
课程名称:Scrapy打造搜索引擎(分布式爬虫)
课程章节: 爬虫基础知识回顾
主讲老师:bobby
课程内容:
今天学习的内容包括:
Python正则表达式——re正则表达式库 re.match(pattern,string)—pattern模板字符串string待匹配字符串
课程收获:
match()函数表示匹配
^m必须以m为开头
.任意字符.*匹配任意字符任意多次
3$必须以3为结尾
?非贪婪匹配
+至少匹配一次例如:b+b字符出现一次
{2}某个字符出现2次 {2,}某个字符至少出现2次 {2,5}某个字符出现2<=且<=5
| 或关系"(bobby|bobby123)"表示字符可以匹配bobby或者bobby123
[abcd] 表示字符为[]中任意一个字符都可以
例如:boobby123如果为:[qwer]oobby123则匹配失败
[0-9] 0到9之间的数字匹配一次(区间匹配)
[^1] 字符不等于1
\s 匹配空格 \S 匹配非空格
\w 相当于[A-Z a-z 0-9_汉字] \W 表示非\w(非字母非数字非_非汉字)
[\u4E00-\u9FA5]匹配汉字
\d数字
import re
line = "ming123" # 待匹配字符串
# 判断某个字符串是不是等于line
if line == "ming123":
print("匹配成功1")
# ^m必须以m为开头 .任意字符 *前面字符可以匹配任意多遍(.*表示匹配任意字符任意多次)
regex_str1 = "^m.*" # 以m为开头,后面为任意多个字符都可以
if re.match(regex_str1, line):
print("正则匹配成功1")
# 3$必须以3为结尾
regex_str2 = ".*3$"
if re.match(regex_str2, line):
print("正则匹配成功2")
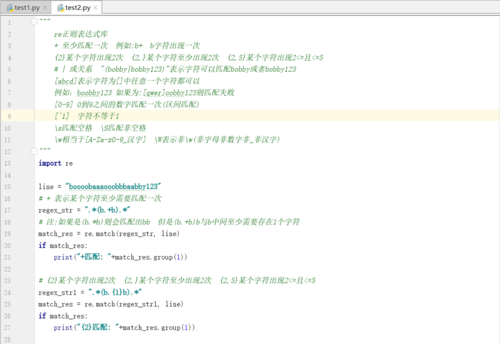
# ? 非贪婪匹配(贪婪匹配即从最右边开始匹配)
line = "boooobby123"
regex_str3 = ".*(b.*b).*"
# ()表示期望匹配的子串(正则表达式会将符合要求的字符串放至括号内)
# 希望匹配出:boooob 结果匹配出:bb(贪婪匹配的结果)
match_obj = re.match(regex_str3, line)
if match_obj:
print("贪婪匹配:"+match_obj.group(1))
# 期望结果:boooob 实际结果:boooobb(原因:第一个b非贪婪匹配,但是匹配第二个b的时候还是贪婪匹配)
regex_str3 = ".*?(b.*b).*"
match_obj = re.match(regex_str3, line)
if match_obj:
print("贪婪匹配:"+match_obj.group(1))
# 期望结果:boooob 实际结果:boooob(两个b都是非贪婪匹配)
regex_str3 = ".*?(b.*?b).*"
match_obj = re.match(regex_str3, line)
if match_obj:
print("非贪婪匹配:"+match_obj.group(1))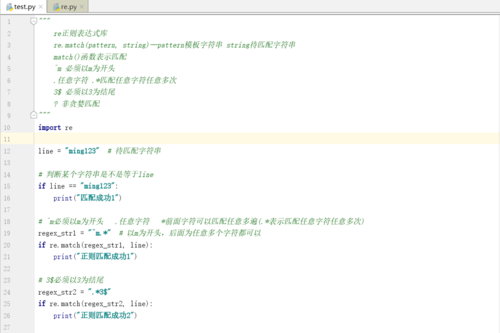


点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦