
课程名称:Scrapy打造搜索引擎(分布式爬虫)
课程章节:.cnblogs模拟登陆
主讲老师:bobby
课程内容:
今天学习的内容包括:.cnblogs模拟登陆
课程收获:
1.Selenium(Web自动化工具)
1.selenium介绍
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
2.安装selenium、undetected-chromedriver
3.使用
# spider运行起来,URL都会从此方法开始
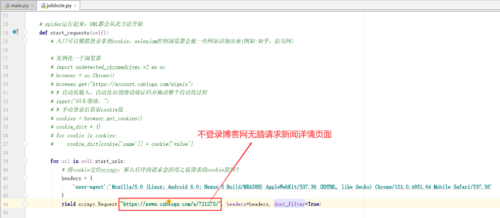
def start_requests(self):
# 入口可以模拟登录拿到cookie,selenium控制浏览器会被一些网站识别出来(例如:知乎、拉勾网)
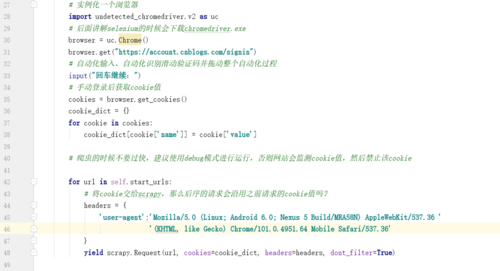
# 实例化一个浏览器
import undetected_chromedriver.v2 as uc
chrome_driver = r"E:\Python\chromedriver.exe"
# 后面讲解selenium的时候会下载chromedriver.exe
browser = uc.Chrome(executable_path=chrome_driver)
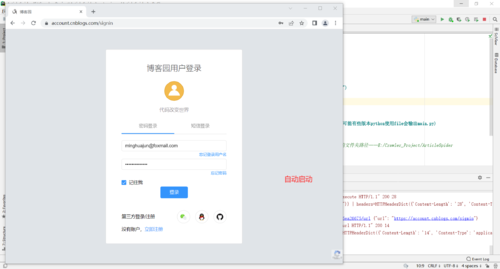
browser.get("https://account.cnblogs.com/signin")
# 自动化输入、自动化识别滑动验证码并拖动整个自动化过程
input("回车继续:") # 等待浏览器驱动加载完成
# 手动登录后获取cookie值
cookies = browser.get_cookies()
cookie_dict = {} # 将获取的cookie值转变为dict字典类型数据
for cookie in cookies:
cookie_dict[cookie['name']] = cookie['value']
# 爬虫的时候不要过快,建议使用debug模式进行运行,否则网站会监测cookie值,然后禁止该cookie
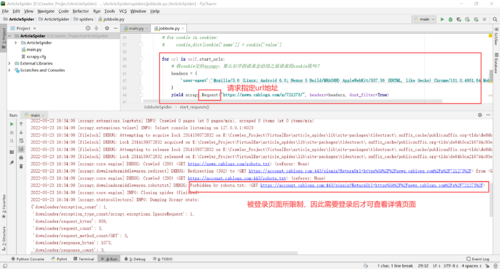
for url in self.start_urls:
# 将cookie交给scrapy,那么后序的请求会沿用之前请求的cookie值吗?
headers = {
# headers将访问伪装成浏览器,防止被反爬
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/101.0.4951.64 Mobile Safari/537.36'
}
yield scrapy.Request(url, cookies=cookie_dict, headers=headers, dont_filter=True)2.查看博客网新闻具体信息页面时需要事先登录
1.测试——假如未登录,直接查看新闻详情页面会发生什么?
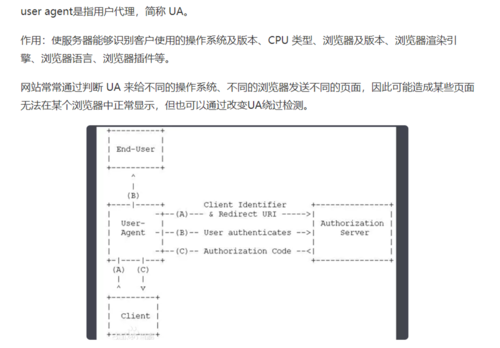
注:user-agent是什么?
3.测试使用
1.运行报错
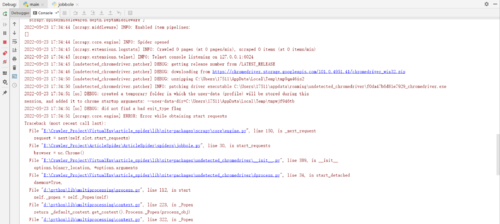

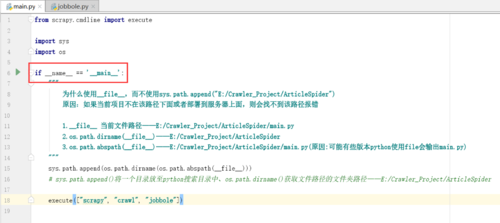
提示:入口文件中需要加if __name__ == '__main__':
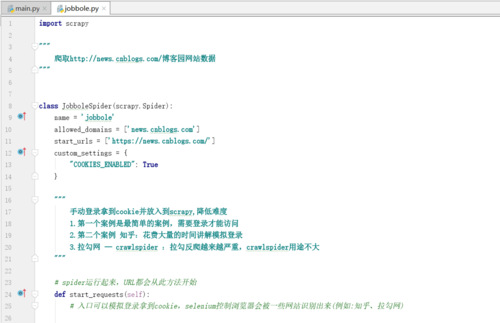
2.jobbole.py代码
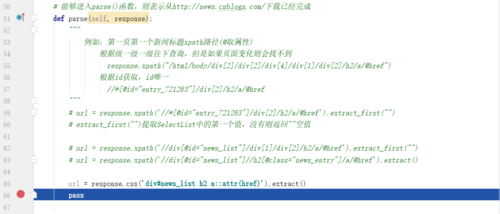
3.再次debug
共同学习,写下你的评论
评论加载中...
作者其他优质文章



