
大家好,我是皮皮。
一、前言
前几天在Python白银交流群【上海新年人】问了一个Pandas数据提取的问题,上一篇文章我们介绍了基础篇,这一篇文章我们来延伸下,你想象下,我想要14和15行该怎么写?
二、实现过程
后来【论草莓如何成为冻干莓】给了一份代码,print(df.loc[[14, 15],'作者':'回复'])。继续延伸下,如下图所示:
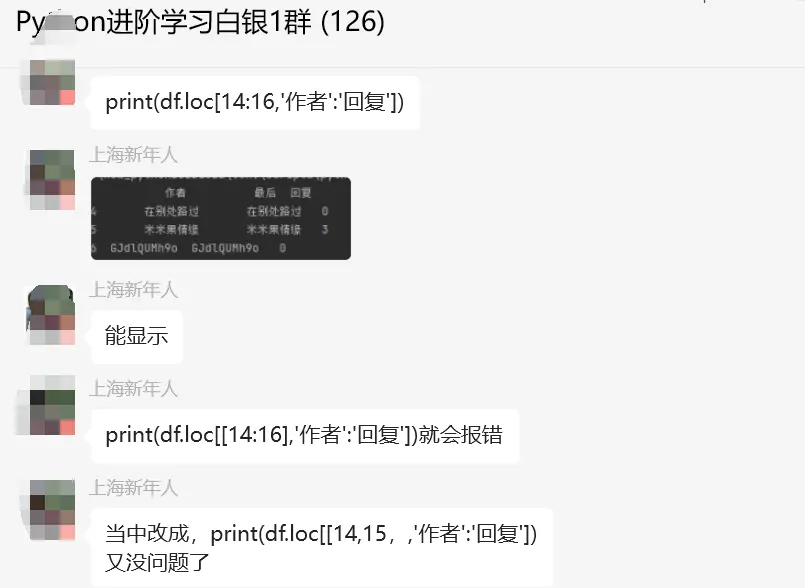
那么此时该怎么来理解呢?
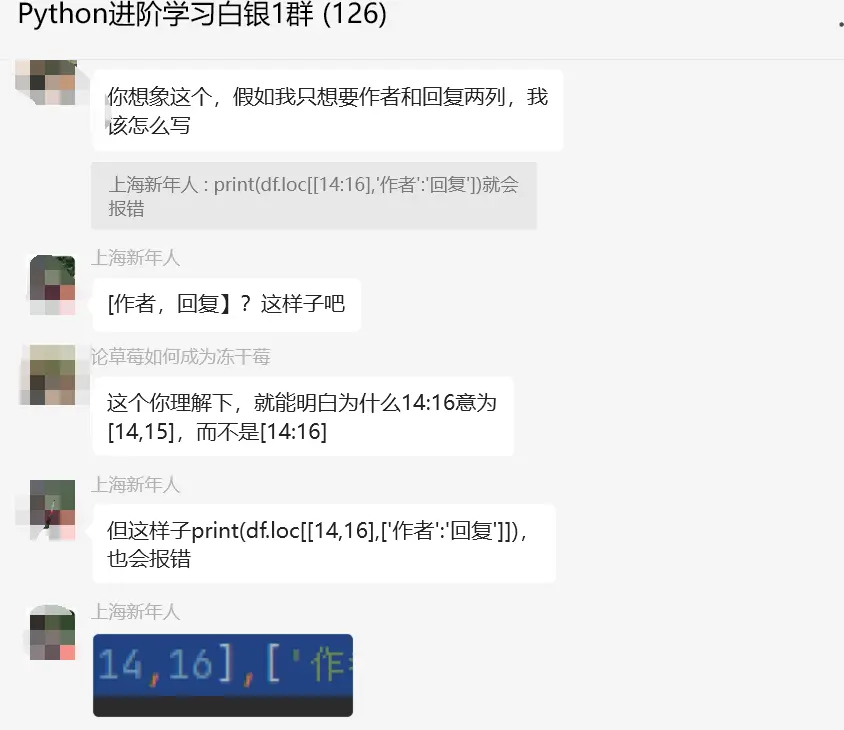
这里【瑜亮老师】指出:[14:16] == [[14,15,16]] != [14,15,16]。

一个是不用加框,返回的是pd.Series对象,你想返回pd.DataFrame对象就得加框,无论是一个还是两个,返回的对象不一样,你使用的索引方法就是不一样的。这个原理得明白,就像为什么字典查找元素跟列表查找元素的方式为什么不一样。
后来【瑜亮老师】给了一个非常细心的解答。如下:
14 方式正确,出来是竖着的Series,1列
[14] 方式正确,出来是横着的DataFrame,1行
[14,16] 方式正确,出来是横着的DataFrame,2行
14:16 方式正确,出来是横着的DataFrame,3行
[14,15,16] 方式正确,出来是横着的DataFrame,3行
[[14,15,16]] 方式错误
[14:16] 方式错误
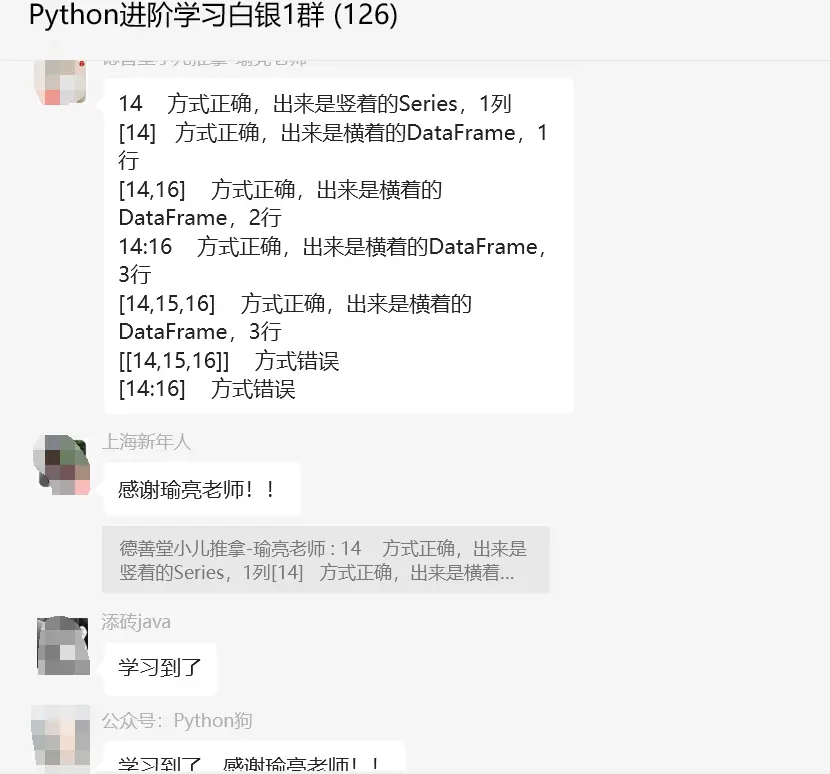
[14,16]是列表,中间用逗号,表示里面有2个元素 14:16用的是冒号,意思是从14到16(包含16),总共是3个元素,等同于[14,15,16]
确实学习到了,顺利地解决了粉丝的问题。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Pandas数据提取的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【上海新年人】提出的问题,感谢【论草莓如何成为冻干莓】、【瑜亮老师】给出的思路,感谢【莫生气】、【王者级混子】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

共同学习,写下你的评论
评论加载中...
作者其他优质文章



