

今天,我试着简要综述几类不同的图数据库的分布式与切图的设计,希望可以帮助大家了解不同项目、产品的设计差异。如果有理解不对的地方,欢迎留言讨论。
什么是分布式系统
一般来说,分布式系统是一组计算机程序的集合,这些程序利用跨多个独立节点的资源来实现共同的目标;这里的独立节点,硬件上大多是指商用服务器(Commodity Servers)而不是大型主机(Mainframe);这里的跨节点协同,硬件上大多是基于以太网设备或者更高端的 RMDA 设备。
为什么我们需要分布式系统?
使用分布式技术的主要目的,本质上是用软件技术 + 廉价硬件来换取昂贵硬件设备(比如主机)的成本;特别是在大多数私有机房环境 —— 而不是公有云端或者超算条件下,此时采购成本是商业决策的重要依据。
除了降低硬件成本外,分布式技术带来的另一个好处是其 “扩展性”,通过在原有商用服务器的数量基础上,增加几台服务器,再结合分布式软件的调度和分发能力,使得新加入的这几台服务器也再额外提供更多的服务;
相比于每次扩容都要 1 比 1 采购更多的等数量服务器,或者购买更高配置的服务器;分布式技术这一方面使得采购计划可以按需扩容,降低了一次性的大额资本支出;另一方面也使得业务容量可以更加容易规划。
分布式系统的基础问题
在分布式技术中,由于数据的存储和计算需要跨多个独立节点来实现,因此不得不涉及到一系列基础技术。在本文中我们只讨论两个:一是提供数据(和服务)的拷贝或者副本的问题;二是对于那些庞大数据的存储和计算该如何分发到各个独立节点上完成?
一、数据的副本问题
由于是商用服务器,其硬件上的可靠性和可维护性远远低于主机,网线松动、硬盘损坏、电源故障在大型机房中几乎每小时都在发生,是常态;处理屏蔽这些硬件问题是分布式软件系统要解决的基本问题。一个常用的方式是为数据(和其服务)提供更多的拷贝或者副本,这些副本存在于多台商用服务器上。当一些副本发生故障时,由正常的副本继续提供服务;并且当访问压力增加时,还可以增加更多的副本来增强服务能力。此外,还需要通过一定的技术手段来保证这些副本的 “一致性”,也就是每个服务器上各个副本的数据是一样的。
当然,在图数据库中,副本问题也存在;其处理方式和大多数大数据、RDBMS 会较为类似。
二、是数据的切分问题
单台服务器的硬盘、内存、CPU 都是有限的,TB、PB 级别的数据通过一定的办法分发到各个服务器上,这称为” 切片”。当一些请求要访问多个切片时,分布式系统要能够将这些请求拆散分发到各个正确的分片上,并将各分片的返回重新 “拼装” 成完整的结果。
图数据中的切分问题:切图
在图数据库中,这个分发过程被形象的称为 “切图”:就是把一个大图切成很多的小图,把对于这些小图的存储或者计算再放置在不同的服务器上。相比大数据、RDBMS 的大多数方案,值得一些特别的说明。
我们先考虑一个静态的(不会发生变化的)图结构,比如 “CiteSeer 数据集”,这里面记录了 3,312 篇论文,以及这些论文之间的引用关系;这是一个很小规模的数据集,因此工程上,我们可以基本相信对于这个数据集的处理是可以交给单个服务器。
再对于 twitter2010 这个数据集,其中有 1,271 万个顶点和 2.3 亿条边,对于今天(2023 年)的主流服务器来说,相对可以轻松处理;但对于 10 年前的服务器来说,可能就需要选购非常昂贵的高端服务器才行。
但对于 WDC 数据集 (Web Data Commons),其中有 17 亿个顶点和 640 亿条边,这样规模的计算这对于当前单台主流服务器来说也相当困难了。
另一方面,由于人类社会数据产生的速度快于摩尔定律,而数据之间的交互与关系又指数级高于数据产生的速度;“切图” 似乎是一个不可避免的问题;但这听上去似乎和各种主流分布式技术里面的数据分片和散列的方式没啥区别。毕竟那么多大数据系统,不都要 “切” 吗
等等 —— 图真的那么好” 切” 吗?

遗憾的是,并不是。图领域里面,” 切图” 是一个在技术、产品和工程上需要仔细权衡的问题。
切图面临的三个问题
第一个问题,切在哪里?在大数据或者 RDBMS 中,我们根据记录或者字段来进行 行切 row-based 或者 列切 column-based,也可以根据 ID 规则进行切分;这些在语义和技术都比较直观。可是图的特点是它的强连通性,一个点通过一些边,关联上了另外一些点,这些点又通过它们的邻边关联上了更多的点,就像全世界的 Web 网页,几乎都通过超链接关联在一起,那对于图来说,切在哪里才是语义上直观与自然的。(如果用 RDBMS 的术语,相当于有大量的外键情况下,如何切分)。当然,也存在一些天然语义上的图切片方式,例如在新冠疫情下,各种毒株在中国的传染链条和国外的链条已经天然是两个不同的网络结构。但此时,引入了第二个问题。
第二个问题,如何保证切了之后,各分片的负载是大致均衡的?天然形成的图符合幂率定律 ——20% 的少数节点连接了 80% 的其他节点,这些少数节点也称为 “超级节点” 或者 “稠密点”。这意味着少数超级节点关联了大多数其他的平平无奇的节点。因此可以预计含有超级节点的分片(服务器)的负载和热点会远远大于其他不含超级节点的分片。

图解:互联网上网站通过超链接形成的关联网络可视效果,其中的超级网站(节点)清晰可见
第三个问题,当图网络逐渐演化增长,图的分布和连通性也逐渐发生了改变,原有的切分方法逐渐失效,该如何评估和进行重分布。下图是人类大脑 860 亿个神经元之间的连接可视图,随着学习、锻炼、睡眠、衰老,神经元连接甚至在周级别就会发生显著的变化;原先得到的切片方式可能完全跟不上变化。
当然还有其他很多要考虑的问题细节,本文也尽量避免引入太多的技术术语。
遗憾的是,虽然有这些问题(当然其实还有更多),在技术角度并没有一个通用的最优方案,各个产品针对其重点不得不进行取舍,下面是一些举例。
不同图数据库的切图方式
1. “分布式” 但不” 切图”
这种思路的典型做法是 Neo4j 3.5 虽然采用了分布式的架构,但不进行图切分。
采用分布式的目的,是为了保证写入的多副本一致性和读负载能力。也就是说每个服务器中都保留了” 全量” 的图数据,因此图数据不能大于单机的内存和硬盘容量;而通过增加写副本,可以保证写入过程中单机失效问题;通过增加读副本,可以提供更多的读请求能力(不能提高写请求的能力)。
可以看到对于前面的三个问题,这种方案在产品层面直接避免。但是理论上,这样的方案称为 “分布式” 并没有什么问题。
多说一句,由于是单机,数据库意义上的 ACID 在技术上较为简单。
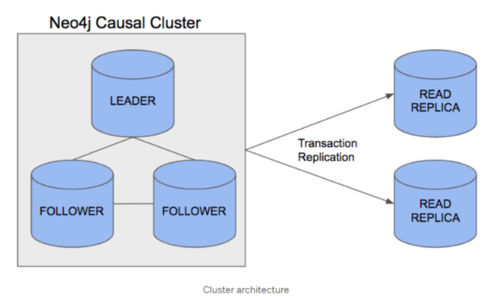
Neo4j 3.5 的因果集群架构
https://medium.com/neo4j/querying-neo4j-clusters-7d6fde75b5b4
2. 分布式,由用户来” 切图”
这个典型的代表是 Neo4j 4.x Fabric。根据业务情况,用户指定将每个部分的子图放在一个 (组) 服务器上,例如在一个集群内,E 号产品的图放在 E 号服务器上,N 号产品的图放在 N 号服务器上。当然,为了服务本身的可用性,这些服务器还可以采用上文中 Causal Cluster 的方案。
在这个过程中,不论是查询还是写入,都需要用户指定要访问哪个服务。Fabric 辅助用户代理路由。这个方案和 RDBMS 的分表非常类似,用户在使用过程中自己指定要使用那个分区或者分表,“切分” 这个动作,用户是有着完全的掌控。
可以看到对于前面的三个问题,这种方案在产品层面完全交给了用户来决定。当然,这样的方案也可以称为 “分布式”。
多说一句,虽然可以保证 E 服务器内部的 ACID。但因为存在一定数量的边” 横跨” 两个服务器,技术上不保证这些” 横跨” 边操作的 ACID。
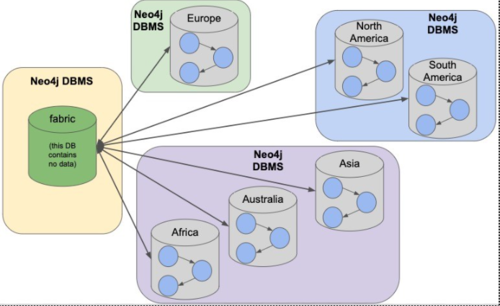
Neo4j Fabric 架构
https://neo4j.com/developer/neo4j-fabric-sharding/
3. 非对等分布式,” 切图”, 粗颗粒度的副本
在这种方案中,既有多副本,也有 “切图”,这两个过程也都需要少量用户的介入。

Tigergraph 的切图方案,可访问视频查看:https://www.youtube.com/watch?v=pxtVJSpERgk
在 TigerGraph 的方案中,点和边(在编码后),会分散到多个分片上。
上面的三个问题,第 1 和 2 可以通过编码部分的技巧来部分缓解,并将部分查询或者计算的决策(单机还是分布式模型)交给用户决定来实现权衡。
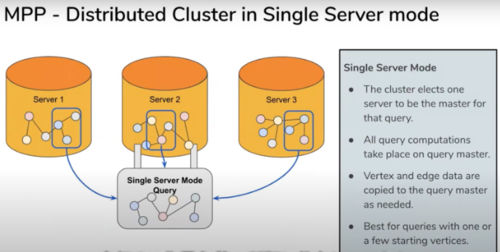

TigerGraph 的单机查询模式和并行计算模式
多说一句,这样一组分片必需要完整并一模一样的复制多份(因此扩容颗粒度是整个图,而不是某个分片)。相对扩容时的单次支出较大。
4. 全对等分布式,” 切图”,细颗粒度的副本
还有一些方案的架构设计目的中,相对把图的扩展性 / 弹性排在整个系统设计最高的优先级。其假设是数据产生的速度快于摩尔定律,而数据之间的交互与关系又指数级高于数据产生的速度。因此,必须要能够处理这样爆炸增长的数据,并快速提供服务。
在这种架构中,通常的显著特点是把存储层和计算层物理上分开,各自实现细颗粒度的扩容能力;
数据分片由存储层负责,通常用 hash 或者一致性 hash 的方案进行切分,根据点的 ID 或者主键进行散列。(回答第一个问题)
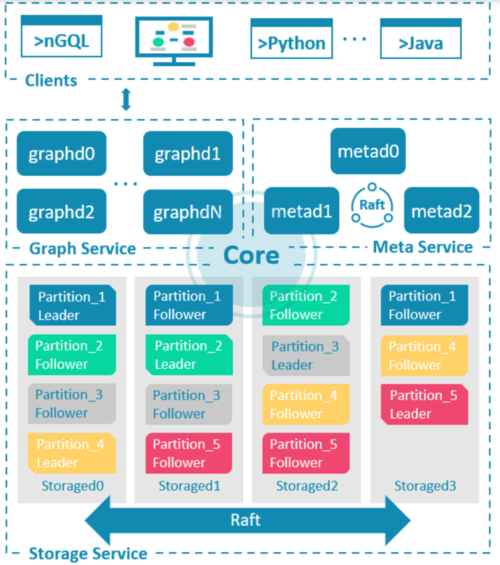
NebulaGraph 的架构图如上,引用自论文:Wu, Min, et al. "Nebula Graph: An open source distributed graph database." arXiv preprint arXiv:2206.07278 (2022).
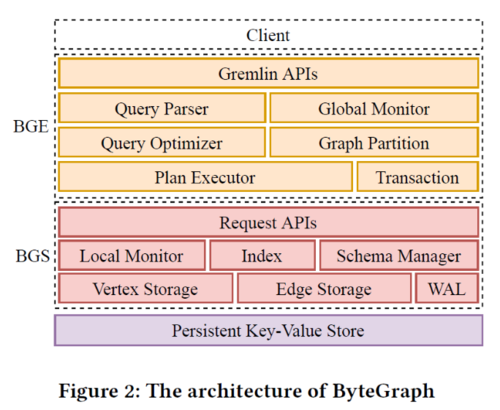
图引用自:Li C, Chen H, Zhang S, et al. ByteGraph: A High-Performance Distributed Graph Database in ByteDance [J].
为了处理超级节点和负载均衡(第二个问题),再引入一层数据结构 B+tree,将大的超级节点拆分成更多小的处理单元,并工程上实现线程间的负载切换,和独立扩容计算层。对于第三个问题,通过引入细颗粒度的切片,单独实现部分切片的扩容

当然,这种方案也可以称为 “分布式”。
以上四种方案,在产品和技术层面做了不同的权衡,各种侧重以适合各自的用户业务场景。但它们都可以称为 “分布式”。
扩展阅读
图的切分问题:在单机上如何进行切图,已经得到了大量的研究。这里推荐工具 METIS (http://glaros.dtc.umn.edu/gkhome/metis/metis/overview)在分布式环境的切图是一个比 (fei) 较 (chang) 困难的问题。这里推荐一些业界的讨论:
关于 “伪分布式”(Pseudo-Distrubuted Mode)
一般来说,这是用单服务器上的运行模拟在多个服务器的运行;特别适合于学习或者调试。
关于图领域的综述
Sahu, S., Mhedhbi, A., Salihoglu, S., Lin, J., ¨Ozsu, M.T.: The ubiquity of large graphs and surprising challenges of graph processing: extended survey. VLDB J. 29(2-3), 595–618 (2020)
Sakr, S., Bonifati, A., Voigt, H., Iosup, A., Ammar, K., Angles, R., Yoneki: The future is big graphs: a community view on graph processing systems. Communications of the ACM 64(9), 62–71 (2021)
Disclaimer
1. 以上提到的技术方案,是作者的理解和分享,如有错误欢迎指出,并没有商业竞争目的。
2. 为了降低读者理解难度,做了很大程度的简化,并不表示原方案是如此简单。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



