
废话不多说,直接上代码:
package main
func main() {
var x int
println(&x)
getArrValue(1)
println(&x)
}
// getArrValue下面go:noinline这行注释防止函数发生内联
//go:noinline
func getArrValue(i int) int {
var a [1 << 20]int // 使栈增长
return a[i]
}
问题:上面代码中两次输出的变量x的地址是一样的吗?
大家可以先自己执行一下上面的代码
笔者的Go版本和执行结果如下:
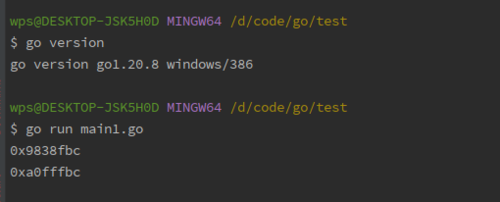
为什么一个int类型的变量x在执行了一个跟这个变量毫无关联的函数之后,它的地址就发生改变了呢?
要搞清楚这个问题就必须搞清楚Go语言中的值在内存块上的布局了。
我们知道Go语言是一门支持自动内存管理的语言。内存的开辟和垃圾回收都可以通过Go语言自身实现,这就给Go语言的开发者们节省了很多的开发时间,也可以避免由于粗心大意导致的一些bug,代码也会更简洁。
尽管Go语言为我们封装了很多细节,我们无需关心底层的内存管理的实现,但知道其中的一些概念和事实是有助于我们写出高质量代码的。
Go可以被看作是一门C语言血统的语言,也可以说是C语言的一个扩展框架。在C语言中内存管理是很透明的,每个值在内存中只占据着一个内存块。而一些Go类型的值却可能占据着多个内存块。
怎么理解这里的内存块呢?
所谓内存块就是一段在运行时刻承载着若干值部的连续内存片段。而所谓的值部,也就是存储Go语言各种类型值的部分,具体来说,就是一个Go值在不同内存块上的部分。我们在前面小节中讲到的直接值部和间接值部都可以称为值部。
一个内存块可承载的值部可能不止一个,比如一个结构体可能会有多个字段,所以为结构体的值开辟一个内存块时,这个内存块同时也会承载这个结构体值的各个字段值。
什么时候会开辟内存块呢?
-
变量声明时;
声明变量的方式有很多,比如有调用new和make内置函数,需要注意的是new函数只会开辟一个内存块,而make函数可能会开辟多个内存块来承载创建的切片,映射或者通道的值或者指针。或者使用字面量创建建映射、切片或函数值时,会开辟一个或多个内存块。或者使用字面量创建建映射、切片或函数值时,会开辟一个或多个内存块。 或者使用字面量创建建映射、切片或函数值时,会开辟一个或多个内存块。
比如:
a := make([]int, 10) //使用make声明
a := []int{} //使用字面量声明
a := 1 //普通变量声明
-
字符串转字节切片或字节切片转字符串
-
将一个整数转换为字符串
-
调用内置append函数触发切片扩容时
-
向一个map中添加键值对,并且map底层内部的哈希表需要改变容量时。
-
声明变量的方式有很多,比如有调用new和make内置函数,需要注意的是new函数只会开辟一个内存块,而make函数可能会开辟多个内存块来承载创建的切片,映射或者通道的值或者指针。
内存块在哪里开辟? 当Go程序运行时,每个协程会维护一个栈,而这个栈本质上是一个预申请的内存段,它作为一个内存池以供内存块从这些内存段中开辟内存。在Go编译器1.19版本之前,一个栈的初始尺寸总是2KiB。 从1.19版本开始,栈的初始尺寸是自适应的。每个栈的尺寸在协程运行时按需扩容或者缩容,栈的最小尺寸为2KiB。
需要注意的是,Go运行时协程栈的尺寸是有最大限制的,目前的官方标准Go工具链1.20版本中,64位操作系统上限制为1GB,32位操作系统上限制为250MB。我们可以使用_runtime/debug标准库包中的SetMaxStack_来修改这个限制值。值得注意的是,这个值在官方标准编译器中是需要满足2的幂,而GB,MB的单位以10为底数的指数,即1MB=1000KB,而1MiB=210=1024KiB。所以对于默认设置1GB,首先会计算这个1GB转成字节是不是2的多少次方,显然没有符合的,所以这里就取了最接近的29=512MiB。所以实际上允许的协程栈的最大尺寸在64位系统上为512MiB,在32位系统上为128MiB。
开辟在一个协程栈上的内存块只能在此协程的内部被使用与其他协程是隔离的,也就是说一个协程栈内部的内存块是并发安全的。
内存块可以被开辟在栈(stack)上,也可以被开辟在堆(heap)上。如果一个内存块没有开辟在任何一个栈上,那么它就开辟在堆上。堆其实是一个虚拟的概念,每个程序只有一个堆。堆上的内存块可以被多个协程同时访问,需要考虑并发安全的问题。
什么情况下内存块会被开辟在堆上,什么情况下会被开辟到栈上呢?
内存块会开辟的位置是由编译器来决定的。 如果编译器不能确定这个内存块只会被一个协程访问,则这个内存块就会被开辟在堆上。也就是说编译器会采取保守但安全的策略,会让一些可以安全的开辟在栈上的内存块开辟到了堆上。实际上栈是非必要的,Go程序中所有的内存块都能被开辟到堆上,栈的出现只是为了提高Go程序的执行效率。
开辟到栈上的内存块与开辟到堆上的内存块相比有哪些优势呢?
-
从栈上开辟内存块的速度会更快;
-
栈上开辟的内存块不需要被垃圾回收;
-
栈上的内存块的访问对CPU缓存更加友好。
同一个内存块要么在堆上要么在栈上。由于有些Go值不一定只存储在一个内存块,所以同一个Go值的不同值部也是可能在堆和栈上都有分布。
如果一个局部变量的某些值部被开辟到了堆上,我们就认为这个局部变量发生了内存逃逸,由于Go标准编译器中的逃逸分析还不够完善,所以某些本可以开辟到栈上的值也可能被开辟到堆上。
在Go程序运行时,每一个依然被使用的逃逸到堆上的值部至少会被一个开辟在栈上的值部所引用。比如局部变量T发生了逃逸被分配到了堆上,那么一个*T类型的隐式指针将会被创建在栈上,这个指针存储者变量T在堆上的地址。所以当内存逃逸发生时,会有一个从栈到堆的引用关系。
我们可以认为每个包级别的变量,也就是全局变量都被开辟到了堆上,并且他被开辟在一个全局内存区上的隐式指针所引用。实际上,这个指针引用这这个包级别变量的直接部分。
那什么是变量的直接值部和间接值部呢?
我们上面提到过,Go值中有一些是分布在同一个内存块上的,而有一些是分布在不同内存块上的。这些分布在不同内存块上的值就有直接值部和间接值部,被直接值部引用的值就是间接值部。
直接值部是每个值只分布在一个内存块的类型,包括布尔类型,数值类型,指针类型(包括unsafe.Pointer表示的非类型安全的指针类型),结构体类型和数组类型。
而有些类型是存在间接值部的,间接值部是被一个或者多个直接值部引用的值,这种类型的值会分布在不同的内存块上。含有间接值部的类型有切片类型,映射类型,通道类型,函数类型,接口类型,字符串类型。
我们以切片为例来理解直接值部和间接值部。
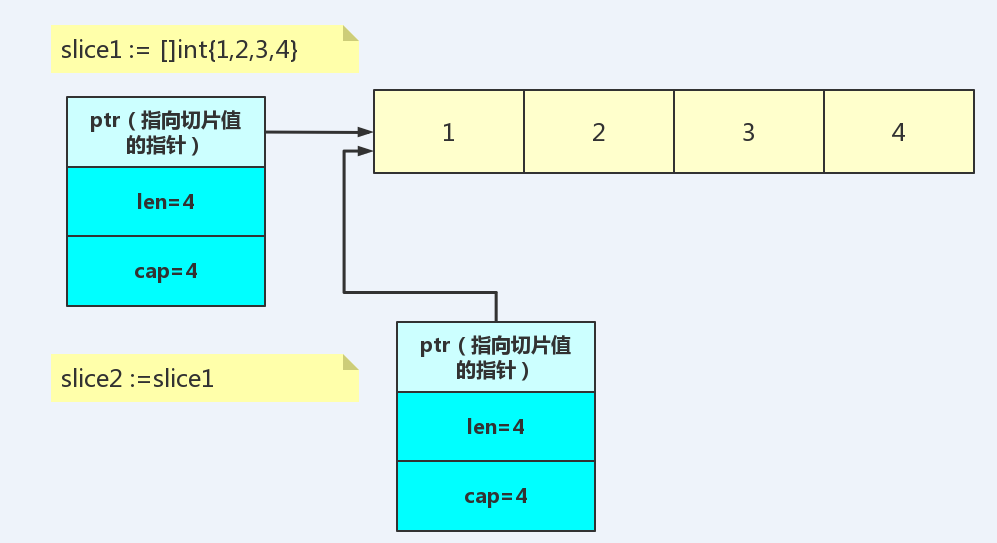
比如上面存储切片元素值的部分就是切片的间接值部,存储切片元信息的部分就是切片的直接值部。
注意:内存块的地址是可能发生改变的。
当一个协程栈发生扩缩容时,这个栈将会使用新的内存段,已经开辟在这个栈上的内存块也会被转移到这个新的内存段上,这时候这些内存块的地址就会发生改变。相应地,开辟在这个栈上的内存块的指针地址也会被刷新。比如我们文章开头讲到的例子。
如果想更扎实更系统的掌握Go语言,欢迎学习我的**Go工程师面试与技能专题课**,你收获的将不仅仅是offer~
https://coding.imooc.com/class/666.html

共同学习,写下你的评论
评论加载中...
作者其他优质文章



