
模块一:Python全能工程师2022,6-2数据挖掘与特征工程之消除共线性
模块二:掌握Python数据读取、预处理、分析、挖掘与模型搭建的全流程必备知识。
模块三:
可能之前就有些没看懂,因此这里需要删除强相关性因子的其中之一个的时候不是很能理解。于是重新复习了之前那一节关于相关性的小节。
Xy有相关性不代表有因果性,可以用斯皮尔曼相关系数来计算。当相关性系数0.8-1之间都是强相关,0不相关。斜对角相互对称。
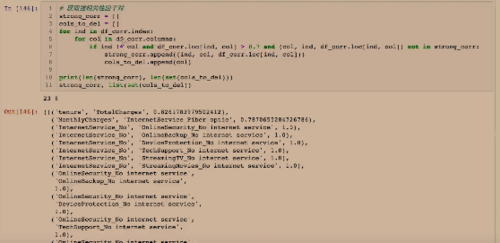
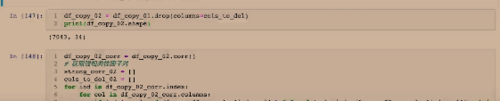
先建立空列表是强相关字段,还有一个空列表用于删除字段的,当强相关则可删除其一,因为是多余的。
这种方法在数据量较小的时候合适,看每一个相关性系数。但是如果数据量大,每一次运算前都要运行一次前缀,浪费计算时间。
如果相关性系数大于0.7的可以列出来,如果行列不同一个,col可以放到需要删除的一列里。最终需要删除的字段皆是有强需求删除的,可以看看返回的列表确认一下结论是否正确。
模块四:

点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦