
- MultiStepLR 在论文中较多使用,因为它的使用相对简单并且可控。
- ReduceLROnPlateau自动化程度高,参数多。
1. 使用lr_scheduler接口实现MultiStepLR
- MultiStepLR的使用方式和使用lr_scheduler接口实现退化学习率的StepLR使用方式非常相似。
- 以下是构建神经网络结构的部分
import torch.nn as nn
import torch
import numpy as np
import matplotlib.pyplot as plt
# 继承nn.Module类,构建网络模型
class LogicNet(nn.Module):
def __init__(self, inputdim, hiddendim, outputdim): # 初始化网络结构
super(LogicNet, self).__init__()
self.Liner1 = nn.Linear(inputdim, hiddendim) # 定义全连接层
self.Liner2 = nn.Linear(hiddendim, outputdim) # 定义全连接层
self.criterion = nn.CrossEntropyLoss() # 定义交叉熵函数, 一定要加上括号,不可以直接写。
def forward(self, x): # 搭建用两个全连接层构建的网络模型
x = self.Liner1(x) # 将输入数据传入第1个全连接层
x = torch.tanh(x) # 对第一个连接层的结果进行非线性变换,使用激活函数tanh实现
x = self.Liner2(x) # 将网络数据传入第2个链接层
return x
def predict(self, x): # 实现LogicNet类的预测接口
# 调用自身网络模型,并对结果进行softmax处理,分别得出预测数据属于每一类的概率
pred = torch.softmax(self.forward(x), dim=1)
return torch.argmax(pred, dim=1) # 返回每组预测概率中最大值的索引
def getloss(self, x, y): # 实现LogicNet类的损失值接口
y_pred = self.forward(x)
loss = self.criterion(y_pred, y) # 计算损失值的交叉熵
return loss
- 以下是使用lr_scheduler接口实现MultiStepLR
import sklearn.datasets # 数据集
import torch
import numpy as np
import matplotlib.pyplot as plt
from code_04_moons import LogicNet
X, Y = sklearn.datasets.make_moons(20, noise=0.2) # 生成两组半圆形数据
model = LogicNet(inputdim=2, hiddendim=3, outputdim=2) # 实例化模型
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 定义Adam优化器
xt = torch.from_numpy(X).type(torch.FloatTensor) # 将numpy数据转化为张量
yt = torch.from_numpy(Y).type(torch.LongTensor)
epochs = 1000 # 定义迭代次数
losses = [] # 定义列表,用于接收每一步的损失值
lr_list = [] # 定义列表,用于接收每一步的学习率
# 设置退化学习率,每50步乘以0.99
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[200, 700, 800], gamma=0.9)
for i in range(epochs):
loss = model.getloss(xt, yt)
losses.append(loss.item()) # 保存中间状态的损失值
optimizer.zero_grad() # 清空之前的梯度
loss.backward() # 反向传播损失值
optimizer.step() # 更新参数
scheduler.step() # 调用退化学习率对象
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(epochs), lr_list, color='r') # 输出学习率的可视化结果
plt.show()
运行结果: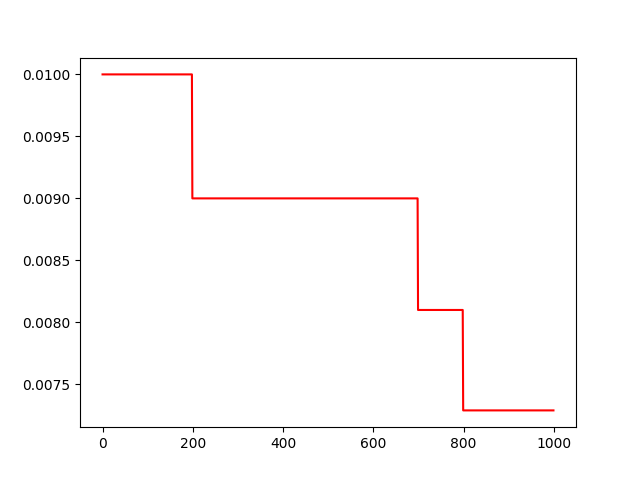
- 上述代码使用lr_scheduler接口的MultiStepLR类实例化了一个退化学习率对象。
- 在实例化过程中,向参数milestones中传入了列表[200, 700, 800],该列表代表模型训练到200、700、800步时,对学习率进行退化操作。
2.使用lr_scheduler接口实现ReduceLROnPlateau
- ReduceLROnPlateau的参数较多,自动化程度较高。
- 在实例化之后,还要在使用时传入当前的模型指标,所需要的模型指标可以参考以下代码。
- 我们依然保持神经网络结构不变
import torch.nn as nn
import torch
import numpy as np
import matplotlib.pyplot as plt
# 继承nn.Module类,构建网络模型
class LogicNet(nn.Module):
def __init__(self, inputdim, hiddendim, outputdim): # 初始化网络结构
super(LogicNet, self).__init__()
self.Liner1 = nn.Linear(inputdim, hiddendim) # 定义全连接层
self.Liner2 = nn.Linear(hiddendim, outputdim) # 定义全连接层
self.criterion = nn.CrossEntropyLoss() # 定义交叉熵函数, 一定要加上括号,不可以直接写。
def forward(self, x): # 搭建用两个全连接层构建的网络模型
x = self.Liner1(x) # 将输入数据传入第1个全连接层
x = torch.tanh(x) # 对第一个连接层的结果进行非线性变换,使用激活函数tanh实现
x = self.Liner2(x) # 将网络数据传入第2个链接层
return x
def predict(self, x): # 实现LogicNet类的预测接口
# 调用自身网络模型,并对结果进行softmax处理,分别得出预测数据属于每一类的概率
pred = torch.softmax(self.forward(x), dim=1)
return torch.argmax(pred, dim=1) # 返回每组预测概率中最大值的索引
def getloss(self, x, y): # 实现LogicNet类的损失值接口
y_pred = self.forward(x)
loss = self.criterion(y_pred, y) # 计算损失值的交叉熵
return loss
- 使用lr_scheduler接口的ReduceLROnPlateau类实例化了一个退化学习率对象。代码如下所示:
import sklearn.datasets # 数据集
import torch
import numpy as np
import matplotlib.pyplot as plt
from code_04_moons import LogicNet
X, Y = sklearn.datasets.make_moons(20, noise=0.2) # 生成两组半圆形数据
model = LogicNet(inputdim=2, hiddendim=3, outputdim=2) # 实例化模型
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 定义Adam优化器
xt = torch.from_numpy(X).type(torch.FloatTensor) # 将numpy数据转化为张量
yt = torch.from_numpy(Y).type(torch.LongTensor)
epochs = 1000 # 定义迭代次数
losses = [] # 定义列表,用于接收每一步的损失值
lr_list = [] # 定义列表,用于接收每一步的学习率
# 设置退化学习率,每50步乘以0.99
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer,
mode='min', # 要监控模型的最大值max还是最小值min
factor=0.5, # 退化学习率参数gamma
patience=5, # 不再减小(或增加)的累计次数
verbose=True, # 出发规则时是否打印信息
threshold=0.0001, # 监控值出发规则的阈值
threshold_mode='abs', # 计算触发规则的方法
cooldown=0, # 触发规则后的停止监控步数,避免lr下降过快
min_lr=0, # 允许的最小退化学习率
eps=1e-08 # 当退化学习率的调整幅度小于该值的时候,停止调整
)
for i in range(epochs):
loss = model.getloss(xt, yt)
losses.append(loss.item()) # 保存中间状态的损失值
scheduler.step(loss.item()) # 调用退化学习率对象
optimizer.zero_grad() # 清空之前的梯度
loss.backward() # 反向传播损失值
optimizer.step() # 更新参数
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(epochs), lr_list, color='r') # 输出学习率的可视化结果
plt.show()
运行结果: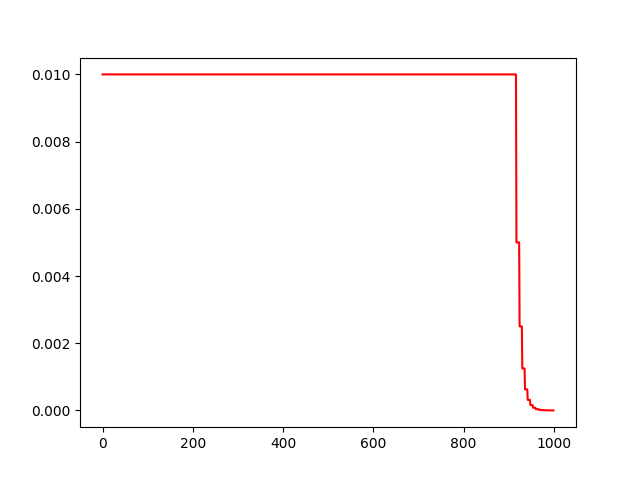
- 参数threshold_mode有两种取值,具体如下:
- rel:参数mode为max时,如果监控值超过best(1+threshold),则出发规则;
在参数为min时,如果监控值低于best(1-threshold),则触发规则(best为训练过程中的历史最好值) - abs:在参数mode为max时,如果监控值超过best+threshold,则触发规则;
参数mode为min时,如果监控值低于best-threshold,则触发规则
在调用退化学习率对象时,需要向其传入被监控的值,否则代码会运行出错。
如:scheduler.step(loss.item())
- rel:参数mode为max时,如果监控值超过best(1+threshold),则出发规则;
- 当然我们可以在最终的退化学习率的变化曲线中得到,经过参数配置后的ReduceLROnPlateau可以让模型在训练后期用更小的学习率去提升精度。
- 由于上述例子中使用的退化学习率的网络模型过于简单,每次模型的初始值权重也不同,因此会导致不同机器上运行的效果不同。
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦