
本文所有教程及源码、软件仅为技术研究。不涉及计算机信息系统功能的删除、修改、增加、干扰,更不会影响计算机信息系统的正常运行。不得将代码用于非法用途,如侵立删!
抖音关键词搜索脚本
环境
win10
雷电5
Android7.1
Python3.9
Auto.js 7 PRO
mitmproxy4.0
Auto.js 根据关键词搜索并滑动
function main(url, num, gap, timeout) {
// 这里写脚本的主逻辑
threads.start(function () {
//脚本开始时间
var starttime = new Date();
console.info(“脚本开始时间:”+Time_format(starttime))
console.info(“启动脚本”)
console.info(“滑动执行次数:”+num+“次”)
console.info(“滑动间隔时间:”+gap+“秒”)
console.info(“数据加载超时时间:”+timeout+“秒”)
//悬浮窗 控制台
console.show();
//启用按键监听
events.observeKey();
//监听音量上键按下
events.onKeyDown(“volume_down”, function(event){
console.info(“停止脚本”);
exit();
});
// 效验代理
proxy();
//启动APP
toast(“启动APP”)
opendy();
// 点击搜索按钮
console.info(“定位搜索按钮”);
while(!(id(“ex5”).exists())){
console.info(“搜索按钮定位失败”);
sleep(5000)
};
console.info(“成功定位搜索按钮”);
search = id(“ex5”).findOne();
right = search.bounds().centerX(); //X值中间位置
top = search.bounds().centerY(); //Y值中间位置
// console.info(right, top);
click(right, top);
console.info(“点击搜索按钮”);
sleep(3000);
// 请求搜索关键词接口
var url1 = url.toString(); //需要强转一下数据类型
var wds = get_wd(url1);
// 循环执行搜索任务
for (var i=0;i<wds.length;i++){
var wd=wds[i]; //获取数组指定下标内容 下标从零算起
console.log(“获取关键词:” +wd)
// 设置搜索文本
console.info(“定位搜索输入框”);
while(!(id(“fl_intput_hint_container”).exists())){
console.info(“搜索输入框定位失败”);
sleep(5000)
};
console.info(“输入关键词:”);
id(“et_search_kw”).setText(wd)
console.info(“点击搜索”);
// 点击搜索
// id(“l+h”).text(“搜索”).click()
// console.info(“成功定位搜索按钮”);
search_1 = id(“l+h”).findOne();
// 提取控件坐标中心位置并点击
coordinate_1 = JSON.parse(JSON.stringify(search_1.bounds())); //提取组工动态坐标值
centerX = search_1.bounds().centerX();
centerY = search_1.bounds().centerY();
console.info(centerX, centerY);
click(centerX, centerY);
console.info(“数据加载中。。。”);
// 判断数据是否加载成功
id_name = “ifj” //数据加载小图标id
if (!(Refresh(timeout, id_name))){
toast(‘数据加载失败!重试’)
toast(“关闭抖音APP”)
var packagename = getPackageName(“抖音”);
killApp(packagename);
sleep(2000)
return
};
console.info(“数据加载成功”)
// 开始滑动
// num=滑动执行次数
// gap=滑动间隔时间
// 页面加载超时时间
if (!(slide(wd, num, gap, timeout))){
exit;
};
};
console.info(“结束脚本”)
var endTime = new Date();
console.info(“脚本结束时间:”+Time_format(endTime))
console.info(“脚本执行用时:”+Time_calculation(endTime-starttime));
});
};
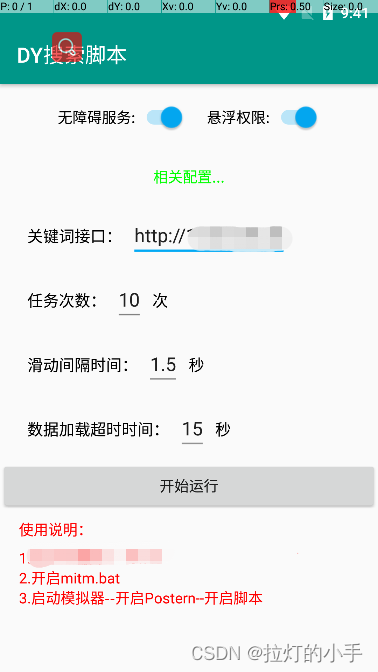
mitm数据抓包并存储
import json
import datetime
import mitmproxy.http
from mitmproxy import ctx, http
class Joker:
def request(self, flow: mitmproxy.http.HTTPFlow):
""“
flow: 自变量写法,用来定义变量类型
发送请求的所有数据
可以修改发送的请求参数
”""
url = “https://aweme.snssdk.com/aweme/v1/general/search/”
调试用
筛选出以上面url为开头的url
if flow.request.url.startswith(url):
打印请求的url
ctx.log.warn(111111111)
ctx.log.warn(f’{flow.request.url}’)
ctx.log.warn(f’{flow.request.pretty_url}’)
ctx.log.warn(2222222222)
ctx.log.warn(f’{flow.request.host}’)
ctx.log.warn(flow.dict)
def response(self, flow: mitmproxy.http.HTTPFlow):
""“
flow: 自变量写法,用来定义变量类型
接收到的响应数据
”""
筛选出以上面url为开头的url
if flow.request.url.startswith(url):
ctx.log.error(111111111111)
text = flow.response.get_text()
将已编码的json字符串解码为python对象
content = json.loads(text)
评论内容
comments = content[‘data’]
提取关键词
keyword = content.get(“global_doodle_config”).get(“keyword”)
ctx.log.warn(f’关键词:{keyword}’)
for comment in comments:
doc_type = comment.get(‘doc_type’)
ctx.log.info(doc_type)
ctx.log.info(type(doc_type))
if doc_type != 3:
ctx.log.info(“不是广告跳过”)
continue
标题
desc = comment.get(‘aweme_info’).get(“desc”)
视频链接
share_url = comment.get(‘aweme_info’).get(“share_url”)
视频id
aweme_id = comment.get(‘aweme_info’).get(“aweme_id”)
text = f’{keyword}|{desc}|{share_url}|{aweme_id}'
ctx.log.error(text)
self.save_connect(text=text)
ctx.log.error(“数据保存成功!”)
筛选出以上面url为开头的url
if flow.request.url.startswith(url_2):
ctx.log.error(22222222222222)
提取出来是一个不规则的字符串,有时是5行,有时是9行
text = flow.response.get_text()
text = text.split("\n")
for i in text:
将已编码的json字符串解码为python对象
try:
content = json.loads(i)
评论内容
comments = content[‘data’]
提取关键词
keyword = content.get(“global_doodle_config”).get(“keyword”)
ctx.log.warn(f’关键词:{keyword}’)
for comment in comments:
doc_type = comment.get(‘doc_type’)
ctx.log.info(doc_type)
ctx.log.info(type(doc_type))
if doc_type != 3:
ctx.log.info(“不是广告跳过”)
continue
标题
desc = comment.get(‘aweme_info’).get(“desc”)
视频链接
share_url = comment.get(‘aweme_info’).get(“share_url”)
视频id
aweme_id = comment.get(‘aweme_info’).get(“aweme_id”)
text = f’{keyword}|{desc}|{share_url}|{aweme_id}‘
ctx.log.error(text)
self.save_connect(text=text)
ctx.log.error(“数据保存成功!”)
except:
continue
def save_connect(self, text):
""“
保存数据
”""
filename = datetime.datetime.now().strftime(’%Y-%m-%d’) + ‘.txt’
with open(filename, ‘a+’, encoding=‘utf-8’) as f:
f.write(text)
f.write(’\n’)
addons = [
Joker()
]
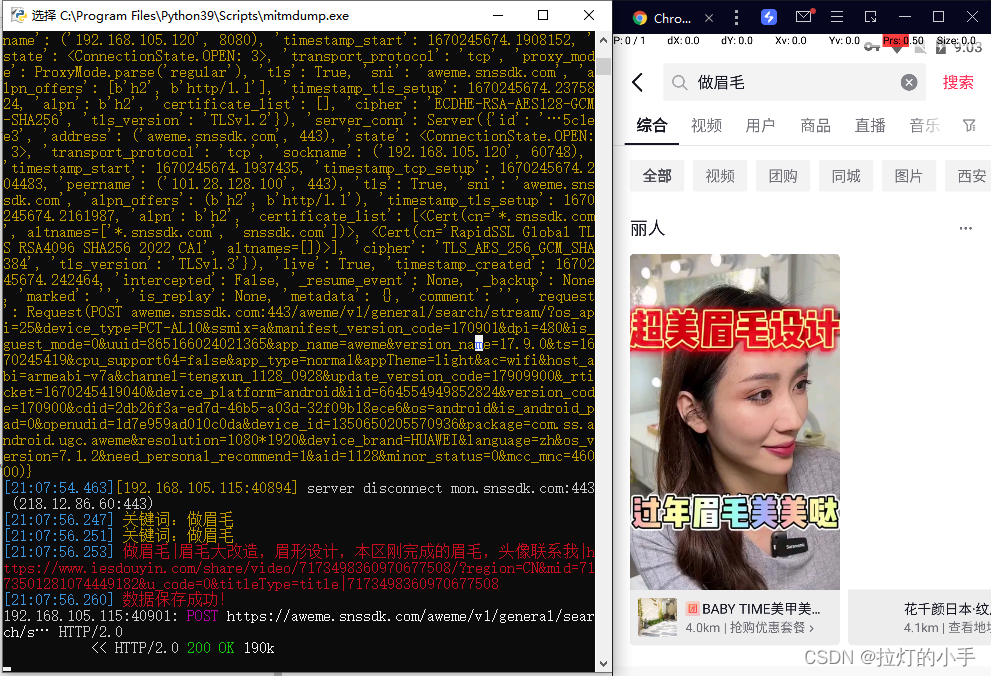
效果
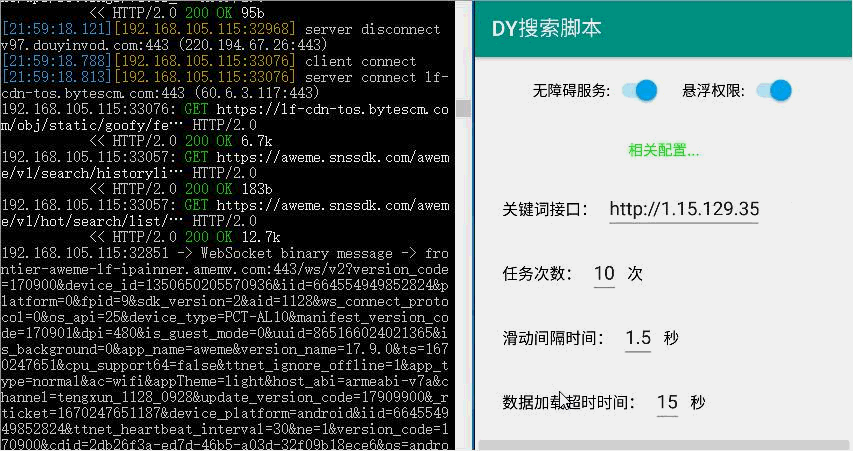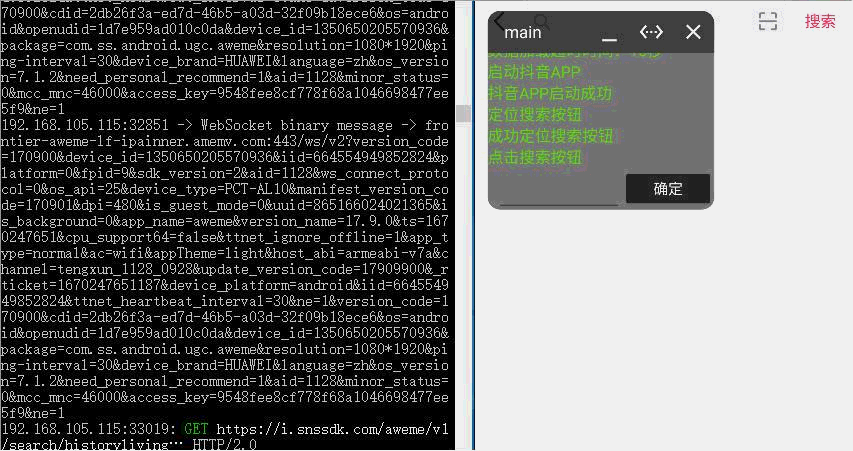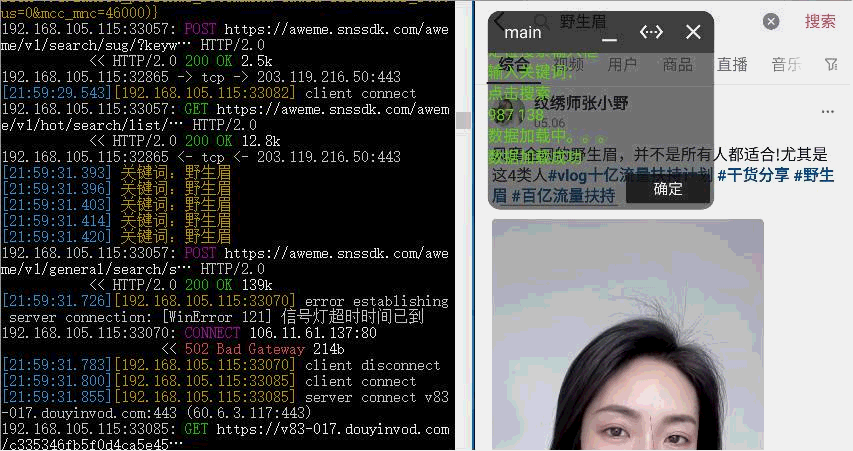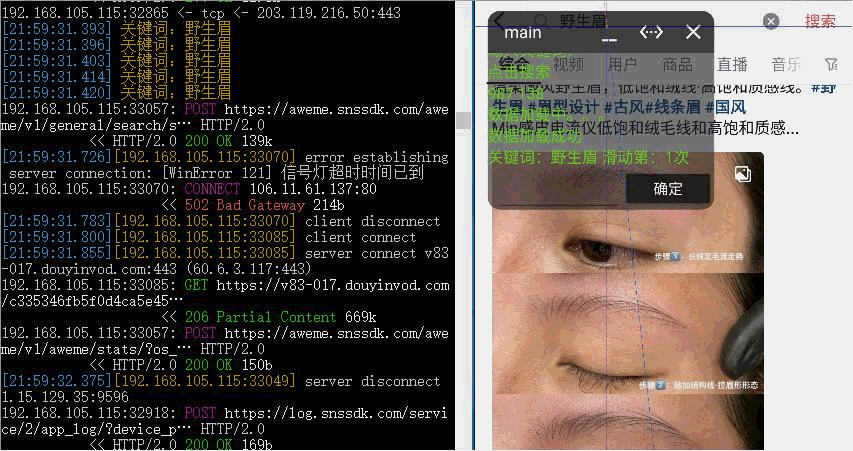
资源下载
本文仅供学习交流使用,如侵立删!
共同学习,写下你的评论
评论加载中...
作者其他优质文章



