
学习课程:基于Pytorch热门深度学习框架 从零开发NLP聊天机器人
章节名称:第2章 聊天机器人综合介绍 && 第3章 NLP基础
讲师:胖虎
课程内容:
NLP
什么是NLP?
Natural Language Processing 自然语言处理
AI重要分支之一
主要范畴


发展历程

研究难点

涉及知识
词处理
分词、词性标注、实体识别、词义消除
语句处理
句法分析(Syntactic Analysis)、语义分析(Senmantic Analysis)、机器翻译、语音合成
篇章处理
自动文摘
统计语言模型
N-Gram统计模型
马尔科夫模型
NLTK(Natural Language Toolkit)库
诞生于20世纪80年代
NLTK能干什么
python上著名的自然语言处理库
自带语料库,词性分类库
自带分类,分词等等功能
强大的社区支持
词性标注的分类方法
基于规则的词性标注
基于隐马尔可夫模型HMM的词性标注
基于转移的词性标注
基于转移与隐马尔可夫模型相结合的词性标注
分词
什么是分词?
把句子变成词
难点
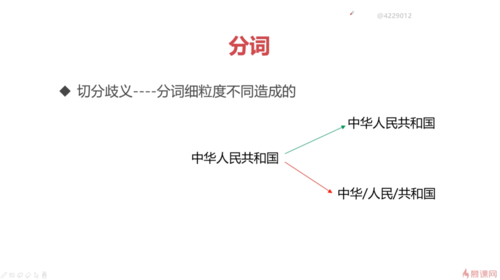

分词的算法
基于词典的分词算法

基于统计的分词算法
jieba
Python 中文分词组件
TF-IDF

TF:Term Frequency,衡量一个term在文档中出现得有多频繁。
TF(t)=(t出现在文档中的次数)/(文档中的term总数)
IDF:InverseDocument Frequency,衡量一个term有多重要。
IDF(t)=log_e(文档总数/含有t的文档总数).
TF-IDF=TF*IDF
scikit-learn可以用TF-IDF
NLTK和jieba也可以用TF-IDF
智能问答

聊天机器人原理


文本处理方法




Stopwords
自动过滤掉某些无意义的常用停顿词
常用stopwords网址:https://www.ranks.nl/stopwords
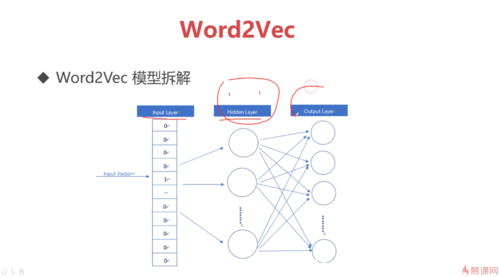
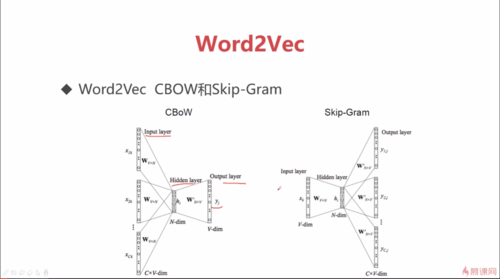
Word2Vec
2013年 Mikolov 提出,就是用神经网络把词转成向量的模型


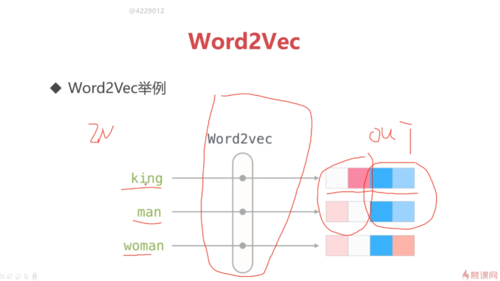
转换后的king和man后2个是一致的,说明他们是有关联关系的,而king与woman则离得比较远



学习收获:
对整个NLP发展及其目的有了一个全局的概览
了解分词、分词处理方法以及文本处理方法
打卡截图:



共同学习,写下你的评论
评论加载中...
作者其他优质文章



