
作者:Alec Radford & Luke Metz这两个作者都是open ai的研究员;Soumith Chintala是Facebook的研究员
1.ABSTRACT(摘要)
- In recent years, supervised learning with convolutional networks (CNNs) has seen huge adoption in computer vision applications.
近年来,利用卷积网络(CNN)进行的监督学习在计算机视觉应用中得到了广泛应用。 - Comparatively, unsupervised learning with CNNs has received less attention.
相比之下,使用 CNN 的无监督学习受到的关注较少。 - In this work we hope to help bridge the gap between the success of CNNs for supervised learning and unsupervised learning.
在这项工作中,我们希望帮助弥合 CNN 在监督学习和非监督学习方面的成功差距。 - We introduce a class of CNNs called deep convolutional generative adversarial networks (DCGANs), that have certain architectural constraints, and demonstrate that they are a strong candidate for unsupervised learning.
我们介绍了一类称为深度卷积生成对抗网络(DCGAN)的 CNN,它具有一定的架构限制,并证明它是无监督学习的理想选择。 - Training on various image datasets, we show convincing evidence that our deep convolutional adversarial pair learns a hierarchy of representations from object parts to scenes in both the generator and discriminator.
在各种图像数据集上进行训练后,我们展示了令人信服的证据,证明我们的深度卷积对抗对在生成器和判别器中学习了从物体部分到场景的表征层次。 - Additionally, we use the learned features for novel tasks -demonstrating their applicability as general image representations.
此外,我们还将学习到的特征用于新任务–展示它们作为通用图像表征的适用性。
摘要部分只有六句话,
- 首先第一句话说明CNN的已经被广泛用于计算机视觉任务;
- 第二句话引出主题,CNN在无监督学习中关注度不够,当然第二句是承接第一句的。
- 第三句话说明要达到的效果是什么样的?减少CNN在监督学习和非监督学习方面成功的差距。因为在第二句话已经做了铺垫,提到了无监督学习的关注度不够。
- 第四句话说明我们做了哪些事情?引出了主题深度卷积生成对抗网络也就是DCGAN,并证明它是无监督学习的理想选择。
- 第五句话说明了我们这个事情做的怎么样?我们通过在各个数据集进行训练,然后证明了深度卷积生成对抗网络在生成器和判别器中可以学习到从物体部分到场景的表征层次。
- 第六句话相当于延申部分(锦上添花),或者也可以说是验证我们达到的结论!将学习到的特征用于新任务-展示他们作为通用图像表征的适用性。
2. related work
2.1 representation learning from umlabeled data (从无标记数据中学习表示)
- Unsupervised representation learning is a fairly well studied problem in general computer vision research, as well as in the context of images.
在一般的计算机视觉研究中,无监督表示学习是一个研究相当深入的问题,在图像方面也是如此。 - A classic approach to unsupervised representation learning is to do clustering on the data (for example using K-means), and leverage the clusters for improved classification scores.
无监督表示学习的经典方法是对数据进行聚类(例如使用 K-means),并利用聚类来提高分类得分。 - In the context of images, one can do hierarchical clustering of image patches (Coates & Ng, 2012) to learn powerful image representations.
在图像方面,我们可以对图像斑块进行分层聚类(Coates & Ng, 2012),以学习强大的图像表征。 - Another popular method is to train auto-encoders (convolutionally, stacked (Vincent et al., 2010), separating the what and where components of the code (Zhao et al., 2015), ladder structures (Rasmus et al., 2015)) that encode an image into a compact code, and decode the code to reconstruct the image as accurately as possible.
另一种流行的方法是训练自动编码器(卷积编码器、堆叠编码器(Vincent 等人,2010 年)、分离代码中 "什么 "和 "在哪里 "成分的编码器(Zhao 等人,2015 年)、梯形结构编码器(Rasmus 等人,2015 年)),将图像编码成一个紧凑的代码,并对代码进行解码,以尽可能准确地重建图像。 - These methods have also been shown to learn good feature representations from image pixels.
事实证明,这些方法也能从图像像素中学习到良好的特征表示。 - Deep belief networks (Lee et al., 2009) have also been shown to work well in learning hierarchical representations.
深度信念网络(Lee 等人,2009 年)在学习分层表征方面也表现出色。
2.2 generating natural images (生成自然图像)
- Generative image models are well studied and fall into two categories: parametric and non-parametric.
生成图像模型已得到深入研究,可分为两类:参数模型和非参数模型。 - The non-parametric models often do matching from a database of existing images, often matching patches of images, and have been used in texture synthesis (Efros et al., 1999), super-resolution (Freeman et al., 2002) and in-painting (Hays & Efros, 2007).
非参数模型通常从现有图像数据库中进行匹配,通常是匹配图像片段,并已用于纹理合成(Efros 等人,1999 年)、超分辨率(Freeman 等人,2002 年)和内绘制(Hays & Efros,2007 年)。 - Parametric models for generating images has been explored extensively (for example on MNIST digits or for texture synthesis (Portilla & Simoncelli, 2000)).
人们已经对生成图像的参数模型进行了广泛的探索(例如 MNIST 数字或纹理合成(Portilla & Simoncelli, 2000))。 - However, generating natural images of the real world have had not much success until recently.
然而,直到最近,生成真实世界的自然图像才取得了很大成功。 - A variational sampling approach to generating images (Kingma & Welling, 2013) has had some success, but the samples often suffer from being blurry.
生成图像的变异采样方法(Kingma 和 Welling,2013 年)取得了一定的成功,但样本往往模糊不清。 - Another approach generates images using an iterative forward diffusion process (Sohl-Dickstein et al., 2015).
另一种方法是利用迭代前向扩散过程生成图像(Sohl-Dickstein 等人,2015 年)。 - Generative Adversarial Networks (Goodfellow et al., 2014) generated images suffering from being noisy and incomprehensible.
生成对抗网络(Goodfellow 等人,2014 年)生成的图像既嘈杂又难以理解。 - A laplacian pyramid extension to this approach (Denton et al., 2015) showed higher quality images, but they still suffered from the objects looking wobbly because of noise introduced in chaining multiple models.
这种方法的拉普拉斯金字塔扩展(Denton 等人,2015 年)显示了更高质量的图像,但由于在连锁多个模型时引入了噪声,这些图像仍然存在物体看起来摇摆不定的问题。 - A recurrent network approach (Gregor et al., 2015) and a deconvolution network approach (Dosovitskiy et al., 2014) have also recently had some success with generating natural images.
最近,一种递归网络方法(Gregor 等人,2015 年)和一种反卷积网络方法(Dosovitskiy 等人,2014 年)也在生成自然图像方面取得了一些成功。 - However, they have not leveraged the generators for supervised tasks.
不过,他们还没有利用生成器来完成监督任务。
2.3 Visualizing the Internals of CNNS ( 可视化 CNNS 的内部结构 )
- One constant criticism of using neural networks has been that they are black-box methods, with little understanding of what the networks do in the form of a simple human-consumable algorithm.
一直以来,对使用神经网络的一种批评是,神经网络是一种黑盒子方法,人们很少了解神经网络以一种简单的可由人类消耗的算法形式所做的工作。 - In the context of CNNs, Zeiler et. al. (Zeiler & Fergus, 2014) showed that by using deconvolutions and filtering the maximal activations, one can find the approximate purpose of each convolution filter in the network.
在 CNN 方面,Zeiler 等人(Zeiler & Fergus, 2014 年)的研究表明,通过使用反卷积和过滤最大激活度,可以找到网络中每个卷积滤波器的大致用途。 - Similarly, using a gradient descent on the inputs lets us inspect the ideal image that activates certain subsets of filters (Mordvintsev et al.).
同样,在输入上使用梯度下降法也能让我们检测到激活某些滤波器子集的理想图像(Mordvintsev 等人)。
3. Approach and model architecture (方法和模型结构)
- Historical attempts to scale up GANs using CNNs to model images have been unsuccessful.
利用 CNN 对图像建模来扩展 GAN 的历史尝试并不成功。 - This motivated the authors of LAPGAN (Denton et al., 2015) to develop an alternative approach to iteratively upscale low resolution generated images which can be modeled more reliably.
这促使 LAPGAN 的作者(Denton 等人,2015 年)开发出一种替代方法,对生成的低分辨率图像进行迭代升维,从而更可靠地建模。 - We also encountered difficulties attempting to scale GANs using CNN architectures commonly used in the supervised literature.
我们在尝试使用监督文献中常用的 CNN 架构来扩展 GAN 时也遇到了困难。 - However, after extensive model exploration we identified a family of architectures that resulted in stable training across a range of datasets and allowed for training higher resolution and deeper generative models.
不过,经过对模型的广泛探索,我们确定了一系列架构,这些架构可以在一系列数据集上进行稳定的训练,并允许训练更高分辨率和更深层次的生成模型。 - Core to our approach is adopting and modifying three recently demonstrated changes to CNN architectures.
我们方法的核心是采用和修改最近展示的 CNN 架构的三个变化。 - The first is the all convolutional net (Springenberg et al., 2014) which replaces deterministic spatial pooling functions (such as maxpooling) with strided convolutions, allowing the network to learn its own spatial downsampling.
第一种是全卷积网(Springenberg 等人,2014 年),它用分步卷积取代了确定性空间池化函数(如 maxpooling),允许网络学习自己的空间降采样。 - We use this approach in our generator, allowing it to learn its own spatial upsampling, and discriminator.
我们在生成器中使用了这种方法,让它学习自己的空间上采样和判别器。 - Second is the trend towards eliminating fully connected layers on top of convolutional features.
其次是在卷积特征之上取消全连接层的趋势。 - The strongest example of this is global average pooling which has been utilized in state of the art image classification models (Mordvintsev et al.).
最典型的例子就是全局平均集合,它已被用于最先进的图像分类模型中(Mordvintsev 等人)。 - We found global average pooling increased model stability but hurt convergence speed.
我们发现,全局平均池化提高了模型的稳定性,但却降低了收敛速度。 - A middle ground of directly connecting the highest convolutional features to the input and output respectively of the generator and discriminator worked well.
将最高卷积特征分别直接连接到生成器和判别器的输入和输出的中间方案效果很好。 - The first layer of the GAN, which takes a uniform noise distribution Z as input, could be calledfully connected as it is just a matrix multiplication, but the result is reshaped into a 4-dimensional tensor and used as the start of the convolution stack.
GAN 的第一层将均匀噪声分布 Z 作为输入,由于只是矩阵乘法,因此可称为全连接,但其结果被重塑为一个 4 维张量,并用作卷积堆栈的起点。 - For the discriminator, the last convolution layer is flattened and then fed into a single sigmoid output.
对于判别器,最后一个卷积层被扁平化,然后馈入一个单一的 sigmoid 输出。 - Third is Batch Normalization (Ioffe & Szegedy, 2015) which stabilizes learning by normalizing the input to each unit to have zero mean and unit variance.
第三种是批量归一化(Batch Normalization)(Ioffe & Szegedy, 2015),它通过将每个单元的输入归一化为具有零均值和单位方差来稳定学习。 - This helps deal with training problems that arise due to poor initialization and helps gradient flow in deeper models.
这有助于解决因初始化不佳而产生的训练问题,并有助于更深层模型的梯度流动。 - This proved critical to get deep generators to begin learning, preventing the generator from collapsing all samples to a single point which is a common failure mode observed in GANs.
事实证明,这对深度生成器开始学习至关重要,可以防止生成器将所有样本归结为一个点,而这是在 GAN 中观察到的常见失败模式。 - Directly applying batchnorm to all layers however, resulted in sample oscillation and model instability.
然而,直接对所有层应用批处理规范会导致样本振荡和模型不稳定。 - This was avoided by not applying batchnorm to the generator output layer and the discriminator input layer.
通过不对生成器输出层和判别器输入层应用批处理规范,可以避免这种情况。 - The ReLU activation (Nair & Hinton, 2010) is used in the generator with the exception of the output layer which uses the Tanh function.
除输出层使用 Tanh 函数外,生成器均使用 ReLU 激活(Nair & Hinton,2010 年)。 - We observed that using a bounded activation allowed the model to learn more quickly to saturate and cover the color space of the training distribution.
我们发现,使用有界激活可以让模型更快地学习饱和并覆盖训练分布的色彩空间。 - Within the discriminator we found the leaky rectified activation (Maas et al., 2013) (Xu et al., 2015) to work well, especially for higher resolution modeling.
在判别器中,我们发现漏整流激活(Maas 等人,2013 年)(Xu 等人,2015 年)效果很好,尤其是在更高分辨率建模时。 - This is in contrast to the original GAN paper, which used the maxout activation (Goodfellow et al., 2013).
这与最初的 GAN 论文形成了鲜明对比,后者使用的是 maxout 激活(Goodfellow 等人,2013 年)。
Architecture guidelines for stable Deep Convolutional GANs
稳定深度卷积 GAN 的架构指南
- Replace any pooling layers with strided convolutions (discriminator) and fractional-strided convolutions (generator).
用分段卷积(鉴别器)和分数分段卷积(发生器)取代任何汇集层。 - Use batchnorm in both the generator and the discriminator.
在生成器和判别器中都使用批处理规范。 - Remove fully connected hidden layers for deeper architectures.
移除完全连接的隐藏层,以实现更深层次的架构。 - Use ReLU activation in generator for all layers except for the output, which uses Tanh.
除输出层使用 Tanh 外,其余各层均使用 ReLU 激活生成器。 - Use LeakyReLU activation in the discriminator for all layers.
在所有层的判别器中使用 LeakyReLU 激活。
4. Details of adversarial training (对抗训练的细节)
- We trained DCGANs on three datasets, Large-scale Scene Understanding (LSUN) (Yu et al., 2015), Imagenet-1k and a newly assembled Faces dataset.
我们在三个数据集上对 DCGAN 进行了训练,它们分别是大规模场景理解(LSUN)(Yu 等人,2015 年)、Imagenet-1k 和新组建的面孔数据集。 - Details on the usage of each of these datasets are given below.
有关每个数据集的使用详情如下。 - No pre-processing was applied to training images besides scaling to the range of the tanh activation function [-1, 1].
除了缩放至 tanh 激活函数的范围 [-1, 1],没有对训练图像进行任何预处理。 - All models were trained with mini-batch stochastic gradient descent (SGD) with a mini-batch size of 128.
所有模型均采用迷你批次随机梯度下降法(SGD)进行训练,迷你批次大小为 128。 - All weights were initialized from a zero-centered Normal distribution with standard deviation 0.02. In the LeakyReLU, the slope of the leak was set to 0.2 in all models.
所有权重均从标准偏差为 0.02 的零心正态分布初始化。在 LeakyReLU 中,所有模型的泄漏斜率都设为 0.2。 - All weights were initialized from a zero-centered Normal distribution with standard deviation 0.02. In the LeakyReLU, the slope of the leak was set to 0.2 in all models.
所有权重均从标准偏差为 0.02 的零中心正态分布初始化。在 LeakyReLU 中,所有模型的泄漏斜率都设为 0.2。 - While previous GAN work has used momentum to accelerate training, we used the Adam optimizer (Kingma & Ba, 2014) with tuned hyperparameters.
以前的 GAN 工作使用动量来加速训练,而我们则使用了 Adam 优化器(Kingma 和 Ba,2014 年),并调整了超参数。 - We found the suggested learning rate of 0.001, to be too high, using 0.0002 instead. Additionally, we found leaving the momentum term β1 at the suggested value of 0.9 resulted in training oscillation and instability while reducing it to 0.5 helped stabilize training.
我们发现建议的 0.001 学习率过高,因此改用 0.0002。此外,我们发现将动量项 β1 保留在建议值 0.9 会导致训练振荡和不稳定,而将其减小到 0.5 则有助于稳定训练。
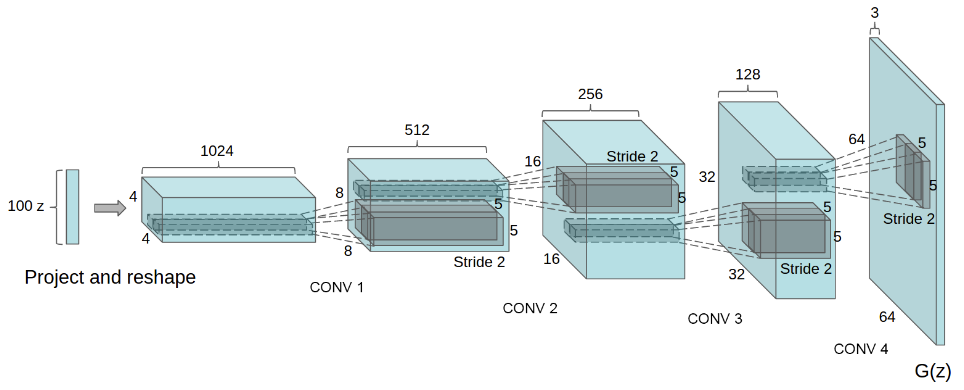
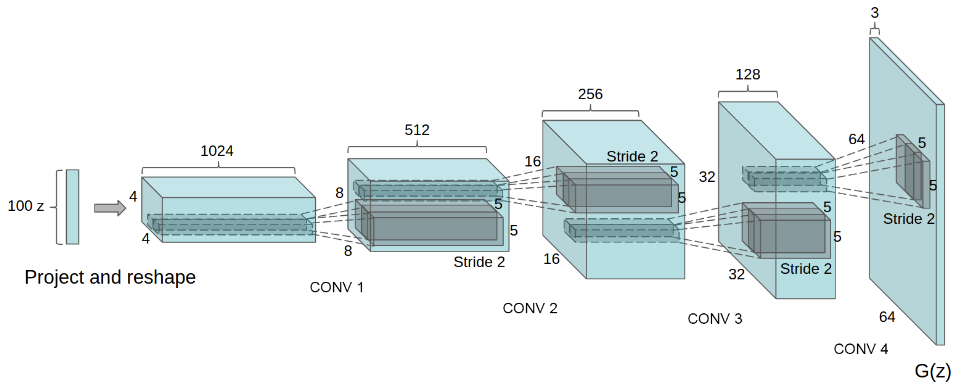
用于 LSUN 场景建模的 DCGAN 生成器。一个 100 维的均匀分布 Z 被投射到一个具有许多特征图的小空间范围卷积表示中。然后,通过一系列的四次分段卷积(在最近的一些论文中,这些卷积被错误地称为解卷积)将这一高层次表示转换成 64 × 64 像素的图像。值得注意的是,没有使用全连接层或池化层。
5. DCGAN 和 原始GAN区别
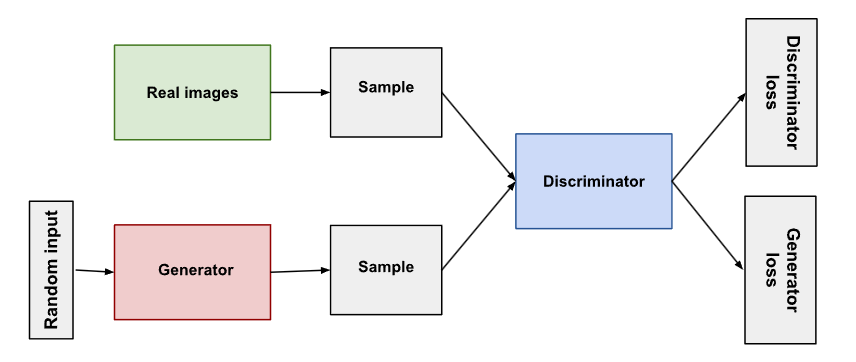
- DCGAN和初始的GAN最大的区别是使用Deep convolution替代掉原始GAN网络中的Generator和Discriminator.
- DCGAN中的生成器是通过不断的放大从4——》8——》16——》32——》64,最后得到64 x 64 三通道的图片。
- DCGAN中的判别器与生成器的过程刚好是相反的。
- 在DCGAN中生成器都使用了转置卷积,而判别器使用的是正常的卷积神经网络。
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦