
第一模块:
课程名称:SpringCloud+Vertx+Disruptor 撮合交易系统实战
章节名称:1-1 ~ 1-6
讲师姓名:Gudy
第二模块:
内容概述:
1-1 ~ 1-6小节主要介绍了撮合交易系统的相关概念、金融行业的系统组成,以及常见的架构。
第三模块:
学习心得:
第1章:
1-3 证券金融行业
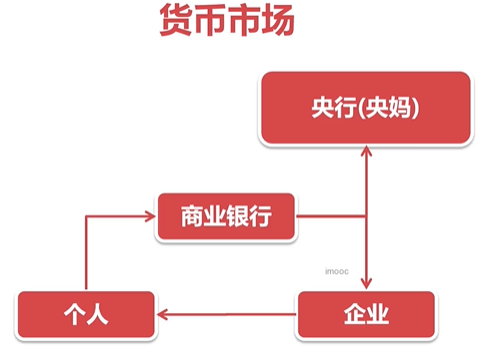
我国的金融市场:分为两个——货币市场、资本市场
货币市场:资金、债券流动的市场
以个人存款为例,描述资金流转过程:
资本市场:股票、基金等证券流动的市场
以京沪高铁股票为例,描述资金流转过程:
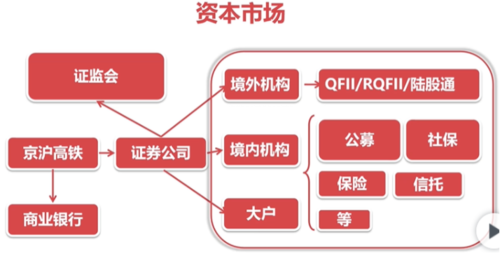
证券行业行情:买到新股的概率特别低,一般申购的1万个人里,有3到4个人可以买到新股
在上面这个资金流转中,证券公司一般拿的是3%,即:成功帮“京沪高铁”上市后,会拿“京沪高铁”市值的3%作为帮助上市的酬劳,这个业务属于证券公司的“承销业务”
当公司上市之后,这个公司的股票就可以自由流通了
证券行业要干的事:
*发行中介【投行】:帮企业上市
*委托中介【经纪】:帮投资人买股票
注意:我国的交易所,实行“会员制”,即:只有会员才可以接入到交易所的系统,进行交易,个人是接入不了的,所以个人必须通过“证券公司”才可以加入到金融产品的买卖中去
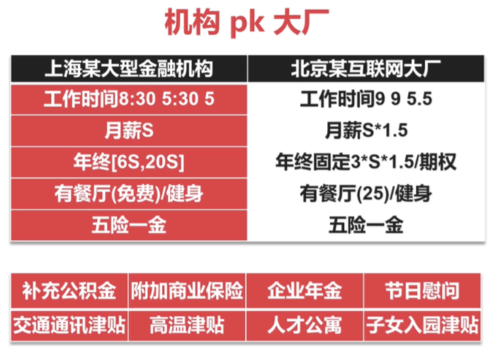
金融it的待遇:
bonus:浮动 最低都有5-6个月的base
base:固定
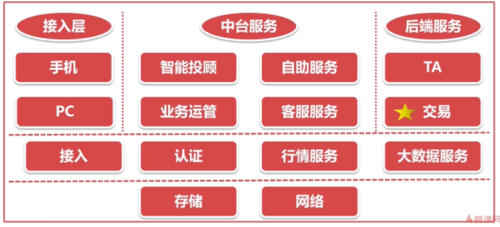
1-4 行业全景图
分3层:

细节图:
负载:就是流量压力,流量压力来了,负载就要自动的上去,流量压力小了,负载就要自动的下去
最核心的系统是"交易",吃透交易这一个系统,那待遇自然是十分高的
1-5 深入了解接入层-中台服务-交易系统-1
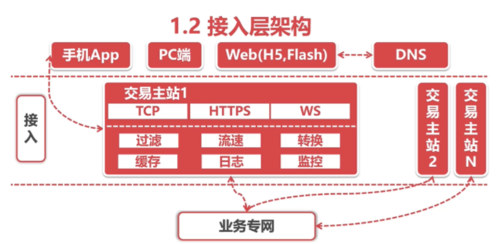
接入层:不负责具体的业务,他要做的就是维持和终端(手机
电脑等)的联系,并高效传递数据,最重要的参数就是:高并发、低延迟
注意:"日志"这一块是一个隐藏的金矿,由于种种原因,日志中的数据都没有得到很好的利用;一般日志最终是要落到"大数据"平台中
接入层具体实现方案:
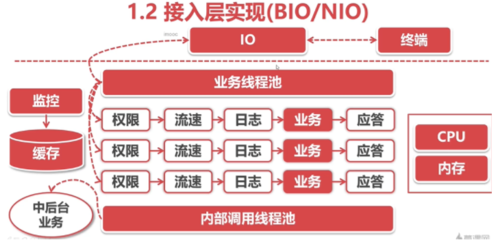
最早的实现方式是:BIO 即:用一个线程服务一个连接,实现:要用一堆tomcat
现在已经全面的用NIO的方式取代了BIO
简单的计算一下BIO方式对内存的消耗:
一个线程吃1M内存,而一个不大不小的机构就有100万客户,当这些客户全部链接上系统,那就要100万M内存,实际中根本承受不了
另外一个大问题就是:线程切换的开销;目前的cpu无法做到上百万个线程的自由的切换,实际中一万个线程的切换基本上就把cpu吃完了!!!
NIO原理:
三层部署结构,目的:隔离,保证安全性
小结接入层的要求:
*安全性:
*高并发:所有请求全部使用异步,在超高访问压力下,同步请求一定会出问题
*流量控制:当请求很多时,要判断请求的优先级,可以将优先级低的请求先丢掉,优先处理重要的请求
1-6 深入了解接入层-中台服务-交易系统-2

中台的升级换代比接入层要频繁许多,因为这一层和业务深度耦合,业务规则一变,则中台也就要变,所以中台的开发要求是快速响应需求变化,快速迭代
高可用,快迭代,就是微服务的特点,所以微服务天然的符合金融IT的开发需求
所以,绝大部分金融机构的中台就是用微服务搭建的
微服务就是将一个个服务进行解耦,变成一个个原子服务,然后通过原子服务的组合来向外提供一个完整的服务
业务拆分可以防范风险、提高开发效率
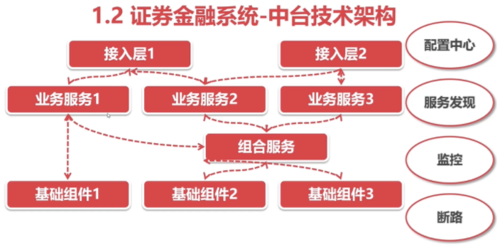
在微服务的体系之下,每个组件提供的原子服务就不是ip端口去唯一标识了,而是用服务名称来表示,用名称的好处:屏蔽掉底层硬件的变化,不至于说换一台机器就要去改项目配置,那然风险太大;而要实现用名称去唯一标识一个服务,就需要一整套的"机制"去支持,现在用的比较广泛的就是:zookeeper和springCloud的这两套。
1、2、3代表原子服务
服务启动时先在"配置中心"拉去相关的配置,然后在"注册中心"注册自己,这样上层的服务(也就是业务服务)就可以通过"注册中心"找到原子服务,这里的注册中心使用的一般是"zookeeper"【读作:主ke破】或者"eureka"【读作:you re 卡】,完成这些之后,就会启动网关,网关也会从注册中心中获取一些原子服务的信息和状态,网关一般使用的是"zuul"【读作:做】,zuul可以定制原子服务的组合,最后有一个oauth【读作:噢思】,作用:对前端的请求做一个身份校验;
上图就是各大机构中台服务的落地方案,这个落定方案可以称之为springcloud系解决方案,而除了springcloud系之外还有谷歌的"kubernates",但是,springCloud在国内起步比较早,现在各个机构用springcloud的技术比较多
中台的部署方案:
数据库方面:两地机房,三DB,保证数据的一致性
异步复制:异步复制的备DB一定是稍稍落后主DB的,落后时间差一般控制在几百毫秒之内,而且主机房和备机房之间,一般是拉着光纤,数据传输非常快
半同步:主DB必须在收到备DB的确认之后才会继续往备DB存数据
两地机房,三DB的方式可以满足绝大多数场景的高可用、数据一致性的要求,也是生产中绝大多数机构使用的部署方式
行业背景:
目前为止,我国个人投资者可以接触到的合法合规的证券期货交易所,一共有下面几家:
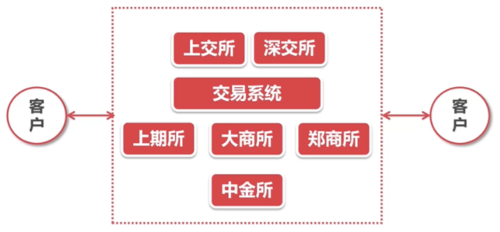
其中
证券交易所2家:90年成立的上交所、深交所
商品期货交易所3家:90年成立的郑州交易所、上海期货交易所、93年成立的大连商品交易所
而,中国金融交易所,是由上交所、深交所、 郑州交易所、上海期货交易所、大连商品交易所,共同发起的
除了这几家,其他的所有交易所都是非法的,而网上的什么原油期货交易平台都是野鸡平台
所以:看的出来,交易系统是所有交易所和相关代理机构的一级核心系统,是基础设施里的重中之重!!!一旦吃透交易系统的构建,那对金融行业的it技术认知,将会有一个质的飞跃
交易系统的架构:
早期撮合方式:
撮合都是在数据库中进行的,当交易方下单之后,所有的代码都是用”存储过程“来写的,当一方下单之后,存储过程会先找交易方的资金、持仓信息,然后,在查找能匹配的订单,之后生成一些成交数据,直接落库;
缺点:撮合的速度实在太慢了,一秒钟处理200比单子,这种速度已经远远无法适应,市场的节奏了。
现在的撮合方式:内存撮合
性能可以满足市场要求,同时采购机器的成本更低,代码升级维护也更加可控
未来撮合方式:spga硬件撮合
spga硬件撮合还在发展,尚未成熟,spga是一种专门的撮合硬件
国内外机构通用的交易系统架构图:
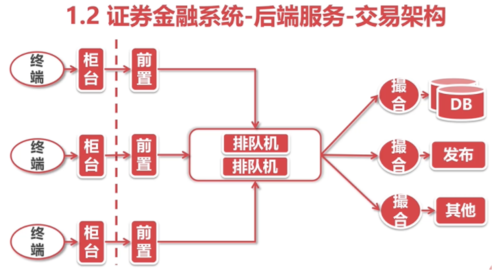
终端:终端是多种多样的;app、pc软件、web;终端连接券商柜台
柜台:报盘机
前置:前置网关
排队机:用到key-value数据库
交易撮合系统的两个特点:
*高可用:排队机
*点延迟
交易系统部署方式:
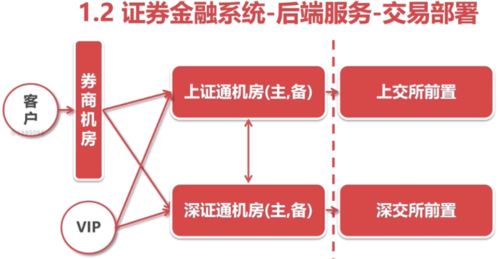
虚线右侧:内网,在内网部署交易系统
散户和机构在交易通道上的区别:
散户:先走券商机房,在连接到上证/深证机房,最后进撮合交易系统
机构:vip通道,直连上证/深证机房,进撮合交易系统
所以:散户的速度永远比机构慢,一些游资就特别喜欢vip直连上证/深证机房,进撮合交易系统
这就是”通道优势“
最终的撮合交易系统的系统拓扑图:
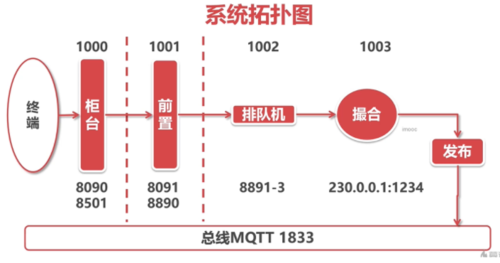
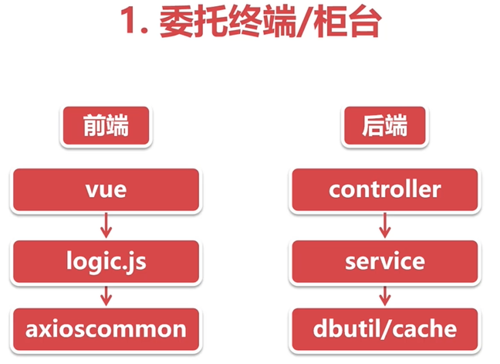


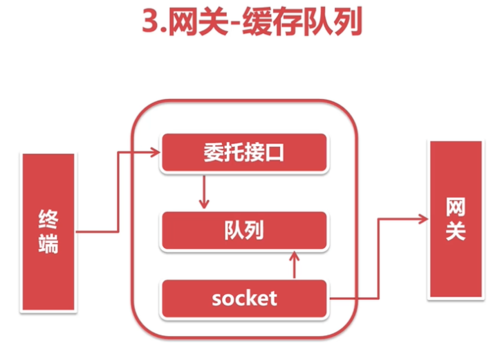
把发送报文剥离出来,用一个单独的线程来做


金融系统最看重的就是:稳定和业务逻辑的正确性,这两个是压倒一切的!!!
数据库中的数据其有一些字段允许为空,但是如果某个字段本不应该为空,最后因为”异常“导致为空(这个异常可能是各个意想不到的情况!!!),而恰巧业务逻辑中又依赖这个字段的值,那么就会报错,如果这个时候对这个字段做了”非空判断“就可以规避这个问题!!!
编码的非空判断和应急处置方案一定要非常注意
在编码时要多考虑边界的情况!!!
风控过不了,那很多的申报就发不出去
第四模块:
学习截图:

共同学习,写下你的评论
评论加载中...
作者其他优质文章



