
本章中分析tf的核心概念在内核中的实现。
Tensor(张量)
Tensor是tf对数据的抽象,具有一定的维度、数据类型和数据内容。
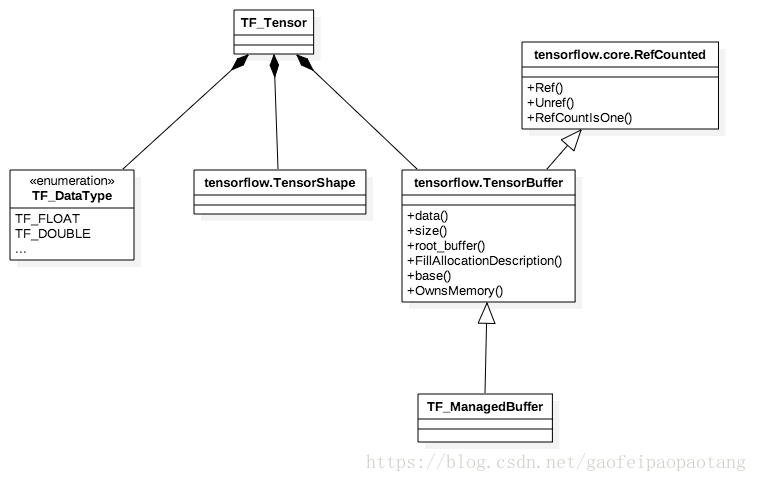
图1是C API中对Tensor的封装,Tensor的纬度、数据类型、数据内容都有对应的成员表示。数据内容存放在TensorBuffer中,这个类支持引用计数,在引用数为0的时候则自动释放内存。
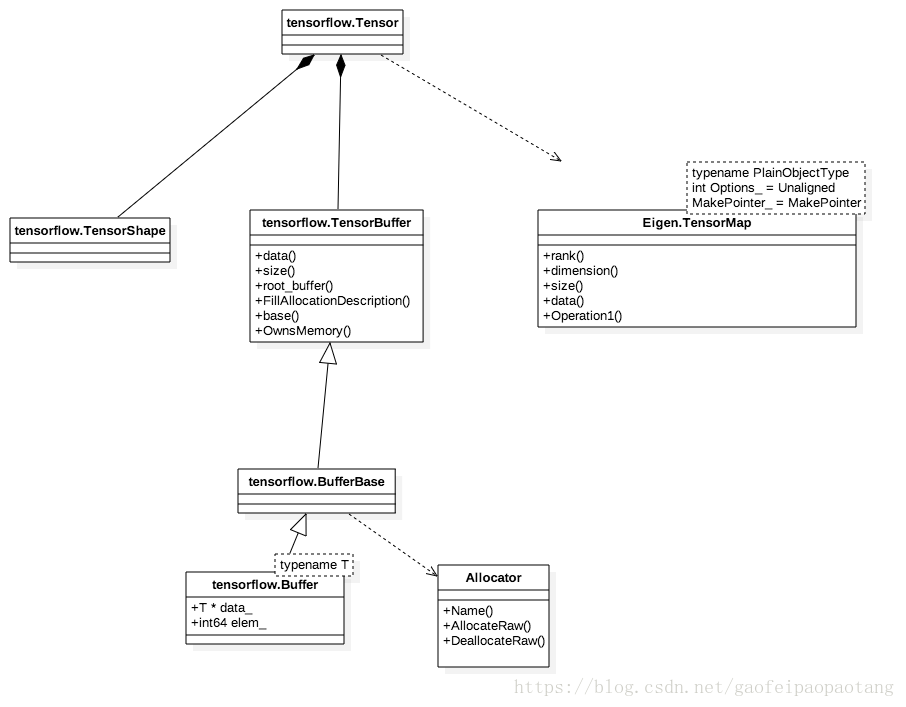
以上是接口层对Tensor的封装,比较简单直接,适合接口中传递参数使用,但是在tf的内核中,Tensor的封装是tensorflow.Tensor,它的设计目标之一是为了能方便的使用线性代数运算库Eigen,另外TensorBuffer的具体实现类也不一样:
Op(运算)
TensorFlow中Op代表一个基本运算,比如矩阵或则标量的四则运算。
| 运算类型 | 运算名称 |
|---|---|
| 标量运算 | Add,Sub,Mul,Div,Exp,Log,Greater,Less,Equal |
| 向量运算 | Concat,Slice,Split,Constant,Rank,Shape,Shuffle |
| 矩阵运算 | MatMul,MatrixInverse,MatrixDeterminant |
| 带状态的运算 | Variable,Assign,AssignAdd |
| 神经网络组件 | SoftMax,Sigmoid,ReLU,Convolution2D,MaxPooling |
| 存储、恢复 | Save,Restore |
| 队列和同步 | Enqueue,Dequeue,MutexAcquire,MutexRelease |
| 控制流 | Merge,Switch,Enter,Leave,NextIteration |
运算的定义OpDef的定义:
/* tensorflow/core/framework/op_def.proto */...message OpDef {
//运算名称,采用驼峰命名法,下划线开头的名称为保留名称
string name = 1;
//运算的输入
repeated ArgDef input_arg = 2;
//运算的输出
repeated ArgDef output_arg = 3;
//运算的属性
repeated AttrDef attr = 4;
//面向用户的运算描述
string description = 6; ...}运算定义主要有名称、属性、输入参数、输出参数。开发者通过宏REGISTER_OP来注册支持的运算:
REGISTER_OP("Concat")
.Input("concat_dim: int32")
.Input("values: N * T")
.Output("output: T")
.Attr("N: int >= 2")
.Attr("T: type")
.SetShapeFn([](InferenceContext* c) { return shape_inference::ConcatShape(c, c->num_inputs() - 1);
})
.Doc(R"doc(
Concatenates tensors along one dimension.
...
)doc");以上这段代码注册了Concat运算,Concat运算有两个输入:concat_dim,数据类型为int32,另一个values,N * T的矩阵。还声明了两个属性,这些属性必须被预算设置,或则能在计算图被创建的时候推断出来。另外还提供了Shape的推断函数和运算说明文档。
REGISTER_OP的实际工作是构造好OpDef对象,并将自己注册到一个注册中心,在未来我们构建计算图的时候,我们就可以调用查找方法来找到想要的运算定义:
// Example LookUp: OpRegistry::Global()->LookUp(op_name, op_def_data);
问题:细心的读者可能发现了一个问题,那就是在我们的运算的定义中,没有定义运算的实现逻辑;然后在注册运算的时候,也没有提供任何运算实现的函数,这是为什么呢?毕竟,我们运算存在的目的是要在需要的时候执行运算,没有运算的实现,我们执行什么呢?
答案是,在tf的设计中,运算和运算实现是两个分开的概念,通过引入的运算核(OpKernel)的概念来表示运算的具体实现。这么设计的原因是,运算的语义是平台不相关的,是不变的,而运算的实现运算核是跟具体的平台(CPU、GPU、TPU)相关的。这样,就可以很方便的对语义不变的运算提供不同平台的实现了。tf中的运算核也有注册机制,为一个运算提供多平台的实现:
/* tensorflow/core/kernels/conscat_op.cc */...REGISTER_KERNEL_BUILDER(Name("Concat") \
.Device(DEVICE_CPU) \
.TypeConstraint<type>("T") \
.HostMemory("concat_dim"), \
ConcatOp<CPUDevice, type>)...REGISTER_KERNEL_BUILDER(Name("Concat")
.Device(DEVICE_GPU)
.TypeConstraint<int32>("T")
.HostMemory("concat_dim")
.HostMemory("values")
.HostMemory("output"),
ConcatOp<CPUDevice, int32>);...以上的这段代码,就为Concat运算注册了两个运算核,分别对应DEVICE_CPU和DEVICE_GPU,运算核的实现代码就在模板类ConcatOp中。
Node(节点)
Node是计算图的基本单位,可以为它绑定特定的运算,指定特定的设备(不指定的话,则服从默认的设备分配策略),指定输入节点等等:
/* tensorflow/core/framework/node_def */message NodeDef { // 节点名,计算图范围内唯一,添加重名节点会报错
string name = 1; // 节点绑定的运算名称
string op = 2; // 节点的输入,格式为"node:src_output_index",表示节点node的
// 第src_output_index输出。src_output_index == 0,则可以表
// 示为"node"
repeated string input = 3; //节点绑定的设备
string device = 4; //节点属性
map<string, AttrValue> attr = 5;
}可以看到,Node的定义中,包括名称,输入来源,运算名,设备以及属性。另外,在执行Node的运算前,需要通过设备类型和运算名找到相应的运算核(OpKenel)。
设备的指定格式如下:
/* tensorflow/core/framework/node_def.proto */
...
// DEVICE_SPEC ::= PARTIAL_SPEC
//
// PARTIAL_SPEC ::= ("/" CONSTRAINT) *
// CONSTRAINT ::= ("job:" JOB_NAME)
// | ("replica:" [1-9][0-9]*)
// | ("task:" [1-9][0-9]*)
// | ( ("gpu" | "cpu") ":" ([1-9][0-9]* | "*") )
//
// Valid values for this string include:
// * "/job:worker/replica:0/task:1/gpu:3" (full specification)
// * "/job:worker/gpu:3" (partial specification)
// * "" (no specification)
...Graph(计算图)
我们来通过一段例子代码,分析一下Graph的创建过程,代码中我们没有调用Python API,而是调用了C API:
... ...TF_Status* s = TF_NewStatus(); TF_Graph* graph = TF_NewGraph(); TF_Operation* feed = Placeholder(graph, s); TF_Operation* three = ScalarConst(3, graph, s); TF_Operation* add = Add(feed, three, graph, s); TF_Operation* neg = Neg(add, graph, s); // Clean up TF_DeleteGraph(graph); TF_DeleteStatus(s);... ...
Python API是对C API的封装,当然在Python这层也实现了很多tf的功能,这个后面的章节再来分析。这里调用C API的原因是,这层的API更直接,这对于我们分析计算图创建过程比较合适。
以上代码中的四个函数,Placeholder,ScalarConst,ADD, Neg是对TF_NewOperation的简单封装,作用是创建相对应的Node,以ADD函数为例:
/* tensorflow/c/c_api_test.cc */...TF_Operation* Add(TF_Operation* l, TF_Operation* r, TF_Graph* graph,
TF_Status* s, const char* name = "add") {
TF_OperationDescription* desc = TF_NewOperation(graph, "AddN", name);
TF_Output add_inputs[2] = {{l, 0}, {r, 0}};
TF_AddInputList(desc, add_inputs, 2); return TF_FinishOperation(desc, s);
}...ADD函数的作用就是在graph中,添加一个ADDN运算的节点,输入是节点 l 的第0个输出和节点 r 的第0个输出。
还要注意一个容易混淆的地方,API中的Operation概念其实是内核中的Node概念,并非内核中Op(运算)的概念。
回到上面的例子代码,功能很简单,生成一个graph并添加了四个节点,最后计算图的结构为:
--- |Neg| --- | --- |Add| --- / \ ---- ------|fead| |Scalar| ---- ------
下面来看一下这个过程背后的的实现是怎样的:
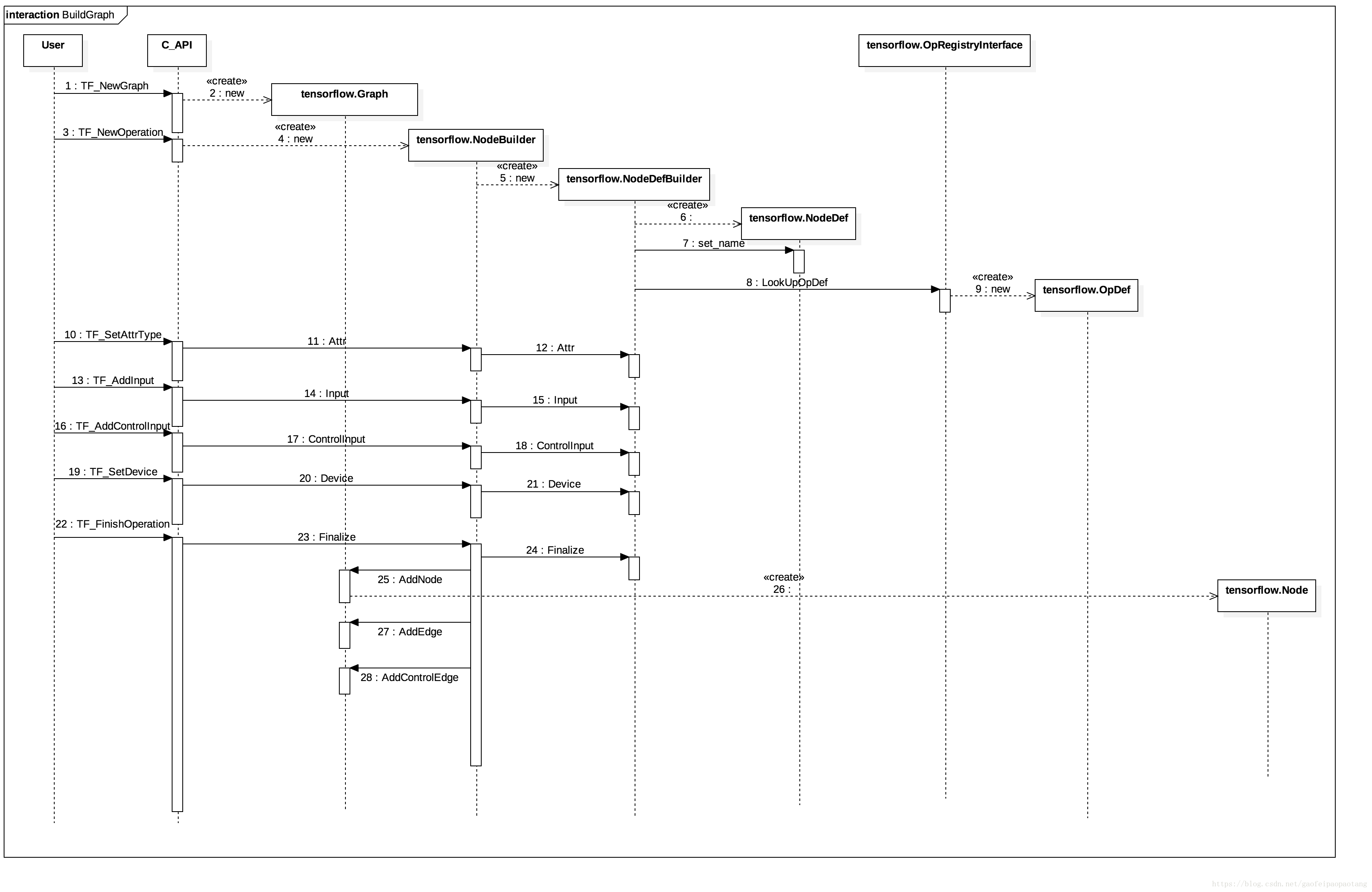
第一步、 TF_NewGraph会创建一个tensorflow.Graph对象,这就是计算图在TF内核中的表示;TF_NewGraph返回的结果是TF_Graph的指针,这个结构体是C API层对tensorflow.Graph的封装对象。
第二步、 TF_NewOperation创建Graph中的Node,这一步中涉及的类比较多,tensorflow.NodeBuilder,tensorflow.NodeDefBuilder是为了构建tensorflow.NodeDef的工具类;为了最终构建Node对象,还需要通过tensorflow.OpRegistryInterface来找到Node绑定的OpDef。就像前面说的,Op是通过注册来提供给tf使用的。
细心的用户发现,其实这步并没有创建Node对象,为什么呢?我们先往后看。
第三步、设置Node的输入,设备以及属性,如图1中调用10到22。
**最后,**TF_FinishOperation创建Node对象,并添加到Graph中。我们看到,实际的Node对象的创建是到这一步才发生的(调用26),并且根据节点的输入和控制输入,添加所需的数据边和流控制边。这也是为什么Node对象的创建放在最后一步的原因。
session(会话)
tf是通过session接口来驱动计算图的运算的,数据从输入节点输入,沿着计算图的有向边流经图中的其他节点,参与节点的运算,直到到达输出节点为止。
执行过程具体又分为本地执行和服务端执行,首先看一下本地执行:
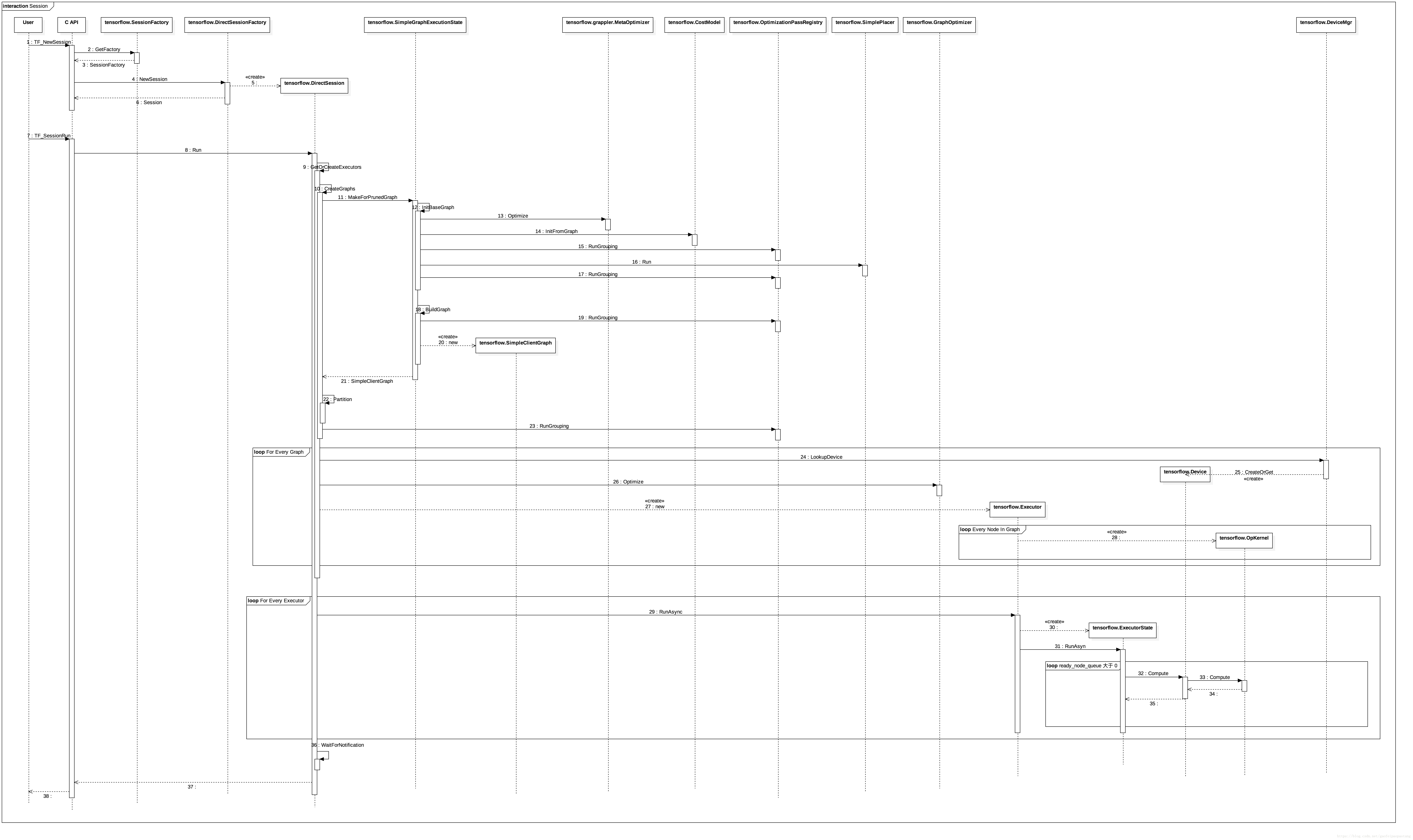
本地执行的步骤如下:
第一步、图4中的1-6,创建session对象;根据Option的设置,返回具体的session实现类,设置本地执行后,返回的session对象的实现类是tensorflow.DirectSession.
第二步、执行计算图;这个过程比较关键,tf很多的优化技术都在这里。TF_SessionRun直接调用tensorflow.DirectSession.Run,此函数大致可以分为两个阶段:准备执行阶段和执行阶段。
1,准备执行阶段逻辑主要在函数tensorflow.DirectSession.GetOrCreateExecutor内,函数首先会调用函数tensorflow.DirectSession.CreateGraphs,然后为新生成的多张计算图分别创建各自的Executor(图4中的Loop for every graph)。
那么问题来了,创建session的时候,已经关联了一个graph,为什么要重新创建?甚至,重新创建的了多张图,这是为什么?简而言之,目的是为了分配设备和优化执行效率。这里的逻辑在tensorflow.DirectSession.CreateGraphs中。创建session时候关联的graph不适合直接进行计算,需要做的准备还很多,包括设备分配,裁剪,各种优化。
设备分配相关的类是tensorflow.CostModel和tensorflow.SimplePlacer,具体调用tensorflow.SimplePlacer.Run进行设备分配(图4中的16)。这里会根据一些启发式的经验规则加上一些通过实际运算收集的数据进行设备分配。
tf中的各种效率优化是分阶段多次执行的,在设备分配前、设备分配之后、计算图执行之前、计算图分区之前等,都有优化逻辑存在,涉及tensorflow.grappler.MetaOptimizer,tensorflow.OptimizationPassRegitry,tensorflow.GraphOptimizer等类,相关的类如下:
优化是个比较大主题,篇幅限制,本章中暂不展开介绍了,后面章节再讨论。
回归我们的讨论,在这些处理之后,调用Parition的进行计算图的分区操作,将重建的已经分配过设备和优化过的计算图进行分区。所谓分区的主要依据就是执行设备,同一个设备上的节点在一个分区。
在准备阶段的后半部分,需要为每一个分区的计算图创建独立的Executor(图4 Loop for every graph),目的是为了提高并发效率; 这部分逻辑还负责为分区计算图创建设备对象;另外,细心的用户还会发现,分区计算图中的每个节点的运算核也是在这时候创建的(图4 loop for evey node in graph)。
到此,每个分区计算图已经准备完毕,可以执行了。
2,执行阶段,并发调用每个Executor的异步执行方法tensorflow.Executor.RunAsync方法。RunAsync将当前计算图中输入依赖为0的节点放入ready_node_queue中,每次从ready_node_queue中取下一个待执行的节点执行,并在执行完成后,将它的下游节点的输入依赖减一,如此循环,直到ready_node_queue空为止(图4 loop ready_node_queue大于0)。
这里还需要提醒一点的是,每张分区计算图的执行并非完全独立的,也会发生等待的事件,因为分区间也存在输入依赖的问题。tf中通过在分区图间引入send/recv节点的方式解决这个问题。第一章中我们已经介绍过这个设计。
最后调用WaitForNotification等待计算图执行完成,提出执行结果。

相比本地执行,服务端执行流程看起来比较简单,这是因为我们隐去了服务端的逻辑,只画了客户端的逻辑。我会在后面单独的章节中介绍tf的分布式执行架构,这里暂不展开讨论服务端的情况。
在配置了服务端执行后,创建的session对象的具体实现类是GrpcSession,它通过一个gprc的通信类与服务端通信。
总结
本章中介绍了tf核心概念在内核中的实现,包括Tensor,Op,Node,Graph。然后介绍了session驱动计算的内核实现。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



