
一、写在前面
skiplist是一种有序的数据结构, 不同于各种平衡树, skiplist看起来就是多层的链表, 具体点每个元素是个数组, 这个元素的数组除了0层是和下个元素直连, 1层和n层之间可能和下个, 或者下下个节点连接起来。
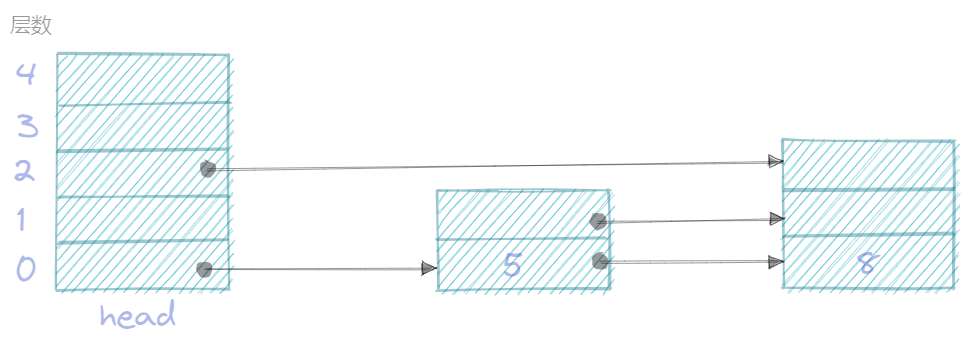
这些skiplist节点的多层结构,构成实施二分搜索的基础, 理论从而达到可观的效率, 开源界大名鼎鼎的redis的zset一部分使用skiplist。
对于这个被吹爆了的数据,下面会使用redis的套路在go里面实现下, 是骡子是马拉出来溜溜压测下性能如何。
二、 一个基本的skiplist的样子
2.1 图示
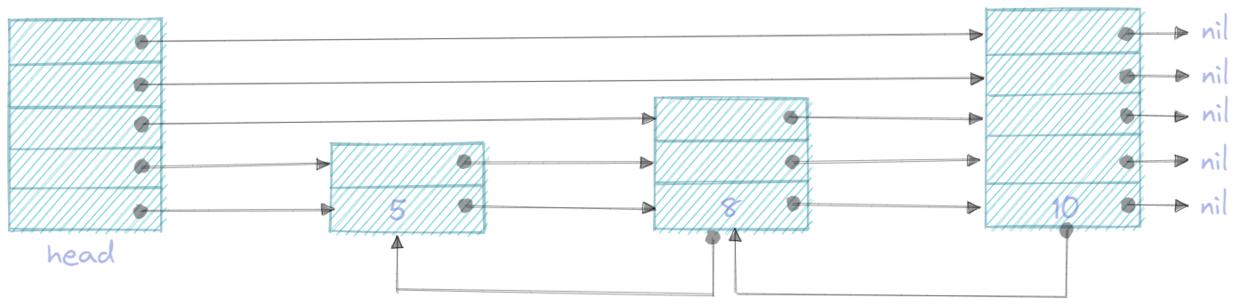
2.2 代码展示
表头和节点
type Node[T any] struct {
score float64
elem T
// 后退指针
backward *Node[T]
NodeLevel []struct {
// 指向前进节点, 是指向tail的方向
forward *Node[T]
span int
}
}
type SkipList[T any] struct {
head *Node[T]
tail *Node[T]
r *rand.Rand
length int
level int
}
三、查找
3.1 图示
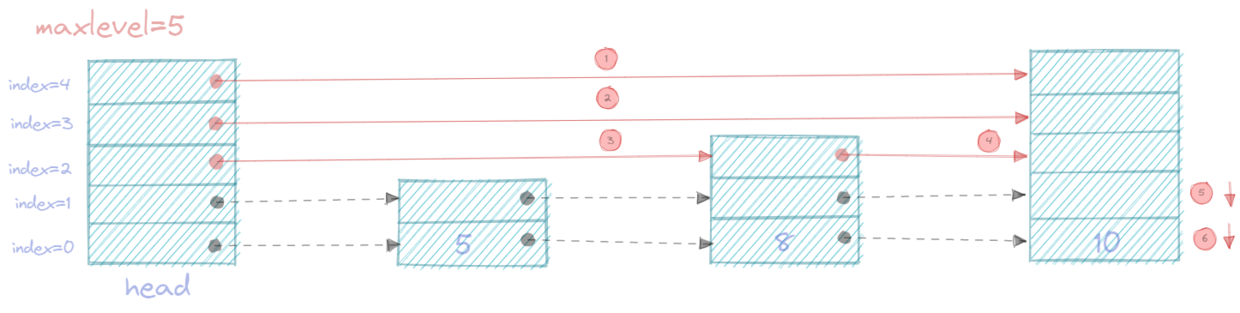
还是以上面的skiplist为例, 下面会画出查找每个元素的搜索路径。
skiplist里面head节点有个两个重要的特点:
- head节点的层数等于最大节点和层数, 一般实现中会有MaxLevel记录最大结点层数
- head节点是与数据节点之间有链接关系的
下面的查找路径,
-
实线表示查找的路径,
-
虚线表示节点间的关系
查找的过程就是先从head节点的MaxLevel-1索引查找, 查找的大致走位是向右向下向右向下…就逼近目标位置
- 查找5
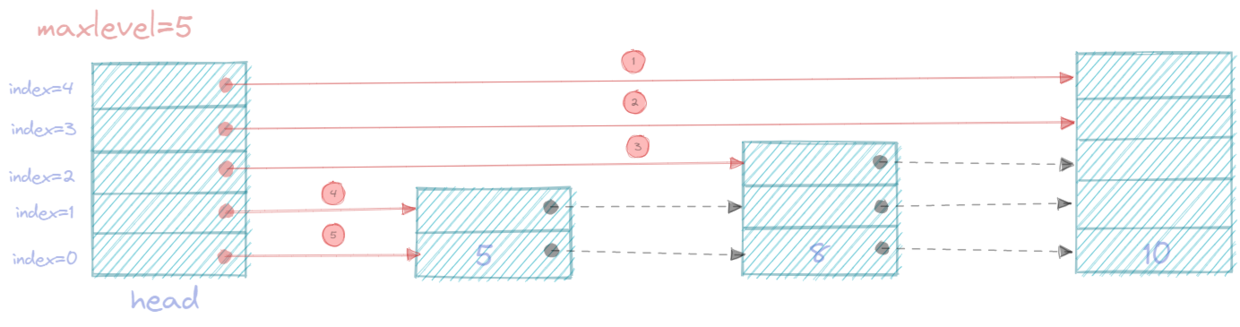
- 查找8
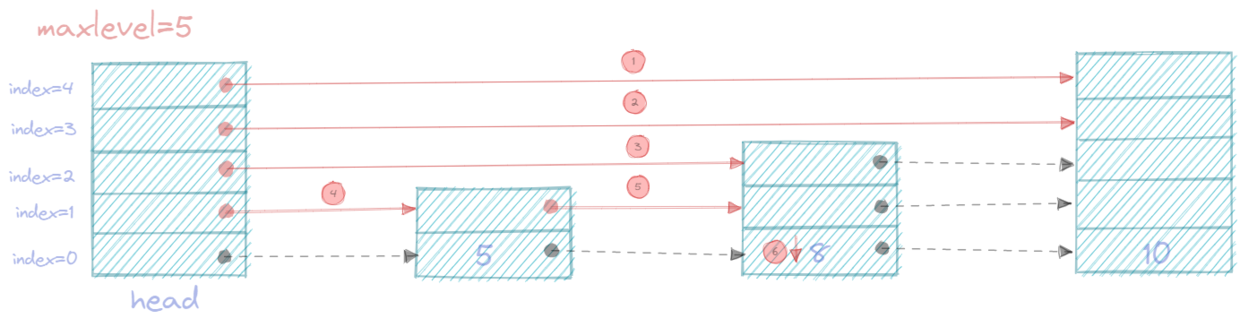
- 查找10
3.2 代码展示
// 获取
func (s *SkipList[T]) GetWithErr(score float64) (elem T, err error) {
x := s.head
for i := s.level - 1; i >= 0; i-- {
for x.NodeLevel[i].forward != nil && (x.NodeLevel[i].forward.score < score) {
x = x.NodeLevel[i].forward
}
}
x = x.NodeLevel[0].forward
if x != nil && score == x.score {
return x.elem, nil
}
err = ErrNotFound
return
}
四、新增
新增先使用update[]数组维护每层需要插入节点的位置, 通过抛硬币的函数决定这个新节点的level, 最后修改节点的前后关系, 就是插入链表节点的多层版本, 维护多层信息就是update[]干的事情。
4.1 抛硬币函数
把1当成硬币的正面, 0当作硬币的反面, 直到抛到0时就结束, 这时连续的正面就是skiplist里面需要建的level数。
func (s *SkipList[T]) rand() int {
level := 1
for {
if s.r.Int()%2 == 0 {
break
}
level++
}
if level < SKIPLIST_MAXLEVEL {
return level
}
return SKIPLIST_MAXLEVEL
}
4.2 梳理多层插入节点逻辑
如果在单链表中执行插入操作
-
prev是待插入节点的前面一个节点, -
待插入节点是
new,new.next = prev.next,prev.next = new, 即可完成一个节点的插入。
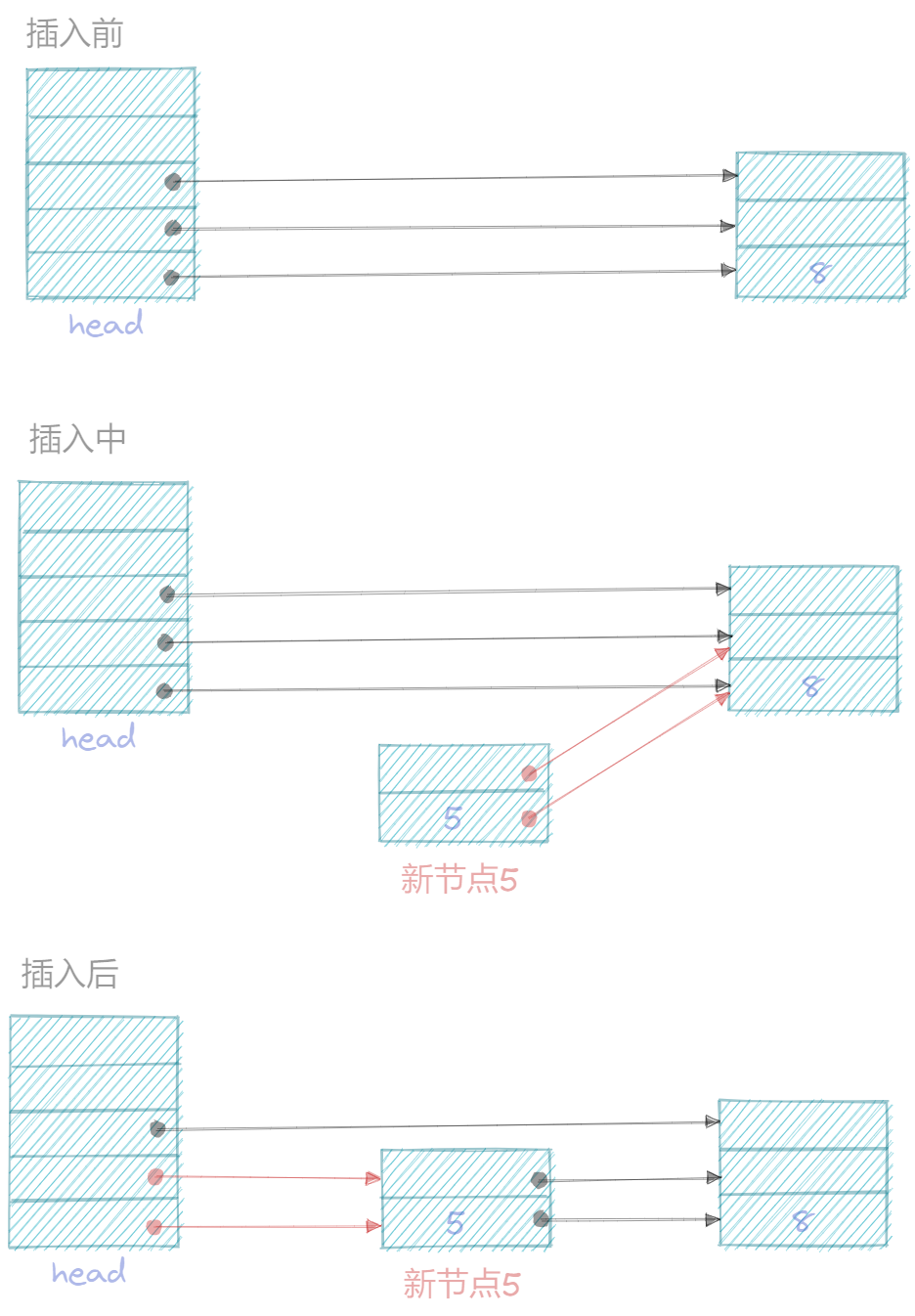
skiplist的插入和单链表相似, 无非是扩展到多层, 使用一个数组记录每一层的prev指针,skiplist的新节点也是数组,这里使用一个for循环遍历层,每个层内的操作与单链表中的操作是一样的。
4.3 图示
插入节点5
4.4 代码展示
func (s *SkipList[T]) InsertInner(score float64, elem T, level int) *SkipList[T] {
var (
update [SKIPLIST_MAXLEVEL]*Node[T]
rank [SKIPLIST_MAXLEVEL]int
)
x := s.head
var x2 *Node[T]
for i := s.level - 1; i >= 0; i-- {
if i == s.level-1 {
rank[i] = 0
} else {
rank[i] = rank[i+1]
}
for x.NodeLevel[i].forward != nil &&
(x.NodeLevel[i].forward.score < score) {
// 暂时不支持重复的key, 后面再说 TODO
//|| x.NodeLevel[i].forward.score == score &&
//s.compare(elem, x.NodeLevel[i].forward.elem) < 0) {
//TODO span的含义是?
rank[i] += x.NodeLevel[i].span
x = x.NodeLevel[i].forward
}
// 保存插入位置的前一个节点, 保存的数量就是level的值
update[i] = x
}
// 这个score已经存在直接返回
x2 = x.NodeLevel[0].forward
if x2 != nil && score == x2.score {
x2.elem = elem
return s
}
if level > s.level {
// 这次新的level与老的level的差值, 给填充head指针
for i := s.level; i < level; i++ {
// TODO rank的含义
rank[i] = 0
update[i] = s.head
update[i].NodeLevel[i].span = s.length
}
s.level = level
}
// 创建新节点
x = newNode(level, score, elem)
for i := 0; i < level; i++ {
// x.NodeLevel[i]的节点假设等于a, 需要插入的节点x在a之后,
// a, x, a.forward三者的关系就是[a, x, a.forward]
// 那就变成了x.forward = a.forward, 修改x.forward的指向
// a.forward = x
// 看如下两行代码
x.NodeLevel[i].forward = update[i].NodeLevel[i].forward
update[i].NodeLevel[i].forward = x
x.NodeLevel[i].span = update[i].NodeLevel[i].span - (rank[0] - rank[i])
update[i].NodeLevel[i].span = rank[0] - rank[i] + 1
}
for i := level; i < s.level; i++ {
update[i].NodeLevel[i].span++
}
if update[0] != s.head {
x.backward = update[0]
}
if x.NodeLevel[0].forward != nil {
x.NodeLevel[0].forward.backward = x
} else {
s.tail = x
}
s.length++
return s
}
五、删除
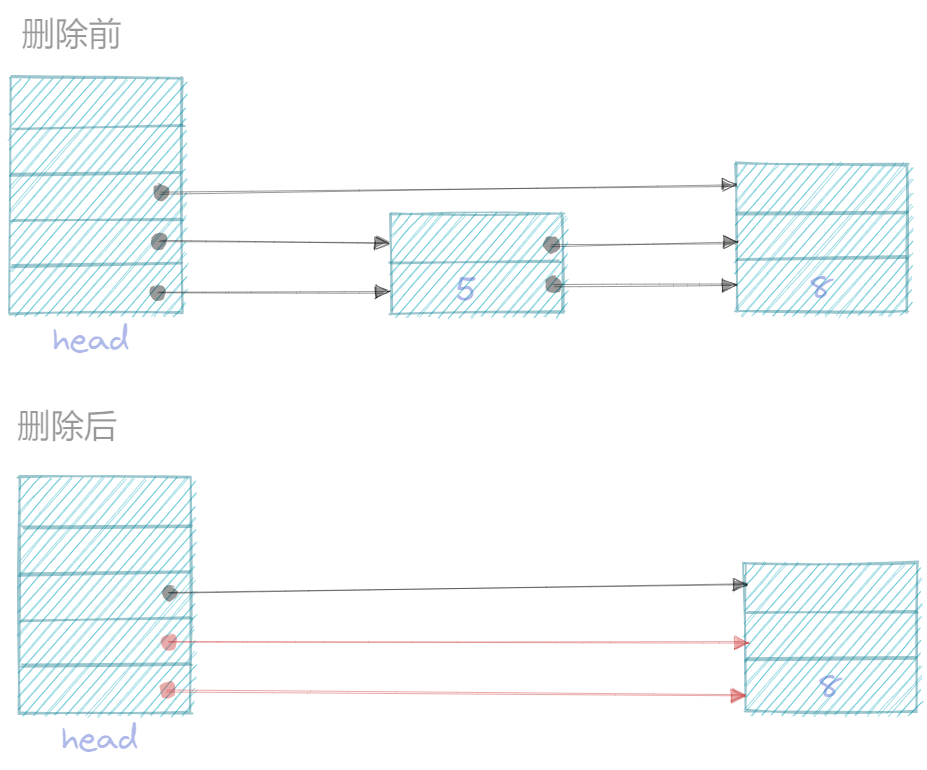
如果在单链表中执行删除操作, prev是待删除节点的前面一个节点, 如果要删除待删除节点n, 直接prev.next = n.next就完成一个节点的删除, skiplist的删除也和单链表类似。
5.1 图示
删除节点5
5.2 代码展示
func (s *SkipList[T]) removeNode(x *Node[T], update []*Node[T]) {
for i := 0; i < s.level; i++ {
if update[i].NodeLevel[i].forward == x {
update[i].NodeLevel[i].span += x.NodeLevel[i].span - 1
update[i].NodeLevel[i].forward = x.NodeLevel[i].forward
} else {
update[i].NodeLevel[i].span -= 1
}
}
if x.NodeLevel[0].forward != nil {
// 原来右边节点backward指针直接指各左边节点, 现在指向左左节点
x.NodeLevel[0].forward.backward = x.backward
} else {
// 最后一个元素, 修改下尾指针的位置
s.tail = x.backward
}
for s.level > 1 && s.head.NodeLevel[s.level-1].forward == nil {
s.level--
}
s.length--
}
// 根据score删除元素
func (s *SkipList[T]) Remove(score float64) *SkipList[T] {
var update [SKIPLIST_MAXLEVEL]*Node[T]
x := s.head
for i := s.level - 1; i >= 0; i-- {
for x.NodeLevel[i].forward != nil && (x.NodeLevel[i].forward.score < score) {
x = x.NodeLevel[i].forward
}
update[i] = x
}
x = x.NodeLevel[0].forward
if x != nil && score == x.score {
s.removeNode(x, update[:])
return s
}
return s
}
六、压测
从压测上来看, 本文中的skiplist的实现, 相比golang map性能接近,同时保持有序特性,值得王婆卖瓜…
goos: darwin
goarch: amd64
pkg: github.com/guonaihong/gstl/skiplist
cpu: Intel(R) Core(TM) i7-1068NG7 CPU @ 2.30GHz
BenchmarkGet-8 1000000000 0.7746 ns/op
BenchmarkGetStd-8 1000000000 0.7847 ns/op
PASS
ok github.com/guonaihong/gstl/skiplist 178.377s
七、完整代码
有小伙伴对完整实现感兴趣的可查看如下链接, 除了上面聊过的Get、Set、Remove外, 还有遍历、TopMax、TopMin等操作。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



