
人类智能的一个关键特征是,人类可以通过仅使用几个例子进行推理来学习执行新任务。扩展语言模型解锁了机器学习中的一系列新应用和范式,包括通过上下文学习执行具有挑战性的推理任务的能力。然而,语言模型仍然对给出提示的方式很敏感,这表明它们没有以稳健的方式进行推理。例如,语言模型通常需要繁重的提示工程或措辞任务作为指令,并且它们表现出意想不到的行为,例如即使显示不正确的标签,任务的性能也不会受到影响。
在“ 符号调整改进了语言模型中的上下文学习”中,我们提出了一个简单的微调过程,我们称之为符号调整,它可以通过强调输入标签映射来改善上下文学习。我们尝试了跨 Flan-PaLM 模型的符号调整,并观察到各种设置的好处。
- 符号调优可提高看不见的上下文学习任务的性能,并且对未指定的提示(例如没有指令或没有自然语言标签的提示)更加可靠。
- 符号调整模型在算法推理任务中要强得多。
- 最后,符号调整模型在遵循上下文中呈现的翻转标签方面显示出很大的改进,这意味着它们更能够使用上下文中的信息来覆盖先前的知识。
 |
|---|
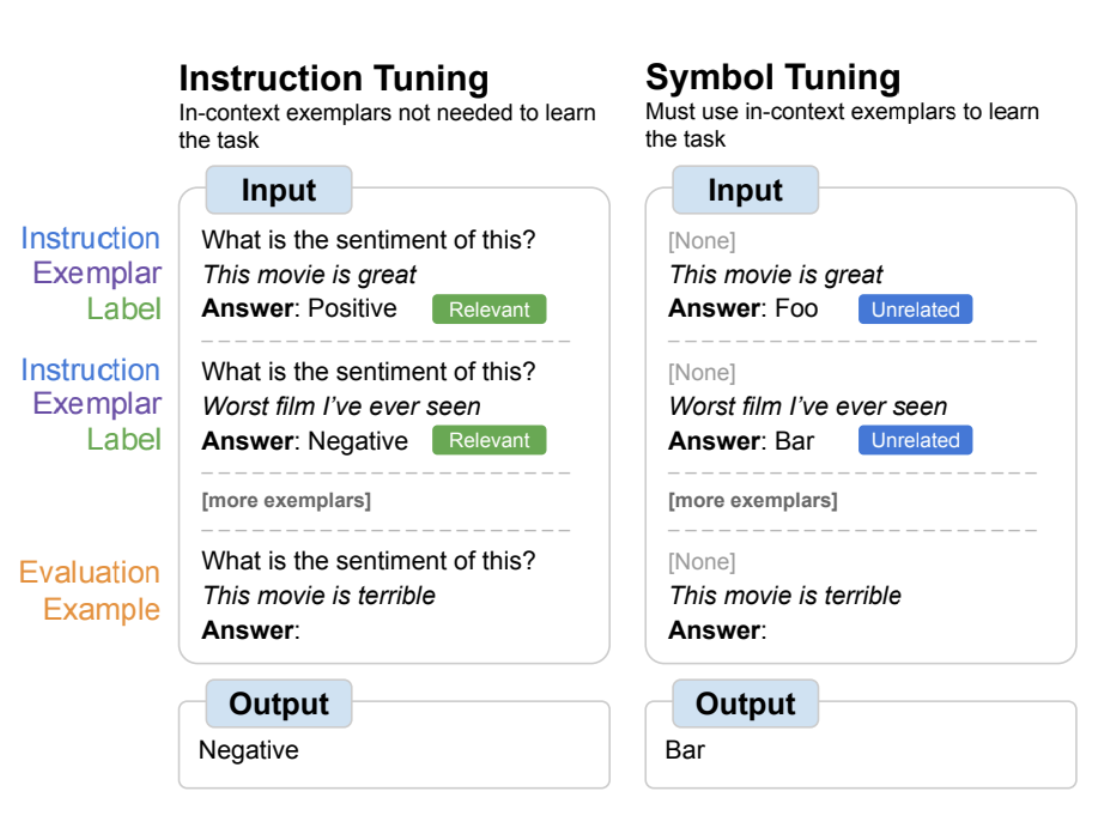
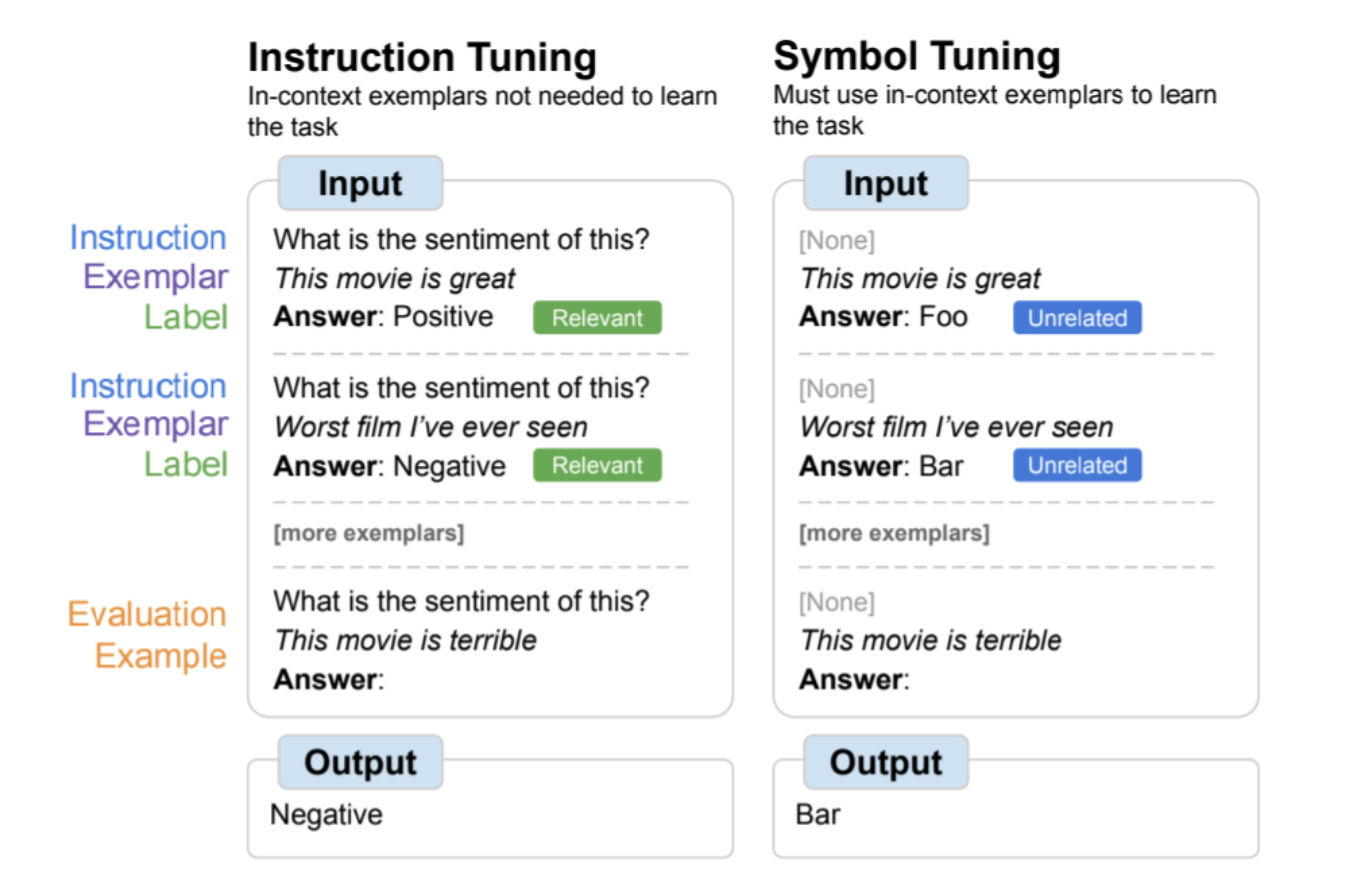
| 符号优化概述,其中模型在自然语言标签替换为任意符号的任务上进行微调。符号调优依赖于这样的直觉,即当指令和相关标签不可用时,模型必须使用上下文中的示例来学习任务。 |
动机
指令调优是一种常见的微调方法,已被证明可以提高性能并允许模型更好地遵循上下文示例。然而,一个缺点是模型没有被迫学习使用这些示例,因为任务在评估示例中通过指令和自然语言标签冗余定义。例如,在上图的左侧,尽管示例可以帮助模型理解任务(情绪分析),但它们并不是绝对必要的,因为模型可以忽略示例,只阅读指示任务是什么的指令。
在符号调优中,模型在删除指令和自然语言标签替换为语义上不相关的标签(例如,“Foo”、“Bar”等)的示例上进行微调。在此设置中,如果不查看上下文中的示例,任务就不清楚。例如,在上图的右侧,需要多个上下文示例才能弄清楚任务。由于符号优化会教会模型对上下文中的示例进行推理,因此符号优化的模型在需要在上下文中示例及其标签之间进行推理的任务上具有更好的性能。
 |
|---|
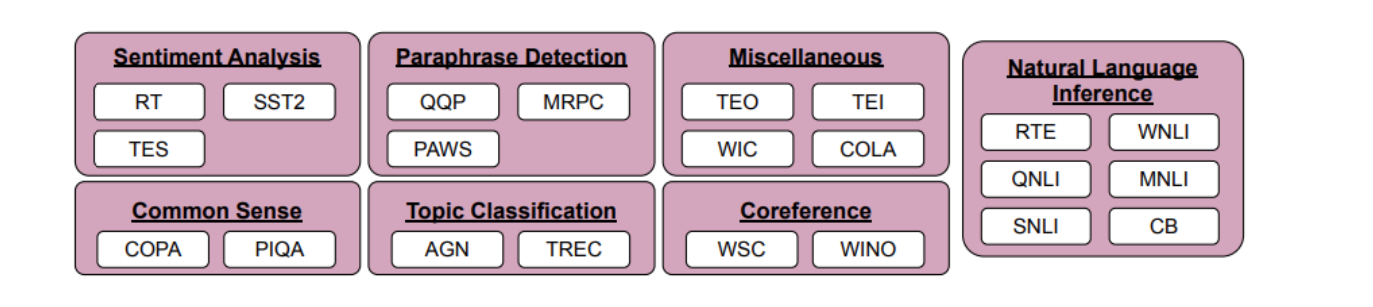
| 用于符号优化的数据集和任务类型。 |
符号调整过程
我们选择了 22 个公开可用的自然语言处理 (NLP) 数据集,用于符号调整过程。这些任务在过去已被广泛使用,我们只选择分类类型的任务,因为我们的方法需要离散标签。然后,我们将标签重新映射到从以下三个类别之一中选择的一组 ~30K 任意标签中的随机标签:整数、字符组合和单词。
对于我们的实验,我们符号调谐 Flan-PaLM ,PaLM 的指令调谐变体。我们使用三种不同尺寸的 Flan-PaLM 型号:Flan-PaLM-8B、Flan-PaLM-62B 和 Flan-PaLM-540B。我们还测试了Flan-cont-PaLM-62B(Flan-PaLM-62B,1.3T代币而不是780B代币),我们缩写为62B-c。
 |
|---|
| 我们使用来自三个类别(整数、字符组合和单词)的一组 ∼300K 任意符号。∼调谐过程中使用30K符号,其余符号用于评估。 |
实验设置
我们想要评估模型执行看不见的任务的能力,因此我们无法评估符号调整中使用的任务(22 个数据集)或指令调整期间使用的任务(1.8K 任务)。因此,我们选择了 11 个在微调过程中未使用的 NLP 数据集。
上下文学习
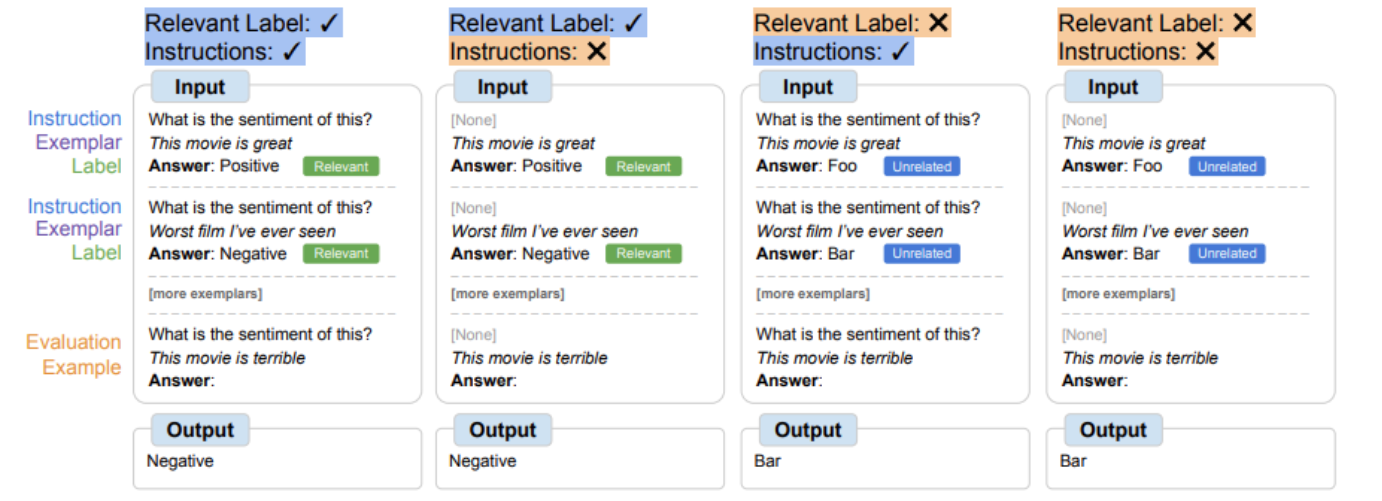
在符号调整过程中,模型必须学会使用上下文示例进行推理才能成功执行任务,因为会修改提示以确保不能简单地从相关标签或指令中学习任务。符号优化模型在任务不明确且需要在上下文示例及其标签之间进行推理的设置中应表现更好。为了探索这些设置,我们定义了四个上下文学习设置,这些设置改变了输入和标签之间学习任务所需的推理量(基于说明/相关标签的可用性)
 |
|---|
| 根据指令和相关自然语言标签的可用性,模型可能需要使用上下文示例进行不同数量的推理。当这些功能不可用时,模型必须使用给定的上下文示例进行推理才能成功执行任务。 |
符号调整提高了 62B 及更高型号所有设置的性能,对具有相关自然语言标签的设置进行了小幅改进(+0.8% 至 +4.2%),对没有相关自然语言标签的设置进行了实质性改进(+5.5% 至 +15.5%)。引人注目的是,当相关标签不可用时,符号调谐的 Flan-PaLM-8B 优于 FlanPaLM-62B,符号调谐的 Flan-PaLM-62B 优于 Flan-PaLM-540B。这种性能差异表明,符号调整可以允许更小的模型以及大型模型执行这些任务(有效地节省了 10 倍的推理计算)。
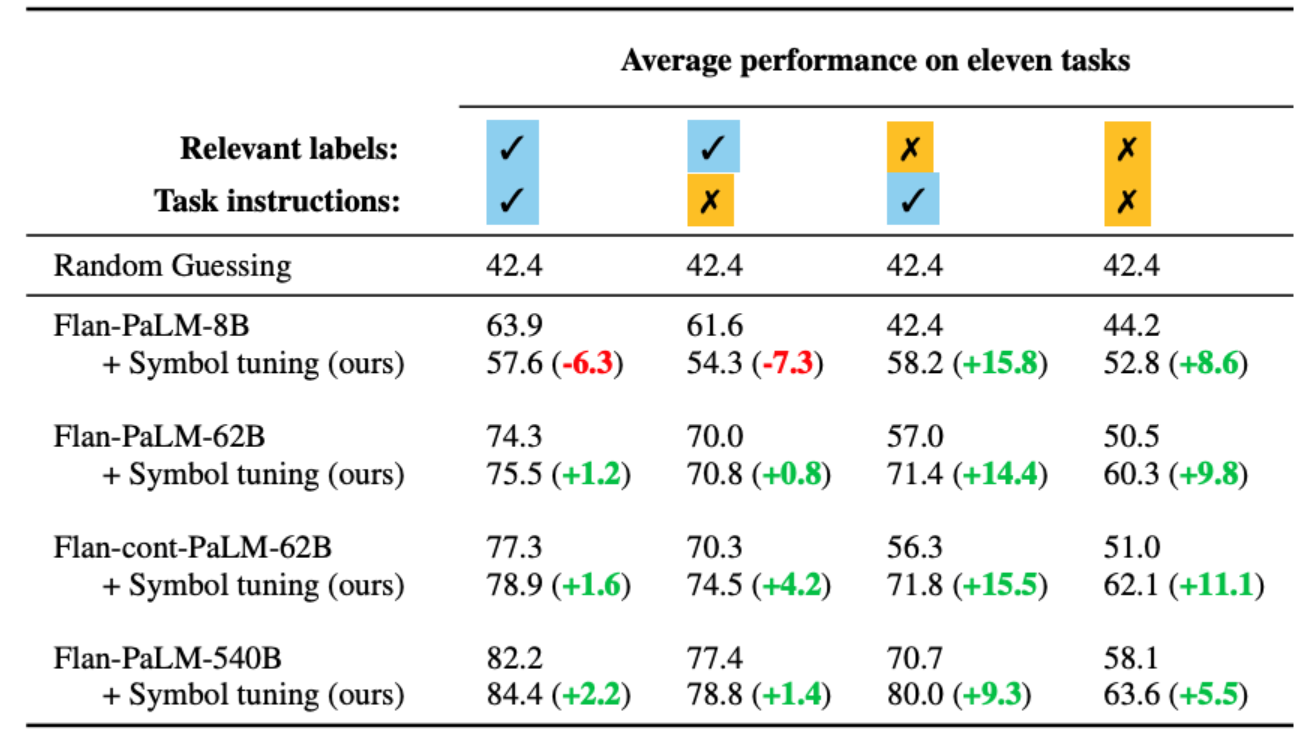 |
|---|
| 与基线相比,足够大的符号调整模型更擅长上下文学习,尤其是在没有相关标签的设置中。性能显示为 11 个任务的平均模型准确度 (%)。 |
算法推理
我们还对BIG-Bench的算法推理任务进行了实验。有两组主要任务:1) 列表函数 — 在包含非负整数的输入和输出列表之间识别转换函数(例如,删除列表中的最后一个元素);2)简单的图灵概念 — 使用二进制字符串进行推理,以了解将输入映射到输出的概念(例如,交换字符串中的 0 和 1)。
在列表函数和简单的图灵概念任务中,符号调整分别导致平均性能提高 18.2% 和 15.3%。此外,具有符号调谐功能的 Flan-cont-PaLM-62B 在列表函数任务上的平均性能优于 Flan-PaLM-540B,这相当于推理计算减少了 10 倍。这些改进表明,符号调整增强了模型在上下文中学习看不见的任务类型的能力,因为符号调整不包括任何算法数据。
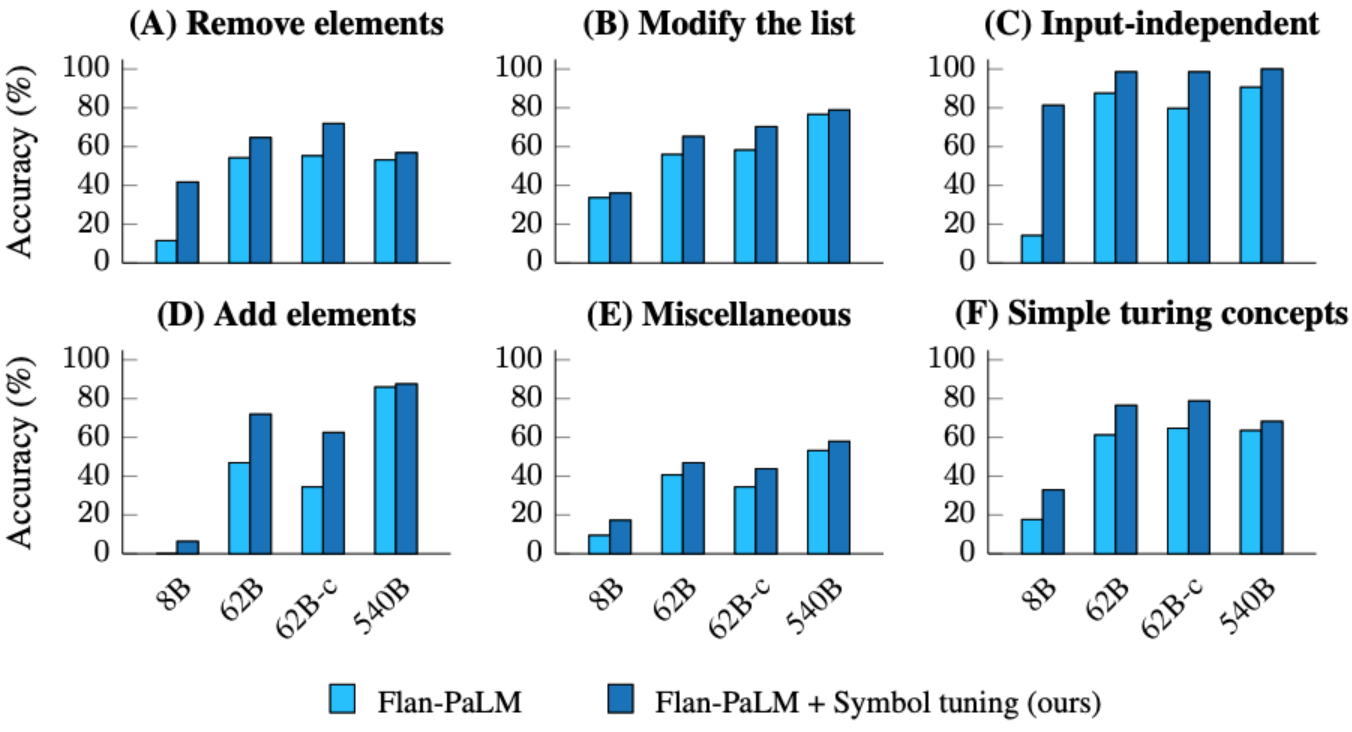 |
|---|
| 符号调整模型在列表函数任务和简单的图灵概念任务上实现了更高的性能。(A–E):列表函数任务的类别。(F):简单的图灵概念任务。 |
翻转标签
在翻转标签实验中,上下文和评估示例的标签被翻转,这意味着先验知识和输入标签映射不一致(例如,包含积极情绪的句子标记为“消极情绪”),从而使我们能够研究模型是否可以覆盖先验知识。以前的研究表明,虽然预训练模型(没有指令调优)可以在某种程度上遵循上下文中呈现的翻转标签,但指令调优降低了这种能力。
我们看到,所有模型大小都有类似的趋势——符号调整模型比指令调整模型更能遵循翻转标签。我们发现,经过符号调整后,Flan-PaLM-8B在所有数据集中的平均改进为26.5%,Flan-PaLM-62B的改进为33.7%,Flan-PaLM-540B的改善为34.0%。此外,符号优化模型可实现与仅预训练模型相似或更好的平均性能。
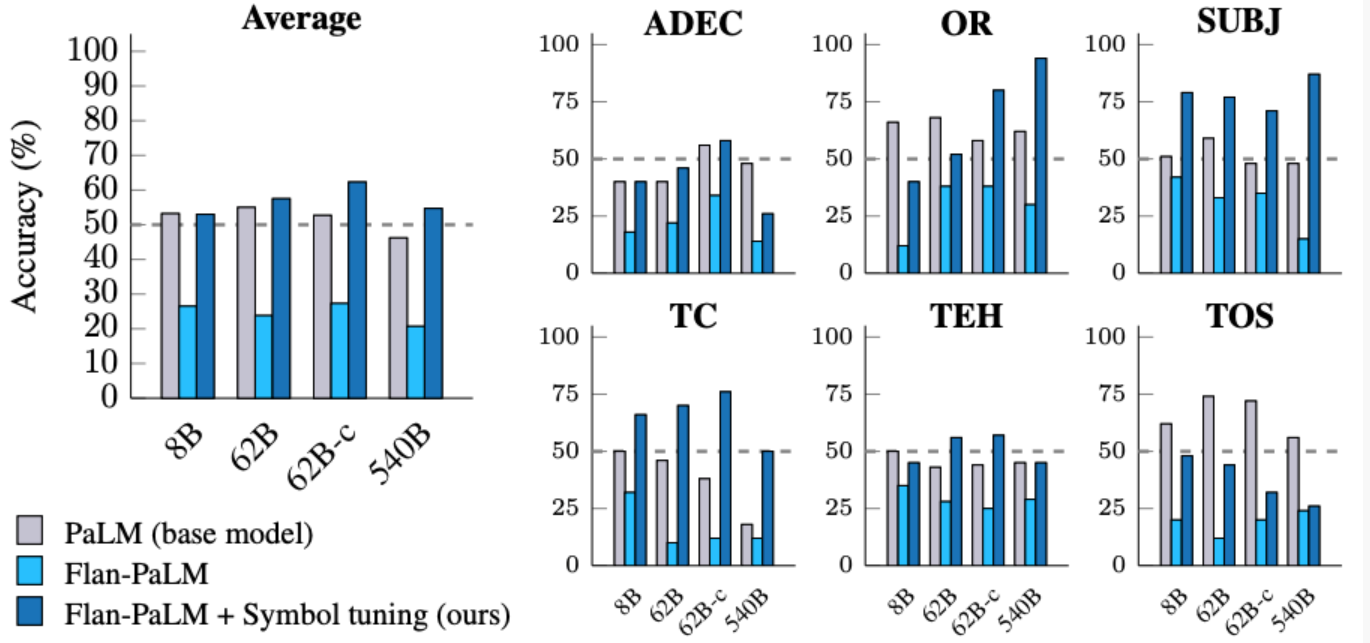 |
|---|
| 符号优化模型比指令优化模型更擅长遵循上下文中呈现的翻转标签。 |
结论
我们介绍了符号调优,这是一种在自然语言标签重新映射到任意符号的任务上调优模型的新方法。符号调优基于这样的直觉,即当模型无法使用指令或相关标签来确定呈现的任务时,它必须通过从上下文示例中学习来实现。我们使用符号调优程序调优了四种语言模型,利用 22 个数据集和大约 30K 个任意符号的调优混合作为标签。
我们首先展示了符号调整可以提高看不见的上下文学习任务的性能,尤其是当提示不包含指令或相关标签时。我们还发现,符号调整模型在算法推理任务中要好得多,尽管在符号调整过程中缺乏数字或算法数据。最后,在输入具有翻转标签的上下文学习环境中,符号调整(对于某些数据集)恢复了遵循在指令调整期间丢失的翻转标签的能力。
今后的工作
通过符号调整,我们的目标是提高模型在上下文学习期间检查和学习输入标签映射的程度。我们希望我们的结果能鼓励进一步提高语言模型对上下文中呈现的符号进行推理的能力。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



