
PDF文档是我们日常办公中使用最频繁的文档格式。但因为大多数PDF文档都包含很多页面图像或大量图片,这就导致PDF文档过大,在传输或者下载过程中速度会变慢,也会增加传输失败的风险,影响办公效率。因此我们需要对PDF文档进行压缩。本文将从以下两方面介绍如何通过Java应用程序压缩PDF文档,并附上Java代码供大家参考,希望能对你有所帮助。
压缩PDF文档中的内容及图片
压缩PDF文档中的高分辨率图片
使用工具: Free Spire.PDF for Java (免费版)
1.引入jar包
导入方法1:
手动引入。将 Free Spire.PDF for Java 下载到本地,解压,找到lib文件夹下的Spire.PDF.jar文件。在IDEA中打开如下界面,将本地路径中的jar文件引入Java程序:
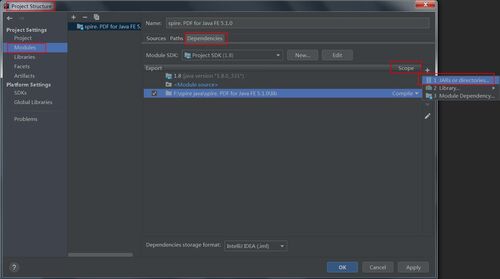
导入方法2:如果您想通过 Maven安装,则可以在 pom.xml 文件中添加以下代码导入 JAR 文件。
<repositories> <repository> <id>com.e-iceblue</id> <url>https://repo.e-iceblue.cn/repository/maven-public/</url> </repository> </repositories> <dependencies> <dependency> <groupId>e-iceblue</groupId> <artifactId>spire.pdf.free</artifactId> <version>5.1.0</version> </dependency> </dependencies>
压缩PDF文档具体步骤
此方法将对PDF文档中的所有文本内容以及图片进行压缩,详细步骤如下:
创建 PdfDocument 类的对象。
使用 PdfDocument.loadFromFile() 方法加载 PDF 文档。
使用 PdfDocument.getFileInfo().setIncrementalUpdate() 方法将IncrementalUpdate 设置为false。
使用 PdfDocument.setCompressionLevel() 方法将压缩级别设置为最佳,以压缩文档中的内容。 您可以从 PdfCompressionLevel 枚举中选择其他一些级别。
循环遍历文档中的页面,使用 PdfPageBase.getImagesInfo() 方法获取每个页面的图像信息集合。
遍历集合中的所有项目,并使用 PdfBitmap.setQuality() 方法压缩特定图像的质量。
使用 PdfPageBase.replaceImage() 方法将原始图像替换为压缩图像。
使用 PdfDocument.saveToFile() 方法将文档保存到另一个 PDF 文件。
完整代码
【Java】
import com.spire.pdf.PdfCompressionLevel;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.exporting.PdfImageInfo;
import com.spire.pdf.graphics.PdfBitmap;
public class CompressPdfDocument {
public static void main(String[] args) {
//创建 PdfDocument 类的对象
PdfDocument doc = new PdfDocument();
//加载 PDF 文档
doc.loadFromFile("测试文档.pdf");
//将IncrementalUpdate设置为false
doc.getFileInfo().setIncrementalUpdate(false);
//将压缩级别设置为最佳
doc.setCompressionLevel(PdfCompressionLevel.Best);
//循环遍历文档中的页面
for (int i = 0; i < doc.getPages().getCount(); i++) {
//获取指定页面
PdfPageBase page = doc.getPages().get(i);
//获取每个页面的图像信息集合
PdfImageInfo[] images = page.getImagesInfo();
//遍历集合中的项目
if (images != null && images.length > 0)
for (int j = 0; j < images.length; j++) {
//获取特定图片
PdfImageInfo image = images[j];
PdfBitmap bp = new PdfBitmap(image.getImage());
//设置压缩质量
bp.setQuality(20);
//将原始图像替换为压缩图像
page.replaceImage(j, bp);
}
//保存文件
doc.saveToFile("压缩PDF文档.pdf");
doc.close();
}
}
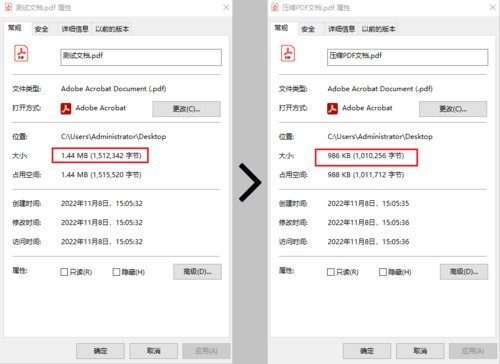
}效果对比图
压缩 PDF 文档中的高分辨率图像
本方法只针对高分辨率图像进行无损压缩,而低分辨率图像将不再进行压缩。详细步骤如下:
创建 PdfDocument 类的对象。
使用 PdfDocument.loadFromFile() 方法加载 PDF 文档。
使用 PdfDocument.getFileInfo().setIncrementalUpdate() 方法将 IncrementalUpdate 设置为 false。
声明一个 PdfPageBase 变量。循环遍历页面并使用 PdfDocument.getPages().get() 方法获取特定页面。
循环遍历页面中的图像。并使用 page.tryCompressImage(info.Index) 方法压缩高分辨率图像。
使用 PdfDocument.saveToFile() 方法将文档保存到另一个 PDF 文件。
完整代码
【Java】
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.exporting.PdfImageInfo;
public class CompressPDFImage {
public static void main(String[] args) {
//创建 PdfDocument 类的对象
PdfDocument doc = new PdfDocument
//加载 PDF 文档
doc.loadFromFile("示例文档.pdf");
//将IncrementalUpdate设置为false
doc.getFileInfo().setIncrementalUpdate(false);
//声明一个 PdfPageBase 变量
PdfPageBase page;
//循环遍历页面
for (int i = 0; i < doc.getPages().getCount(); i++) {
//获取指定页面
page = doc.getPages().get(i);
if (page != null) {
if(page.getImagesInfo() != null){
//循环遍历页面中的图像
for (PdfImageInfo info: page.getImagesInfo()) {
//使用tryCompressImage方法压缩高分辨率图像
page.tryCompressImage(info.getIndex());
}
}
}
}
//保存文件
doc.saveToFile("输出结果.pdf");
}
}效果对比图

—本文完—
共同学习,写下你的评论
评论加载中...
作者其他优质文章


