
您好,我是湘王,这是我的慕课手记,欢迎您来,欢迎您再来~
上次把JVM的类加载过程粗略地过了一遍,今天再来看看JVM运行代码时,系统里发生了什么。
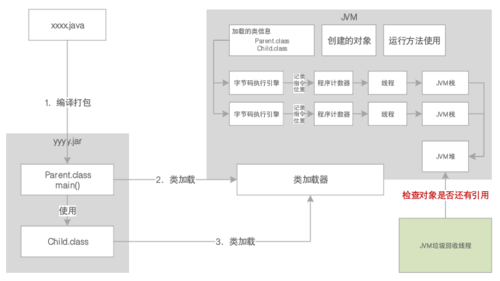
就像家里的柴、米、油、盐、酱、醋、茶要分别放在不同的缸子里一样,JVM也会把运行时需要的数据放在不同的「存储空间」里。JVM的存储空间大概都有这么些「家当」:方法区、计数器、栈、堆。
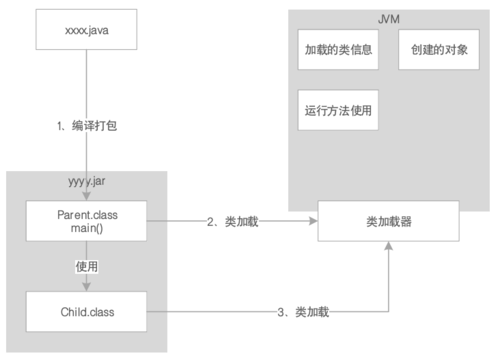
JDK1.8之前的版本中,称为“方法区”,代表JVM中的一块区域,主要存放从.class加载进来的类。而JDK1.8之后的版本中,改为“metaspace”(元数据空间):
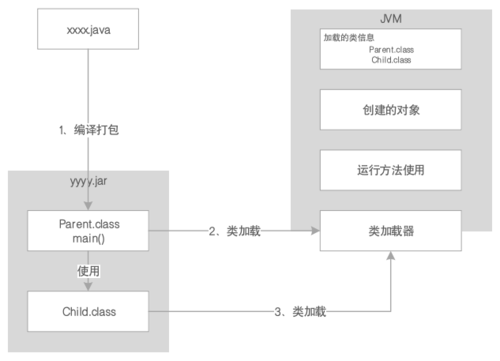
那么JVM又是怎么知道程序执行到了哪里,运行了几次,又是怎么被引用的呢?这时候程序计数器就出场了:它就是用来记录当前执行的字节码指令的位置的。
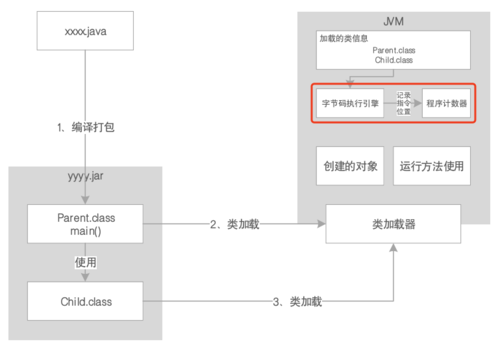
由于JVM是支持多线程的,所以每个线程都会有自己的程序计数器(它不是共用的话,这一点容易引起误会):
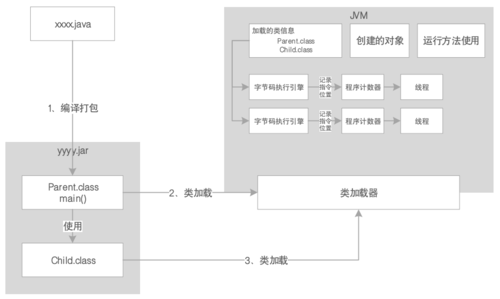
而线程是在「栈」中运行的:
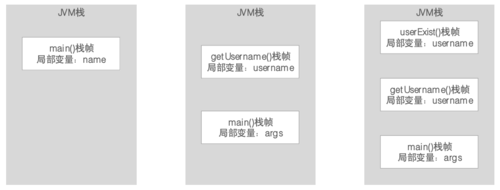
1、它保存每个方法内的局部变量等数据的区域,每个线程都有自己的JVM栈;
2、线程执行某个方法,就会对该方法的调用创建一个对应的栈帧;
3、栈帧里就有这个方法的局部变量表、操作数栈、链接等,可以说就是线程自己的小王国;
4、任何方法的调用,都遵循“先入栈,再出栈”的方式。
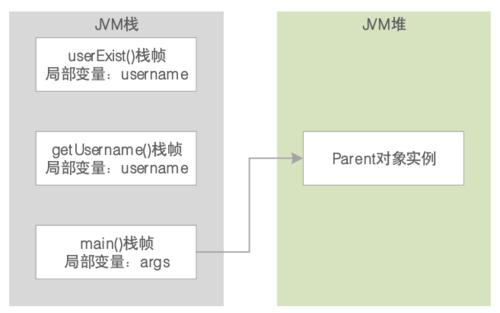
和「栈」不同,JVM堆是用来存放代码中创建的各种对象及其实例的地方。JVM栈中的局部变量只是一个引用地址(即指针),指向Java堆内存里实际存储的对象实例的地址。
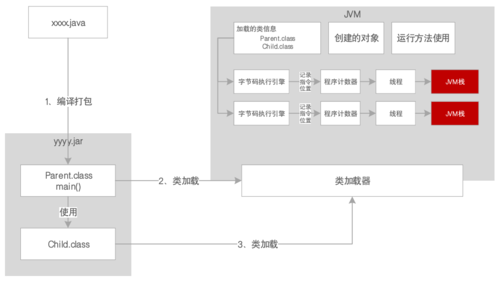
Java运行时,大致会经历这个过程:
1、JVM进程启动;
2、类加载器加载;
3、将加载的信息存放在JVM不同的内存区域;
4、执行main()方法;
5、在main线程中将main()方法入栈;
6、如果需要创建实例对象,则在JVM堆中创建;
7、由栈中的局部变量引用这个堆内存实例对象的地址;
8、执行各个不同方法的时候,依次入栈再出栈。
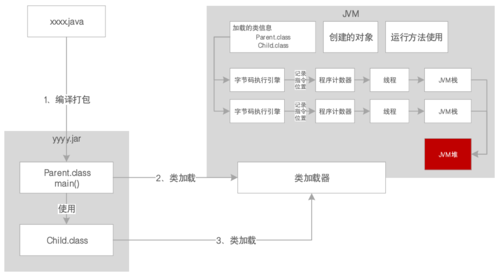
另外,在JDK底层API中,有些已经不是用Java代码写的了,如I/O、Socket、网络等。调用native方法时,也会通过类似Java虚拟机栈的栈帧完成。通过NIO中的allocateDirect这种API,可以在Java堆外分配空间,然后通过JVM里的DirectByteBuffer来引用和操作,它已经不属于JVM了。
既然有了这些家当,分配了内存,那么在Java堆中创建的对象实例,都是要占用内存资源的,而且内存资源是有限的。所以当资源不再被使用时,JVM通过一个后台自动运行的线程进行资源回收:垃圾回收(GC)机制。
针对JVM的特点,一些开发时需要注意的:
1、不要在for循环里创建对象,而在循环外面声明,for循环里对一个对象修改数据即可,这样就不会造成大量的Java堆内存被占用;
2、Object Header(4字节)+ Class Pointer(4字节)+ Fields(看存放类型),但是JVM内存占用是8的倍数,所以结果要向上取整到8的倍数;
3、实例变量得在创建类的实例对象时才会初始化,类的初始化阶段,仅仅是初始化类而已,跟对象无关,用new关键字才会构造一个对象出来;
4、类的class对象不是在准备阶段创建的,准备阶段是分配内存空间的;
5、自定义类加载器就是自己写一个类,继承ClassLoader类,重写类加载的方法,然后在代码里面可以用自己的类加载器将某个路径下的类加载到内存里来;
6、类加载器不是把jar包里的所有类一次性全部加载进去,而是首先加载包含main方法的主类(这个主类在启动时必须唯一指定),接着是运行代码的时候,需要用什么类就加载什么类。
感谢您的大驾光临!咨询技术、产品、运营和管理相关问题,请关注后留言。欢迎骚扰,不胜荣幸~
共同学习,写下你的评论
评论加载中...
作者其他优质文章


