况下,需要确保各个应用程序的 SparkContext 实例能够正确地管理资源,避免资源冲突和竞争。
创建多个 SparkContext 实例时需要谨慎处理,并且需要确保它们能够正确地管理资源、避免冲突,并且不会影响其他应用程序或作业的正常运行。在生产环境中,建议仅使用一个 SparkContext 实例来管理整个应用程序。
SparkContext是Spark应用的入口点,负责初始化Spark应用所需要的环境和数据结构。
2.2 运行一个Spark应用的步骤
- 创建SparkContext,这会初始化Spark应用环境、资源和驱动程序
- 通过SparkContext 创建RDD、DataFrame和Dataset
- 在RDD、DataFrame和Dataset上进行转换和行动操作
- 关闭SparkContext来关闭Spark应用
所以,一个标准的Spark应用对应一个SparkContext实例。通过创建SparkContext来开始我们的程序,在其上执行各种操作,并在结束时关闭该实例。
3 案例
3.1 测试数据文件
input.txt
JavaEdge,JavaEdge,JavaEdge
go,go
scalascala
3.2 代码
package com.javaedge.bigdata.chapter02
import org.apache.spark.{SparkConf, SparkContext}
/**
* 词频统计案例
* 输入:文件
* 需求:统计出文件中每个单词出现的次数
* 1)读每一行数据
* 2)按照分隔符把每一行的数据拆成单词
* 3)每个单词赋上次数为1
* 4)按照单词进行分发,然后统计单词出现的次数
* 5)把结果输出到文件中
* 输出:文件
*/
object SparkWordCountApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
val sc = new SparkContext(sparkConf)
val rdd = sc.textFile("/Users/javaedge/Downloads/sparksql-train/data/input.txt")
rdd.collect().foreach(println)
sc.stop()
}
发现启动后,报错啦:
ERROR SparkContext: Error initializing SparkContext.
org.apache.spark.SparkException: A master URL must be set in your configuration
at org.apache.spark.SparkContext.<init>(SparkContext.scala:368)
at com.javaedge.bigdata.chapter02.SparkWordCountApp$.main(SparkWordCountApp.scala:25)
at com.javaedge.bigdata.chapter02.SparkWordCountApp.main(SparkWordCountApp.scala)
ERROR Utils: Uncaught exception in thread main
必须设置集群?我才刚入门大数据诶,这么麻烦?劝退,不学了!还好 spark 也支持简单部署:
val sparkConf = new SparkConf().setMaster("local")
重启,又报错:
ERROR SparkContext: Error initializing SparkContext.
org.apache.spark.SparkException: An application name must be set in your configuration
at org.apache.spark.SparkContext.<init>(SparkContext.scala:371)
at com.javaedge.bigdata.chapter02.SparkWordCountApp$.main(SparkWordCountApp.scala:25)
at com.javaedge.bigdata.chapter02.SparkWordCountApp.main(SparkWordCountApp.scala)
ERROR Utils: Uncaught exception in thread main
val sparkConf = new SparkConf().setMaster("local").setAppName("SparkWordCountApp")
成功了!

val rdd = sc.textFile("/Users/javaedge/Downloads/sparksql-train/data/input.txt")
rdd.flatMap(_.split(","))
.map(word => (word, 1)).collect().foreach(println)
sc.stop()
output:
(pk,1)
(pk,1)
(pk,1)
(jepson,1)
(jepson,1)
(xingxing,1)
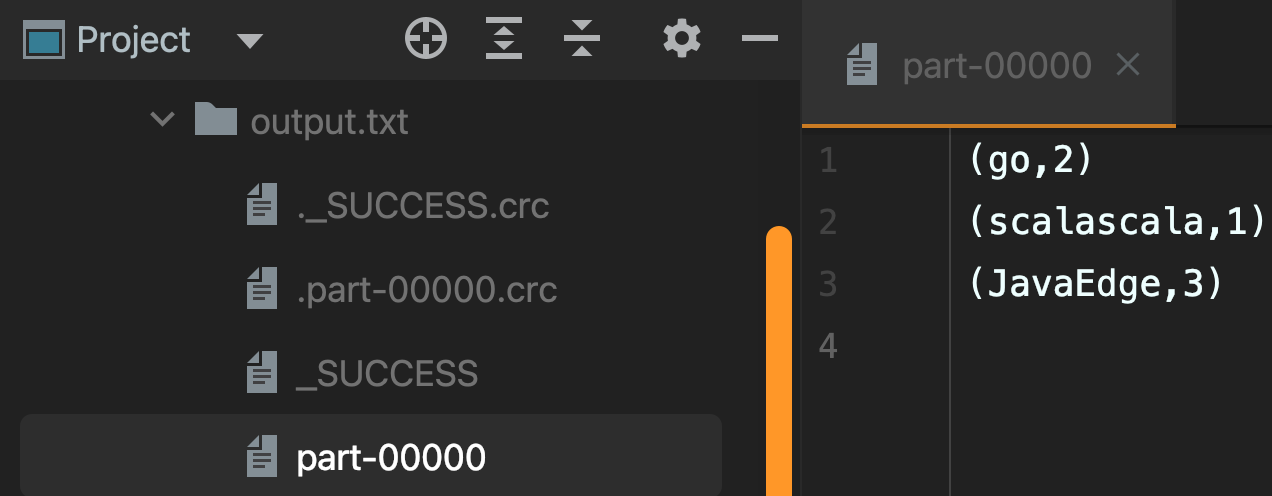
3.3 输出到文件
rdd.flatMap(_.split(","))
// 3)每个单词赋上次数为1
.map(word => (word, 1))
.reduceByKey(_ + _)
.saveAsTextFile("/Users/javaedge/Downloads/sparksql-train/data/output.txt")
3.4 按频率降序排
// 2)按照分隔符把每一行的数据拆成单词
rdd.flatMap(_.split(","))
// 3)每个单词赋上次数为1
.map(word => (word, 1))
// 4)按照单词进行分发,然后统计单词出现的次数
.reduceByKey(_ + _)
// 结果按单词频率降序排列,既然之前是 <单词,频率> 且 sortKey 只能按 key 排序,那就在这里反转 kv 顺序
.map(x => (x._2, x._1))
.collect().foreach(println)
output:
(2,go)
(1,scalascala)
(3,JavaEdge)
显然结果不符合期望。如何调整呢?再翻转一次!
rdd.flatMap(_.split(","))
.map(word => (word, 1))
.reduceByKey(_ + _)
// 结果按单词频率降序排列,既然之前是 <单词,频率> 且 sortKey 只能按 key 排序,那就在这里反转 kv 顺序
.map(x => (x._2, x._1))
.sortByKey(false)
.map(x => (x._2, x._1))
.collect().foreach(println)
output:
(JavaEdge,3)
(go,2)
(scalascala,1)
4 spark-shell启动
javaedge@JavaEdgedeMac-mini bin % ./spark-shell --master local
23/03/23 16:28:58 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://172.16.1.55:4040
Spark context available as 'sc' (master = local, app id = local-1679560146321).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_362)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
4 通过YARN提交任务
$ ./spark-submit --master yarn \
--deploy-mode client \
--class <main_class> \
--num-executors <num_executors> \
--executor-memory <executor_memory> \
--executor-cores <executor_cores> \
<path_to_jar_or_py_file> \
<app_arguments>
各参数含义:
--master yarn: 指定使用YARN作为Spark的资源管理器。--deploy-mode client: 指定部署模式为client模式,即Driver程序运行在提交Spark任务的客户端机器上。--class <main_class>: 指定Spark应用程序的主类。--num-executors <num_executors>: 指定执行器的数量。--executor-memory <executor_memory>: 指定每个执行器的内存大小。--executor-cores <executor_cores>: 指定每个执行器的核心数。<path_to_jar_or_py_file>: 指定要提交的Spark应用程序的JAR文件或Python文件的路径。<app_arguments>: 指定Spark应用程序的参数。
如提交一个Scala版本的Spark应用程序的命令:
$ ./spark-submit --master yarn \
--deploy-mode client \
--class com.example.MySparkApp \
--num-executors 4 \
--executor-memory 2G \
--executor-cores 2 \
/path/to/my-spark-app.jar \
arg1 arg2 arg3
如果你要提交一个Python版本的Spark应用程序,可以使用以下命令:
$ ./spark-submit --master yarn \
--deploy-mode client \
/path/to/my-spark-app.py \
arg1 arg2 arg3
这样就可以通过YARN提交Spark任务,Spark会向YARN请求资源并在集群上执行任务。
关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都技术专家兼架构,多家大厂后端一线研发经验,各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
- 中央/分销预订系统性能优化
- 活动&优惠券等营销中台建设
- 交易平台及数据中台等架构和开发设计
- 车联网核心平台-物联网连接平台、大数据平台架构设计及优化
目前主攻降低软件复杂性设计、构建高可用系统方向。
参考:
共同学习,写下你的评论
评论加载中...
作者其他优质文章



