
课程名称:Scrapy打造搜索引擎(分布式爬虫)
课程章节:提取博客网详情页信息及代码
主讲老师:bobby
课程内容:
今天学习的内容包括:提取博客网详情页信息分析问题解决及代码
课程收获:
1.向指定URL Request发起请求问题
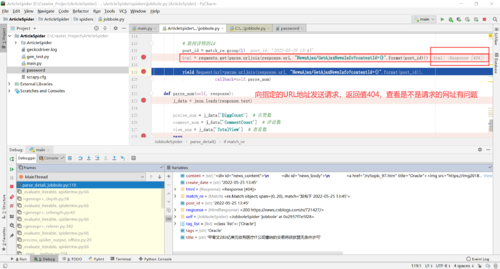
1.排查是否为request的网址不存在(是否写错?)
'https://news.cnblogs.com/n/721433/NewsAjax/GetAjaxNewsInfo?contentId=721433'
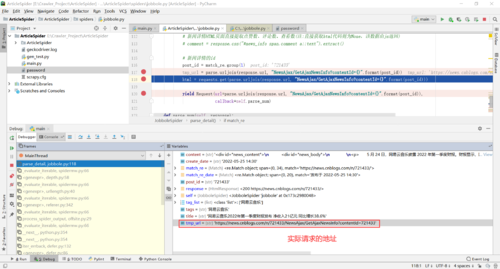
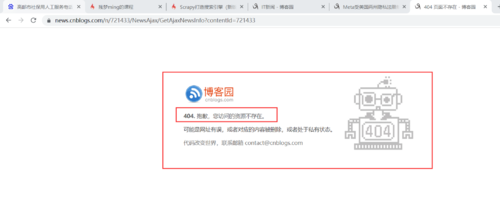
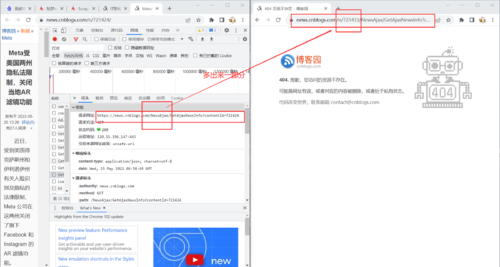
2.分析原因
3.修改后运行
2.代码
# 新闻详情页面数据抓取
def parse_detail(self, response):
match_re = re.match(".*?(\d+).*", response.url)
# 判断response.url地址是否包含新闻详情的id
if match_re:
# 新闻详情的id
post_id = match_re.group(1)
"""
article_item = JobBoleArticleItem() # 创建Item对象
# 获取新闻详情标题
title = response.xpath("//*[@id='news_title']//a/text()").extract_first("")
# title = response.css("#news_title a::text").extract_first("")
# 新闻详情发布时间
create_date = response.xpath("//*[@id='news_info']//*[@class='time']/text()").extract_first("")
# create_date = response.css("#news_info .time::text").extract_first("")
re_match = re.search(".*?(\d+.*)", create_date)
if re_match:
create_date = re_match.group(1)
# 新闻详情内容
content = response.xpath("//*[@id='news_content']").extract()[0]
# content = response.css("#news_content").extract()[0]
# 新闻详情标签
tag_list = response.xpath("//*[@class='news_tags']/a/text()").extract()
# tag_list = response.css(".news_tags a::text").extract()
tags = ",".join(tag_list) # 原因:可能某些文章并没有tag标签
# 新闻详情HTML页面直接提取点赞数、评论数、查看数(注:直接获取html代码则为None,该数据由js返回)
'''
1.浏览器中看到的html页面是浏览器执行过js程序后所呈现的页面
2.js逻辑非常强大,服务器中可能不存在该元素但是js可能写入该元素
注:通过Scrapy下载的页面实际上是服务器返回的原始的html,并不是浏览器中看到的html
# comment_num = response.xpath("//a[@id='News_CommentCount_Head']/text()").extract_first("")
# comment = response.css("#news_info span.comment a::text").extract()
'''
article_item['title'] = title
article_item['create_date'] = create_date
article_item['url'] = response.url
# 获取parse()方法yield的Request的meta中的值 注:article_item['front_image_url']数据类型必须为list类型
if response.meta.get("front_image_url", []):
article_item["front_image_url"] = [response.meta.get("front_image_url", "")]
else:
article_item["front_image_url"] = []
article_item['tags'] = tags
article_item['content'] = content
"""
item_loader = ItemLoader(item=JobBoleArticleItem(), response=response)
item_loader.add_xpath("title", "//*[@id='news_title']//a/text()")
item_loader.add_xpath("content", "//*[@id='news_content']")
item_loader.add_xpath("tags", "//*[@class='news_tags']/a/text()")
item_loader.add_xpath("create_date", "//*[@id='news_info']//*[@class='time']/text()")
item_loader.add_value("url", response.url)
item_loader.add_value("front_image_url", response.meta.get("front_image_url", ""))
article_item = item_loader.load_item()
'''
yield Request(url=parse.urljoin(response.url, "NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)))
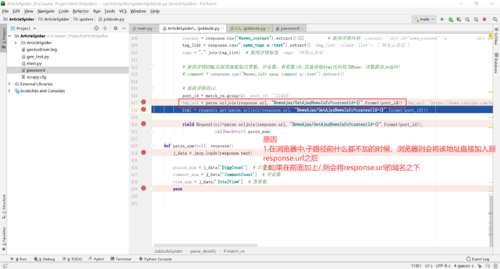
URL地址拼接问题?
上述方式拼接的url结果:https://news.cnblogs.com/n/724466/NewsAjax/GetAjaxNewsInfo?contentId=724466
而正确的url地址:https://news.cnblogs.com/NewsAjax/GetAjaxNewsInfo?contentId=724466
原因:如果写NewsAjax/GetAjaxNewsInfo?contentId=724466则将其作为https://news.cnblogs.com/n/724466子路径
如果写/NewsAjax/GetAjaxNewsInfo?contentId=724466则将其加入至https://news.cnblogs.com子域名下
'''
yield Request(url=parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)),
meta={'article_item': article_item}, callback=self.parse_num)
# 获取新闻详情点赞数、评论数、查看数(初始不存在于原始html中)
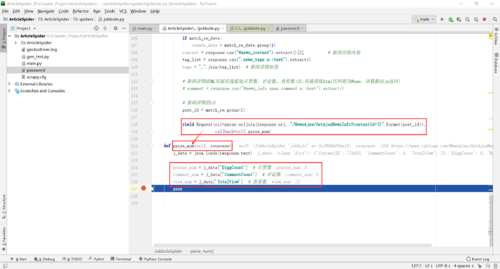
def parse_num(self, response):
"""
response.text——'{"ContentID":724466,"CommentCount":0,"TotalView":31,"DiggCount":0,"BuryCount":0}'
response.text的数据类型type: str
json.loads(response.text)——将str类型数据转化为dict字典类型
"""
j_data = json.loads(response.text)
"""
meta是一个字典,它的主要作用是用来传递数据的
1.meta = {‘key1’:value1},如果想在下一个函数中取出value1, 只需得到上一个函数的meta[‘key1’]即可
2.因为meta是随着Request产生时传递的,下一个函数得到的Response对象中就会有meta,即response.meta
"""
article_item = response.meta.get('article_item', "") # 获取parse_detail()中yield的Request()传递的meta
praise_num = j_data['DiggCount'] # 点赞数
comment_num = j_data['CommentCount'] # 评论数
view_num = j_data['TotalView'] # 查看数
article_item['praise_nums'] = praise_num
article_item['view_nums'] = view_num
article_item['comment_nums'] = comment_num
# 如何生成url的url_object_id(不定长字符串生成MD5)
article_item['url_object_id'] = common.get_md5(article_item['url'])
yield article_item点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦