
大家好,我是皮皮。
一、前言
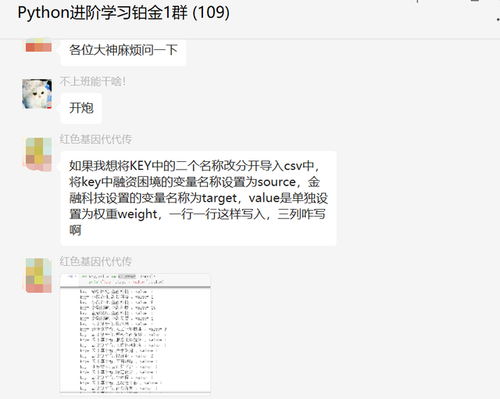
前几天在Python铂金交流群【红色基因代代传】问了一个、Pandas处理的问题,提问截图如下:
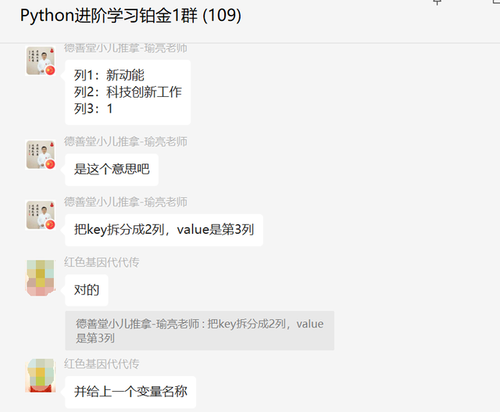
原始数据如下图所示:
下面是他自己写的代码:
with open("relationship.csv", "w", encoding='utf_8_sig') as f:
f.write("Source,Weight\n") #按照人物、对象、发生次数也是权重,写入代码当中
for key, value in au_group.items():
f.write(name + "," + name + "," + str(times) + "\n") #这里面名字被写入二次第二次是标签,然后逗号进行分列,str是写成数字意思需求澄清:他想把key里面的二个词分别导出CSV,上面的变量名称,一个是source,一个是target,value的值为数字,设置为weight,形成三列。
二、实现过程
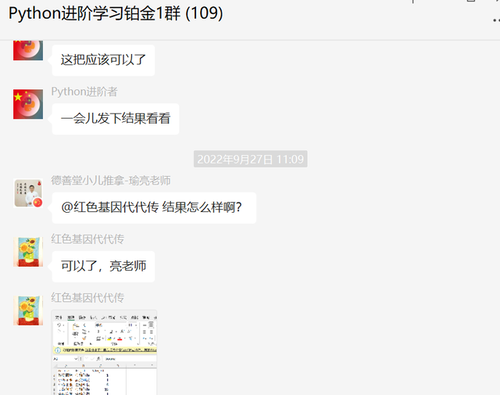
后来【瑜亮老师】和【论草莓如何成为冻干莓】给了一个代码,可以满足要求,如下图所示:
with open("relationship.csv", "w", encoding='utf_8_sig') as f:
f.write("Source,Tsrget,Weight\n") for key, value in au_group.items():
f.write(f"{key},{value}\n")可以顺利地得到预期的结果:
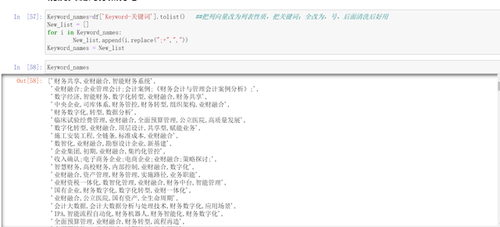
后面还问了一个其他的问题,关于修改缺失值,重复值之后,将新内容进行存储失败的问题,下面是他的原始代码。
后来【瑜亮老师】给了一个解决代码,如下所示:
df[['Author-作者', 'Keyword-关键词']] = df[['Author-作者', 'Keyword-关键词']].applymap(lambda x: re.sub(';+', ',', x).strip(',').split(','))
df.to_csv('result_220928.csv', index=False)顺利地解决了粉丝的问题。不得不承认,群里的大佬卧虎藏龙的,太强了!
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Pandas处理的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【红色基因代代传】提问,感谢【瑜亮老师】、【不上班能干啥!】、【论草莓如何成为冻干莓】给出的思路和代码解析,感谢【dcpeng】、【甯同学】、【猫药师Kelly】等人参与学习交流。
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦