
统计机器翻译(SMT)工具Moses在Ubuntu上的安装及使用(使用篇)
准备双语平行语料
Moses可以翻译任意两种语言,其准确率很大程度取决于平行语料库的质量和规模,如何在低资源语料下提升机器翻译质量同样也是神经机器翻译面临的难题。
下面我们将介绍Moses在开源平行语料上的训练和翻译流程,构建一个中文翻译成英文的翻译系统。
切换成root账户避免权限问题
sudo su
首先在 moses 目录下新建语料库文件夹corpus。
mkdir /home/moses/corpus
机器翻译研讨会(Workshop on Machine Translation, WMT)是世界顶级机器翻译赛事,在其官网公布了历年收录的论文以及数据集,公开了最新的翻译技术。本文选用WMT2022的GENERAL MT (NEWS)翻译任务所使用的中英平行语料。
cd /home/moses/corpus
wget https://data.statmt.org/news-commentary/v16/training/news-commentary-v16.en-zh.tsv.gz
gzip -d ./news-commentary-v16.en-zh.tsv.gz
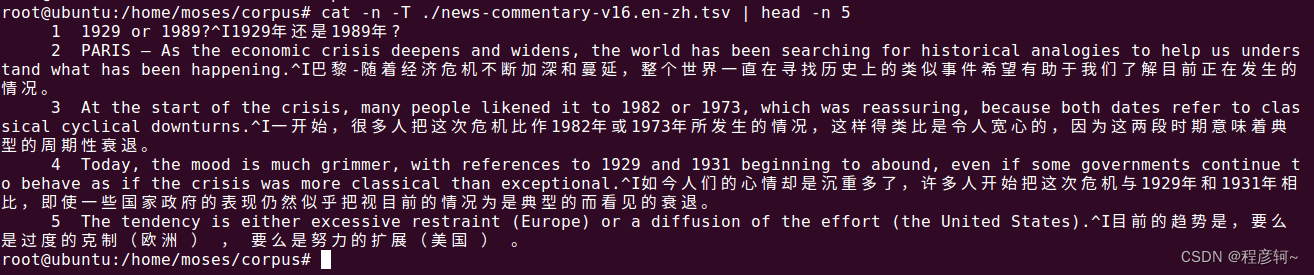
使用 cat 命令查看语料,可以发现语料每一行的英文和中文是用 ^I 即 tab 分割的,moses 训练时需要两个单语文件,因此需要将数据集分割成单独的中文、英文数据集。
cat -n -T ./news-commentary-v16.en-zh.tsv | head -n 5
此外,这份语料包含32万余行,用来演示训练流程的话用不了这么多,因此我们先分割数据集,然后再拆分单语语料。
使用 sed 分割数据集:
# 提取4万行做训练集、5千行做验证集、5千行做训练集,比例8:1:1
sed -n '1,40000p' ./news-commentary-v16.en-zh.tsv > corpus.train
sed -n '40001,45000p' ./news-commentary-v16.en-zh.tsv > corpus.vlidation
sed -n '45001,50000p' ./news-commentary-v16.en-zh.tsv > corpus.test
使用 awk 提取单语文件:
awk -F '[\t]' '{print $1}' ./corpus.train > ./train.en
awk -F '[\t]' '{print $2}' ./corpus.train > ./train.zh
awk -F '[\t]' '{print $1}' ./corpus.vlidation > ./vlidation.en
awk -F '[\t]' '{print $2}' ./corpus.vlidation > ./vlidation.zh
awk -F '[\t]' '{print $1}' ./corpus.test > ./test.en
awk -F '[\t]' '{print $2}' ./corpus.test > ./test.zh
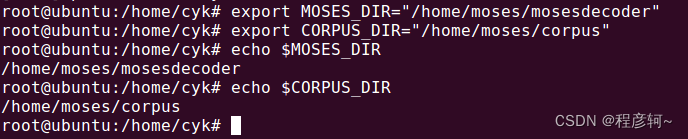
为了简化命令,将 mosesdecoder 目录和语料库目录定义为环境变量,注意这里我没把变量写到配置文件中,shell终端关闭后路径变量会失效,需要重新定义:
export MOSES_DIR="/home/moses/mosesdecoder"
export CORPUS_DIR="/home/moses/corpus"
使用 echo $MOSES_DIR 和 echo $CORPUS_DIR 可以查看路径。
数据预处理
数据预处理主要包含分词(tokenisation)、大小写统一(truecasing)、整理句子长度(cleaning)。
分词处理
脚本 tokenizer.perl,默认将标点符号与单词分开,其参数如下:
-b # disable Perl buffering. 禁用 `perl` 的缓冲区,可以参照 [Perl 的内置变量$|](https://www.cnblogs.com/yanzibuaa/p/7692444.html)。
-l # 用于指定要处理的语言(language),支持的语言有en(英语)、fr(法语)、it(意大利语)、ga(爱尔兰语)、ca(加泰罗尼亚语)、so(索马里语,不确定)、tdt(德顿语)、fi(芬兰语)、sv(瑞典语),如果没指定 `-l` 参数或者指定的语言不存在会默认按照英语处理。
-q # 添加该参数后不打印 `tokenizer.perl` 的版本信息、将要处理的语言缩写、线程数量,默认打印以上信息。
-h # 获取帮助。
-x # don't try to tokenize XML/HTML tag lines. 不要对存在 `XML/HTML` 标签的行进行分词(存疑)。
-a # aggressive hyphen splitting. 用于处理连字符,例如 `state-of-the-art` 将拆分为 `state @-@ of @-@ the @-@ art` 。
-time # enable processing time calculation. 打印脚本处理分词时的耗时。
-protected FILE # specify file with patters to be protected in tokenisation.
-threads # 用于指定程序处理时的线程数量。
-lines # 指定每个线程所处理的句子树,默认2000行。
-penn # use Penn treebank-like tokenization. 使用与宾州树库相似的分词方法。
-no-escape # don't perform HTML escaping on apostrophy, quotes, etc. 不对撇号、引号等执行HTML转义,不指定这个参数的话,脚本默认将撇号、单引号等符号处理成 `html` 标记,加上这个参数就会跳过这些符号。如执行echo " 'state-of-the-art' 1 | 2 [ 3 ] 3<4 4>3 3=3 & ''5'' " | $MOSES_DIR/scripts/tokenizer/tokenizer.perl -q,处理结果为:"'state-of-the-art ' 1 | 2 [ 3 ] 3 < 4 4 > 3 3 = 3 & ' '5 ' '",加上 "-no-escape" 后,则原样返回。
对英文进行分词:
$MOSES_DIR/scripts/tokenizer/tokenizer.perl -l en -threads 2 < $CORPUS_DIR/train.en > $CORPUS_DIR/train.tok.en
$MOSES_DIR/scripts/tokenizer/tokenizer.perl -l en -threads 2 < $CORPUS_DIR/vlidation.en > $CORPUS_DIR/vlidation.tok.en
$MOSES_DIR/scripts/tokenizer/tokenizer.perl -l en -threads 2 < $CORPUS_DIR/test.en > $CORPUS_DIR/test.tok.en

可以看出 tokenizer.perl 支持的语言有个明显的特点,那就是都可以天然以空格进行分词,中文之间没有空格,因此需要另外处理。
这里使用 jieba 进行分词,Ubuntu 16.04 LTS 自带 python 2.7.12 和 python 3.5.2。默认没有 pip 命令,因此先安装 pip ,再用 pip 安装 jieba ,默认安装的 pip 版本有些低了,不过不影响安装 jieba,就不再升级了。
apt-get install python3-pip
pip3 install jieba
使用下面的 python 代码进行简单的分词处理,使用 vi 新建 tokenizer.py,键入 i 进入插入模式,把代码粘贴到 tokenizer.py 中。
cd $CORPUS_DIR
vi ./tokenizer.py
tokenizer.py 中的代码:
# coding:utf-8
import jieba
import os
file_list = ['train', 'vlidation', 'test']
for file in file_list:
with open(file="/home/moses/corpus/" + file + '.zh', mode="r", encoding="utf-8") as f1:
sentences=f1.readlines()
print(type(sentences))
f1.close()
with open(file="/home/moses/corpus/" + file + '.tok.zh', mode="w", encoding="utf-8") as f2:
for sentence in sentences:
f2.write(' '.join(jieba.lcut(sentence)))
f2.close()
运行代码
python3 $CORPUS_DIR/tokenizer.py

中文分词结果:

大小写转换(非必须)
这一步不是直接将英文全部大写或者小写,而是先训练获得语料的统计学信息,再统一具体单词的大写、小写格式。
首先进行训练:
--model:用于指定训练完成后模型文件的保存位置及名称;
--corpus:参与训练的语料。
$MOSES_DIR/scripts/recaser/train-truecaser.perl --model $CORPUS_DIR/train.truecase-model.en --corpus $CORPUS_DIR/train.tok.en
$MOSES_DIR/scripts/recaser/train-truecaser.perl --model $CORPUS_DIR/train.truecase-model.zh --corpus $CORPUS_DIR/train.tok.zh
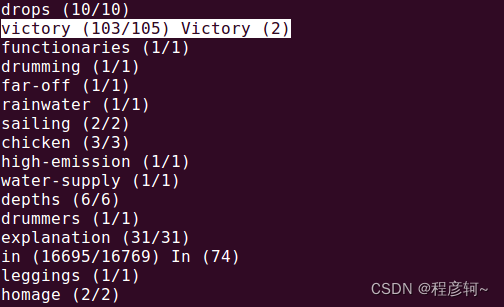
corpus 目录下新增两个模型文件 train.truecase-model.en 和 train.truecase-model.zh 。这两个模型文件分别统计了英文语料、中文语料中英文单词出现的总次数、作为小写形式出现的次数、作为大写形式出现的次数。
打开 train.truecase-model.en 可以看到 victory 出现了 105 次,其小写形式出现 103 次,大写形式出现 2 次。
依据这两个模型文件对 train.tok.(en/zh) 进行大小写转换:
$MOSES_DIR/scripts/recaser/truecase.perl --model $CORPUS_DIR/train.truecase-model.en < $CORPUS_DIR/train.tok.en > $CORPUS_DIR/train.truecaser.en
$MOSES_DIR/scripts/recaser/truecase.perl --model $CORPUS_DIR/train.truecase-model.zh < $CORPUS_DIR/train.tok.zh > $CORPUS_DIR/train.truecaser.zh
$MOSES_DIR/scripts/recaser/truecase.perl --model $CORPUS_DIR/train.truecase-model.en < $CORPUS_DIR/vlidation.tok.en > $CORPUS_DIR/vlidation.truecaser.en
$MOSES_DIR/scripts/recaser/truecase.perl --model $CORPUS_DIR/train.truecase-model.zh < $CORPUS_DIR/vlidation.tok.zh > $CORPUS_DIR/vlidation.truecaser.zh
$MOSES_DIR/scripts/recaser/truecase.perl --model $CORPUS_DIR/train.truecase-model.en < $CORPUS_DIR/test.tok.en > $CORPUS_DIR/vlidation.truecaser.en
$MOSES_DIR/scripts/recaser/truecase.perl --model $CORPUS_DIR/train.truecase-model.zh < $CORPUS_DIR/test.tok.zh > $CORPUS_DIR/vlidation.truecaser.zh
corpus 目录下新增两个文件 (train/vlidation/test).truecaser.en 和 (train/vlidation/test).truecaser.zh 便是转换处理后的结果。
语句清理
这一步可以清理语料库中的空行、指定语句的最大长度、删除明显不对齐的语句。
脚本使用:clean-corpus-n.perl [-ratio n] corpus l1 l2 clean-corpus min max [lines retained file]
-ratio 的 n 默认为 9,这个参数与删除双语平行语料中明显不对齐的句子这一功能有关,脚本会比较平行语料句子长度(分词个数)的比值;
corpus 指要处理的文件(不带语言后缀,如 en、zh ),l1 和 l2 是语言后缀;
clean-corpus 指输出的文件名,脚本会自动加上各自的语言后缀,min、max 用来限定语句的长度区间;
这个脚本还有一些参数没列出来,可以加上 lc=1 将英文全部变成小写。如果设置 lc 的话,前面的 truecasing 步骤也没必要做了,那么测试的时候也必须把英文转成小写,否则大写单词会导致更多的未登录词。
$MOSES_DIR/scripts/training/clean-corpus-n.perl -ratio 5 $CORPUS_DIR/train.truecaser en zh $CORPUS_DIR/train.clean 8 80

corpus 目录下新增两个文件 train.clean.en 和 train.clean.zh 。
训练语言模型
语言模型是翻译流畅性、准确性的关键,它是依据目标语言来构建的,本文中目标语言是英文。
创建语言模型的工作目录并加入环境变量:
mkdir /home/moses/lm
export LM_DIR="/home/moses/lm"
在安装篇中提到,Moses 可以集成多种语言模型,如 Irstlm、Randlm、Nplm、Srilm 等,并且 Moses 本身集成了 KenLM,每种语言模型都有其优缺点,可以按实际情况选用。Moses手册 在 2.1.2 节中提到 “Personally, I only use IRSTLM as a query tool in this way if the LM n-gram order is over 7. In most situation, I use KenLM because KenLM is multi-threaded and faster.”
使用其他语言模型的方法在手册中也有介绍,此处使用KenLM中的 lmplz 来构建一个 3 元语言模型,此处使用到的语料是 train.truecaser.en ,即未经过语句清理步骤的单语文件,可能是为了涵盖更多的语料吧。
lmplz 的参数如下:
lmplz
-h # 获取帮助信息
-o [N-gram] # 指定训练的是几元模型,唯一一个必选项。
--skip_symbols # 将 `<s>`, `</s>` 和 `<unk>` 视作空白符。
-T [temp_path/temp_file] # 指定临时文件的存放目录,推荐设置该项。
-S [70%] # 限制内存的占用量,我曾遇见过不限制内存占用程序报错的情况,推荐设置该项。
--minimum_block [8K/1M] # Minimum block size to allow
--sort_block 64M # Size of IO operations for sort (determines arity)
--block_count 1 # Block count (per order)
--vocab_estimate [100000] # 设置词表大小的预估值,以便于脚本计算内存占用和预先确定哈希表。
--vocab_pad [BIG_NUMBER] # 如果你有比较不同词表之间的困惑度的需求,请把此项设置为一个大于词表大小的数,脚本将用 <unk> 把词表填充至BIG_NUMBER那么大,该项需要与--interpolate_unigrams 配合使用。
--verbose_header # 在输出的arpa文件上添加分词数量、平滑类型等统计信息。
--text [train_char.txt] # 输入训练模型所需的语料,可以与 Linux 标准输入命令 '<' 相互替换。
--arpa [arpa.pt] # 输出训练好的模型文件,可以与 Linux 标准输出命令 '>' 相互替换。
--intermediate [intermediate_file] # Write ngrams to intermediate files. Turns off ARPA output (which can be reactivated by --arpa file). Forces --renumber on.
--renumber # Rrenumber the vocabulary identifiers so that they are monotone with the hash of each string. This is consistent with the ordering used by the trie data structure.
--collapse_values # Collapse probability and backoff into a single value, q that yields the same sentence-level probabilities. See http://kheafield.com/professional/edinburgh/rest_paper.pdf for more details, including a proof.
--prune [0 4 4 4] # 指定剪枝参数,0 4 4 4表示2-gram,3-gram,4-gram中频率小于4的都剪枝掉,这里的几个参数必须为非递减,第一个必须为0。
--limit_vocab_file [vocab_file_path/vocab_file] # 指定用户自己的词表文件,词表中的单词需要用空格分隔,不在词表中的词汇将被删除,可以搭配 --prune 使用。
--discount_fallback [0.5 1 1.5] # 如果出现下面的提示,可以指定此项参数进行平滑处理。
# "Could not calculate Kneser-Ney discounts for 3-grams with adjusted count 4 because we didn't observe any 3-grams with adjusted count 3; Is this small or artificial data? Try deduplicating the input. To override this error for e.g. a class-based model, rerun with --discount_fallback. https://www.codenong.com/cs106070924/ https://zhuanlan.zhihu.com/p/63884335 。
$MOSES_DIR/bin/lmplz -o 3 < $CORPUS_DIR/train.truecaser.en > $LM_DIR/train.arpa.en
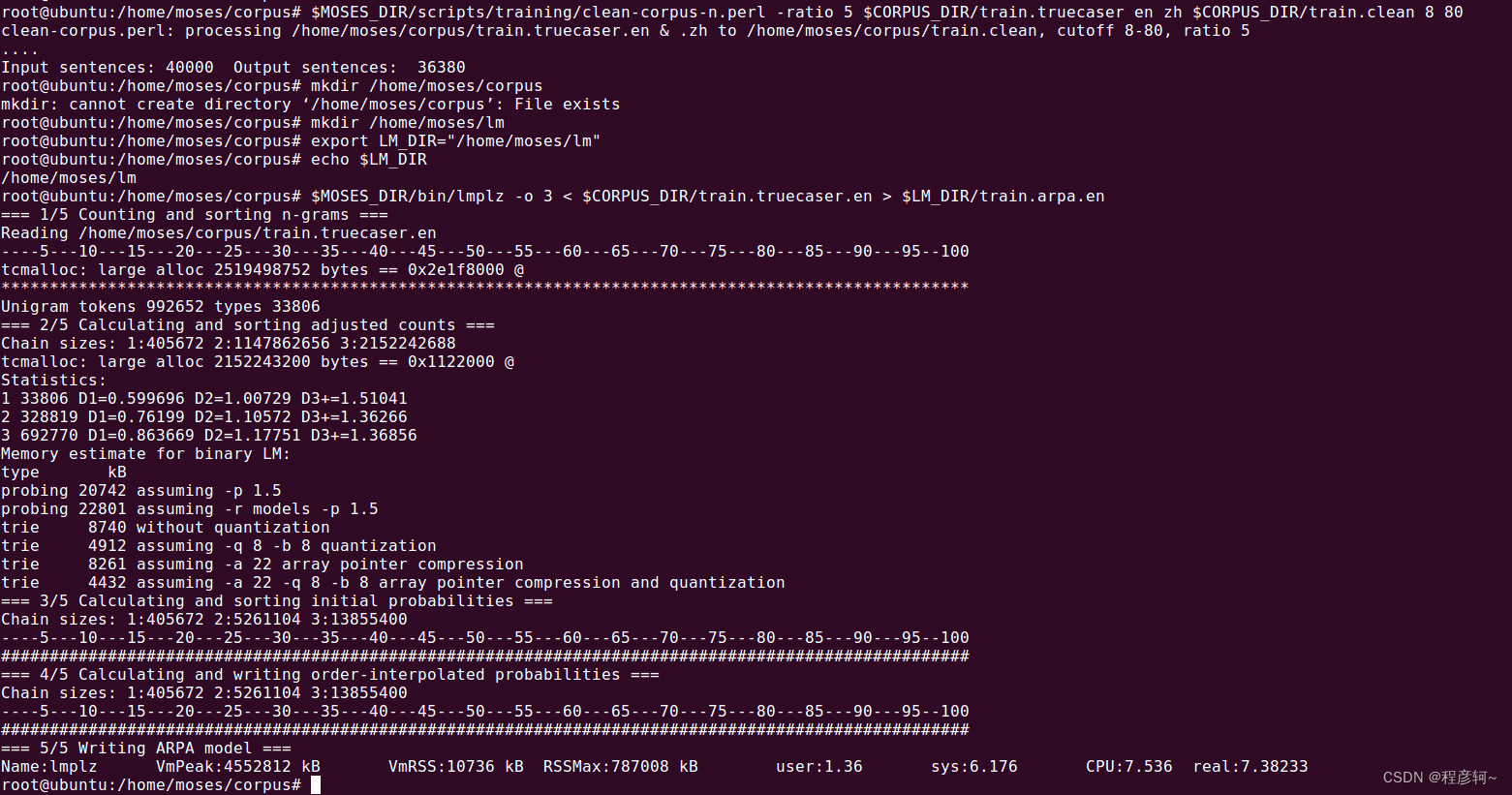
在 lm 目录下保存着训练好的语言模型 train.arpa.en 。
为了加快模型的运行速度,将语言模型二值化:
$MOSES_DIR/bin/build_binary $LM_DIR/train.arpa.en $LM_DIR/train.arpa.blm.en

用 query 脚本查询一下语言模型:
echo "is this an English sentence ?" | $MOSES_DIR/bin/query $LM_DIR/train.arpa.blm.en

训练翻译系统
创建翻译工作目录
mkdir /home/moses/Translate_working
export Translate_DIR="/home/moses/Translate_working"
使用 train-model.perl 训练翻译系统,脚本默认依次完成以下 9 个步骤,你也可以指定完成其中的某一段步骤,train-model.perl 的参数相当丰富,有兴趣的可以直接将源码和Moses官网上的介绍对照着看,在页面左侧的目录部分第 4 章,如果有时间的话会单出一期博客介绍这些参数。
Steps: (--first-step to --last-step)
(1) prepare corpus # 准备语料
(2) run GIZA # 运行GIZA
(3) align words # 进行词对齐
(4) learn lexical translation
(5) extract phrases # 抽取短语
(6) score phrases # 给抽取的短语进行打分(概率值)
(7) learn reordering model #
(8) learn generation model
(9) create decoder config file
本教程提到的参数:
-cores 2 # 使用2个核心加速训练,看自己电脑有多少核心了
-root-dir # 训练的工作目录,会在指定目录生成 train 文件夹
-corpus # 训练所需语料
-f # 源语言后缀
-e # 目标语言后缀
-alignment # 指定词对齐时的启发式探索方法
-reordering # 指定重排序模型
-lm 0:3:$LM_DIR/train.arpa.blm.en:8 # use --lm factor:order:filename to specify at least one language model
-external-bin-dir # 指定词对齐时外部可执行文件的路径(比如GIZA++)
nohup nice $MOSES_DIR/scripts/training/train-model.perl -cores 2 -root-dir $Translate_DIR/train -corpus $CORPUS_DIR/train.clean -f zh -e en -alignment grow-diag-final-and -reordering msd-bidirectional-fe -lm 0:3:$LM_DIR/train.arpa.blm.en:8 -external-bin-dir $MOSES_DIR/tools >& $Translate_DIR/training.out &

nohup 与 & 可以在后台静默执行任务,执行后返回了一个进程号 6338 ,用 jobs -l 查询后台执行的任务。

同时在 $Translate_working 目录下会生成一个训练文件夹 train 和一个训练日志文件 training.out,并且你在 train/model 目录下还能找到一个 moses.ini 文件,翻译时就要依靠这个文件来进行解码目标语言。

这个期间可以去干点儿别的活了,调出 top 指令监控 CPU 状态,可以看到脚本程序正在调用 GIZA++,我这边训练耗时 22 分钟。
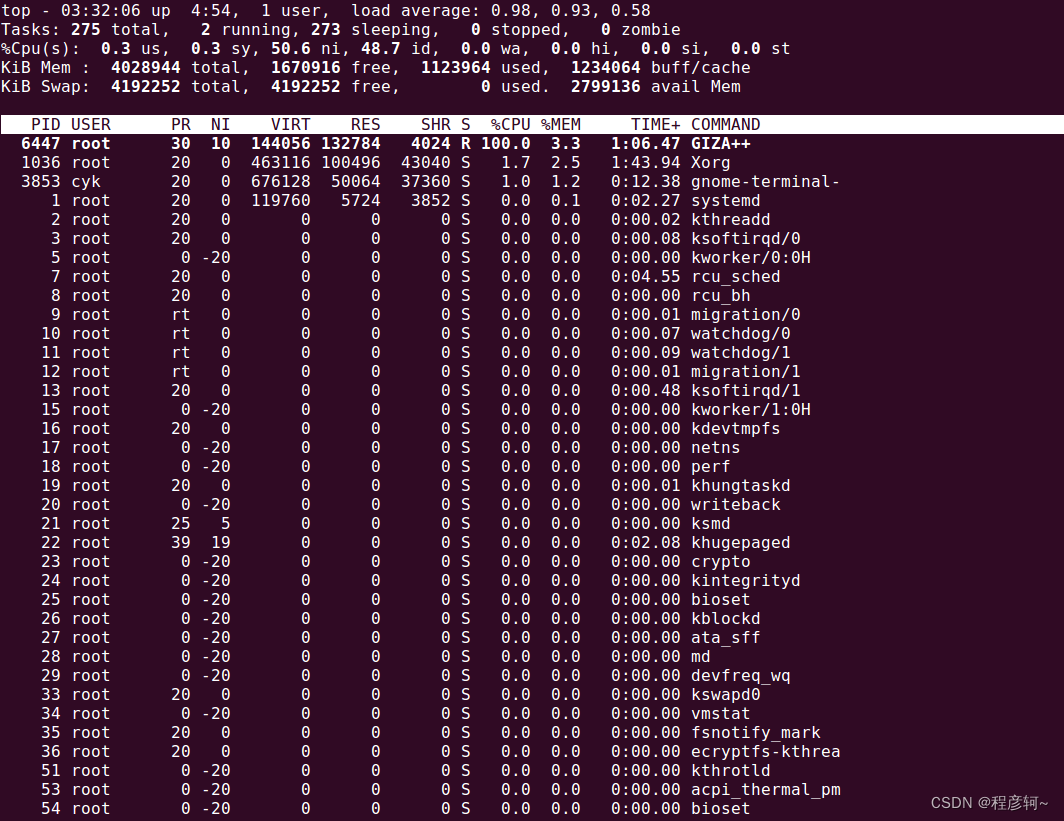
调试语言模型
我们用之前划分的验证集进行调试,数据集的中、英文预处理已经全做过了,官方手册在调试环节没对语料进行语句清理。
--decoder-flags 指定线程数量
cd $Translate_DIR
nohup nice $MOSES_DIR/scripts/training/mert-moses.pl $CORPUS_DIR/vlidation.truecaser.zh $CORPUS_DIR/vlidation.truecaser.en $MOSES_DIR/bin/moses $Translate_DIR/train/model/moses.ini --mertdir $MOSES_DIR/bin/ --decoder-flags="-threads 2" &> $Translate_DIR/mert.out &
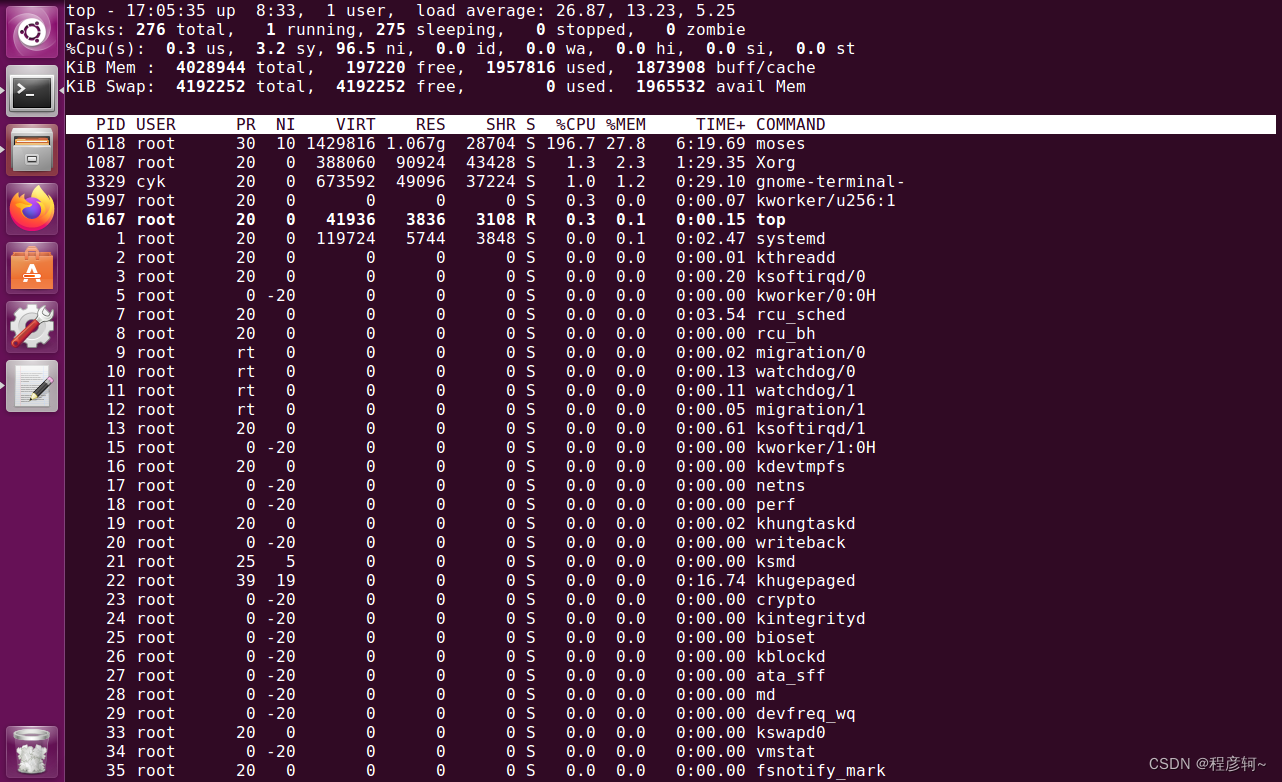
调优耗时3到4个小时。调优的最终结果仍然是一个 moses.ini 文件,该文件保存在$Translate_DIR/mert-work目录下,这个目录还保存着每轮训练的参数。
测试语言模型
现在,一个完整的翻译模型就构建好了,可以用下面的命令翻译句子。
echo "拥有 大量 学校 、 学院 、 IT 企业 、 工厂 和 商业 设施 的 印度 第四 大城市 陷入 瘫痪 的确 很难 想象 。 " | $MOSES_DIR/bin/moses -f $Translate_DIR/mert-work/moses.ini
输出最优翻译为:
BEST TRANSLATION: have a lot of schools , College , IT companies , factories and business facilities of India ’ s fourth big cities have paralyzed does it is hard to imagine .
完整输出如下:
Defined parameters (per moses.ini or switch):
config: /home/moses/Translate_working/mert-work/moses.ini
distortion-limit: 6
feature: UnknownWordPenalty WordPenalty PhrasePenalty PhraseDictionaryMemory name=TranslationModel0 num-features=4 path=/home/moses/Translate_working/train/model/phrase-table.gz input-factor=0 output-factor=0 LexicalReordering name=LexicalReordering0 num-features=6 type=wbe-msd-bidirectional-fe-allff input-factor=0 output-factor=0 path=/home/moses/Translate_working/train/model/reordering-table.wbe-msd-bidirectional-fe.gz Distortion KENLM name=LM0 factor=0 path=/home/moses/lm/train.arpa.blm.en order=3
input-factors: 0
mapping: 0 T 0
threads: 32
weight: LexicalReordering0= 0.0330045 0.0711571 0.0421258 0.0540382 0.0189403 0.188173 Distortion0= 0.0147038 LM0= 0.0742647 WordPenalty0= -0.25824 PhrasePenalty0= 0.0709767 TranslationModel0= 0.0342632 0.0325675 0.0542782 0.0532668 UnknownWordPenalty0= 1
line=UnknownWordPenalty
FeatureFunction: UnknownWordPenalty0 start: 0 end: 0
line=WordPenalty
FeatureFunction: WordPenalty0 start: 1 end: 1
line=PhrasePenalty
FeatureFunction: PhrasePenalty0 start: 2 end: 2
line=PhraseDictionaryMemory name=TranslationModel0 num-features=4 path=/home/moses/Translate_working/train/model/phrase-table.gz input-factor=0 output-factor=0
FeatureFunction: TranslationModel0 start: 3 end: 6
line=LexicalReordering name=LexicalReordering0 num-features=6 type=wbe-msd-bidirectional-fe-allff input-factor=0 output-factor=0 path=/home/moses/Translate_working/train/model/reordering-table.wbe-msd-bidirectional-fe.gz
Initializing Lexical Reordering Feature..
FeatureFunction: LexicalReordering0 start: 7 end: 12
line=Distortion
FeatureFunction: Distortion0 start: 13 end: 13
line=KENLM name=LM0 factor=0 path=/home/moses/lm/train.arpa.blm.en order=3
FeatureFunction: LM0 start: 14 end: 14
Loading UnknownWordPenalty0
Loading WordPenalty0
Loading PhrasePenalty0
Loading LexicalReordering0
Loading table into memory...done.
Loading Distortion0
Loading LM0
Loading TranslationModel0
Start loading text phrase table. Moses format : [19.136] seconds
Reading /home/moses/Translate_working/train/model/phrase-table.gz
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
****************************************************************************************************
Created input-output object : [40.289] seconds
Translating: 拥有 大量 学校 、 学院 、 IT 企业 、 工厂 和 商业 设施 的 印度 第四 大城市 陷入 瘫痪 的确 很难 想象 。
Line 0: Initialize search took 0.000 seconds total
Line 0: Collecting options took 0.001 seconds at moses/Manager.cpp Line 141
Line 0: Search took 0.248 seconds
have a lot of schools , College , IT companies , factories and business facilities of India ’ s fourth big cities have paralyzed does it is hard to imagine .
BEST TRANSLATION: have a lot of schools , College , IT companies , factories and business facilities of India ’ s fourth big cities have paralyzed does it is hard to imagine . [11111111111111111111111] [total=-8.760] core=(0.000,-31.000,17.000,-16.013,-40.065,-19.059,-46.512,-9.511,0.000,0.000,-9.699,0.000,0.000,0.000,-158.466)
Line 0: Decision rule took 0.000 seconds total
Line 0: Additional reporting took 0.000 seconds total
Line 0: Translation took 0.250 seconds total
Name:moses VmPeak:2846012 kB VmRSS:388884 kB RSSMax:2562996 kB user:40.388 sys:1.444 CPU:41.832 real:41.898
加速翻译模型的运行
不过,你会发现运行上述命令的速度非常慢。
Created input-output object : [40.289] seconds
可以利用脚本 processPhraseTableMin 二进制化短语表和重排序表来解决这个问题,将它们编译成一种可以快速加载的格式,参见。
processPhraseTableMin 参数:
-in (string) -- input table file name
-out (string) -- prefix of binary table file
-nscores (int) -- number of score components in phrase table
-no-alignment-info -- do not include alignment info in the binary phrase table
-threads (int) -- number of threads used for conversion
-T (string) -- path to custom temporary directory
创建二值化文件的存放目录 binarised-model:
mkdir $Translate_DIR/binarised-model
$MOSES_DIR/bin/processPhraseTableMin -in $Translate_DIR/train/model/phrase-table.gz -out $Translate_DIR/binarised-model/phrase-table -nscores 4 -threads 8
$MOSES_DIR/bin/processLexicalTableMin -in $Translate_DIR/train/model/reordering-table.wbe-msd-bidirectional-fe.gz -out $Translate_DIR/binarised-model/reordering-table -threads 8
如果出现报错信息:processPhraseTableMin: No such file or directory, 那么请确保在编译 moses 时将 cmph 集成进来。
然后复制调优时产生的 moses.ini 到 $Translate_DIR/binarised-model 目录下。
cp $Translate_DIR/mert-work/moses.ini $Translate_DIR/binarised-model
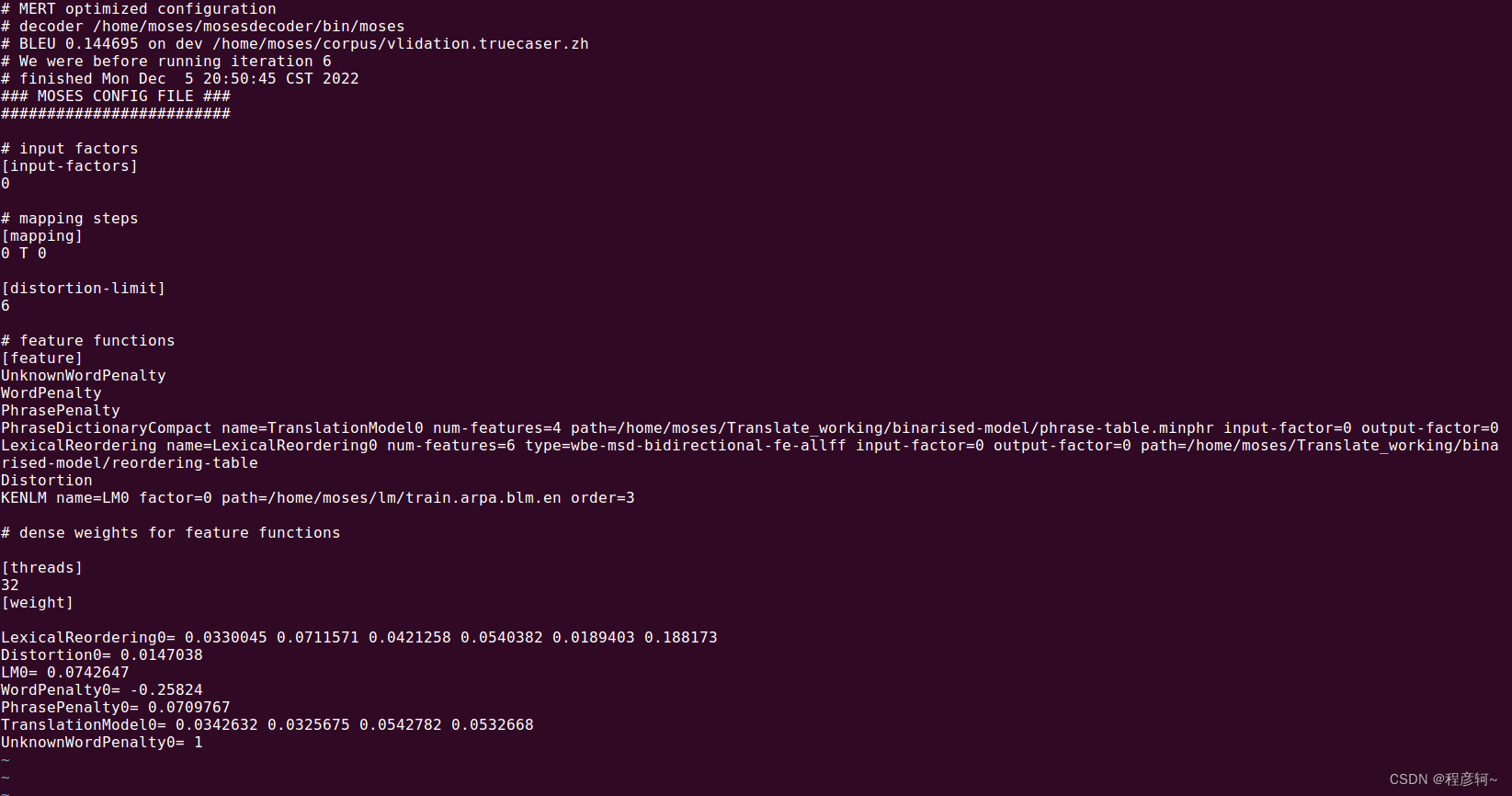
最后,修改 binarised-model 目录下 moses.ini 中的配置项:
1、将 PhraseDictionaryMemory 改为 PhraseDictionaryCompact ,其 path 路径修改为:path=/home/moses/Translate_working/binarised-model/phrase-table.minphr;
2、将 LexicalReordering 中的 path 修改为:path=/home/moses/Translate_working/binarised-model/reordering-table。
修改好的配置如图所示:
按下面命令再运行一次,翻译结果立刻就出来了。
Created input-output object : [0.099] seconds
echo "拥有 大量 学校 、 学院 、 IT 企业 、 工厂 和 商业 设施 的 印度 第四 大城市 陷入 瘫痪 的确 很难 想象 。 " | $MOSES_DIR/bin/moses -f $Translate_DIR/binarised-model/moses.ini
完整的输出为:
Defined parameters (per moses.ini or switch):
config: /home/moses/Translate_working/binarised-model/moses.ini
distortion-limit: 6
feature: UnknownWordPenalty WordPenalty PhrasePenalty PhraseDictionaryCompact name=TranslationModel0 num-features=4 path=/home/moses/Translate_working/binarised-model/phrase-table.minphr input-factor=0 output-factor=0 LexicalReordering name=LexicalReordering0 num-features=6 type=wbe-msd-bidirectional-fe-allff input-factor=0 output-factor=0 path=/home/moses/Translate_working/binarised-model/reordering-table Distortion KENLM name=LM0 factor=0 path=/home/moses/lm/train.arpa.blm.en order=3
input-factors: 0
mapping: 0 T 0
threads: 32
weight: LexicalReordering0= 0.0330045 0.0711571 0.0421258 0.0540382 0.0189403 0.188173 Distortion0= 0.0147038 LM0= 0.0742647 WordPenalty0= -0.25824 PhrasePenalty0= 0.0709767 TranslationModel0= 0.0342632 0.0325675 0.0542782 0.0532668 UnknownWordPenalty0= 1
line=UnknownWordPenalty
FeatureFunction: UnknownWordPenalty0 start: 0 end: 0
line=WordPenalty
FeatureFunction: WordPenalty0 start: 1 end: 1
line=PhrasePenalty
FeatureFunction: PhrasePenalty0 start: 2 end: 2
line=PhraseDictionaryCompact name=TranslationModel0 num-features=4 path=/home/moses/Translate_working/binarised-model/phrase-table.minphr input-factor=0 output-factor=0
FeatureFunction: TranslationModel0 start: 3 end: 6
line=LexicalReordering name=LexicalReordering0 num-features=6 type=wbe-msd-bidirectional-fe-allff input-factor=0 output-factor=0 path=/home/moses/Translate_working/binarised-model/reordering-table
Initializing Lexical Reordering Feature..
FeatureFunction: LexicalReordering0 start: 7 end: 12
line=Distortion
FeatureFunction: Distortion0 start: 13 end: 13
line=KENLM name=LM0 factor=0 path=/home/moses/lm/train.arpa.blm.en order=3
FeatureFunction: LM0 start: 14 end: 14
Loading UnknownWordPenalty0
Loading WordPenalty0
Loading PhrasePenalty0
Loading LexicalReordering0
Loading Distortion0
Loading LM0
Loading TranslationModel0
Created input-output object : [0.099] seconds
Translating: 拥有 大量 学校 、 学院 、 IT 企业 、 工厂 和 商业 设施 的 印度 第四 大城市 陷入 瘫痪 的确 很难 想象 。
Line 0: Initialize search took 0.001 seconds total
Line 0: Collecting options took 0.165 seconds at moses/Manager.cpp Line 141
Line 0: Search took 0.229 seconds
have a lot of schools , College , IT companies , factories and business facilities of India ’ s fourth big cities have paralyzed does it is hard to imagine .
BEST TRANSLATION: have a lot of schools , College , IT companies , factories and business facilities of India ’ s fourth big cities have paralyzed does it is hard to imagine . [11111111111111111111111] [total=-8.760] core=(0.000,-31.000,17.000,-16.013,-40.065,-19.059,-46.512,-9.511,0.000,0.000,-9.699,0.000,0.000,0.000,-158.466)
Line 0: Decision rule took 0.000 seconds total
Line 0: Additional reporting took 0.000 seconds total
Line 0: Translation took 0.395 seconds total
Name:moses VmPeak:434704 kB VmRSS:21016 kB RSSMax:87884 kB user:0.396 sys:0.100 CPU:0.496 real:0.504
BLEU值评测
短语表通常会很大,对于特定数据集的翻译,只需要表格的一小部分,所以,可以对表格进行过滤并二值化以加快翻译速度。运行下面的命令会在 $Translate_DIR 目录下生成 test 文件夹,并包含下图所示文件。
$MOSES_DIR/scripts/training/filter-model-given-input.pl $Translate_DIR/test $Translate_DIR/mert-work/moses.ini $CORPUS_DIR/test.tok.zh -Binarizer $MOSES_DIR/bin/processPhraseTableMin

翻译测试集
首先对 test.tok.zh 进行翻译,翻译好的译文为 test.translated.en,参数 -output-unknowns 可以导出翻译过程中的未登录词:
nohup nice $MOSES_DIR/bin/moses -f $Translate_DIR/test/moses.ini -output-unknowns $Translate_DIR/oov.txt < $CORPUS_DIR/test.tok.zh > $Translate_DIR/test.translated.en 2> $Translate_DIR/test.out
进行BLEU值评测
$MOSES_DIR/scripts/generic/multi-bleu.perl -lc $CORPUS_DIR/test.tok.en < $Translate_DIR/test.translated.en

下面这个提示不建议再用 multi-bleu.perl 这工具用于 BLEU 值评测了,因为评测结果会被分词方式所影响(不容易让你的论文被其他人以其他分词方式复现),推荐具备标准化分词方式的 mteval-v14.pl 脚本用于 BLEU 评测。但是,如果规定了统一的分词方式,multi-bleu.perl 还是可以用(不推荐)。
BLEU = 18.36, 54.5/24.5/12.7/6.8 (BP=0.998, ratio=0.998, hyp_len=128752, ref_len=129016)
It is not advisable to publish scores from multi-bleu.perl. The scores depend on your tokenizer, which is unlikely to be reproducible from your paper or consistent across research groups. Instead you should detokenize then use mteval-v14.pl, which has a standard tokenization. Scores from multi-bleu.perl can still be used for internal purposes when you have a consistent tokenizer.
关于 BLEU 值评测工具的比较可以看这篇 文章,我毕业论文中使用了 sacreBleu (不使用平滑函数),值得一提的是 BLEU 评测工具中有一项设置是针对 Smoothing_Function() 平滑函数的,不同的平滑函数对结果的影响是巨大的,其分数能相差几十。 NLTK 的低版本和高版本默认的平滑函数就有所不同,在进行评测之前,个人建议查看一下评测工具默认的平滑函数是哪个,在论文中要确认清楚。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



