
时间和窗口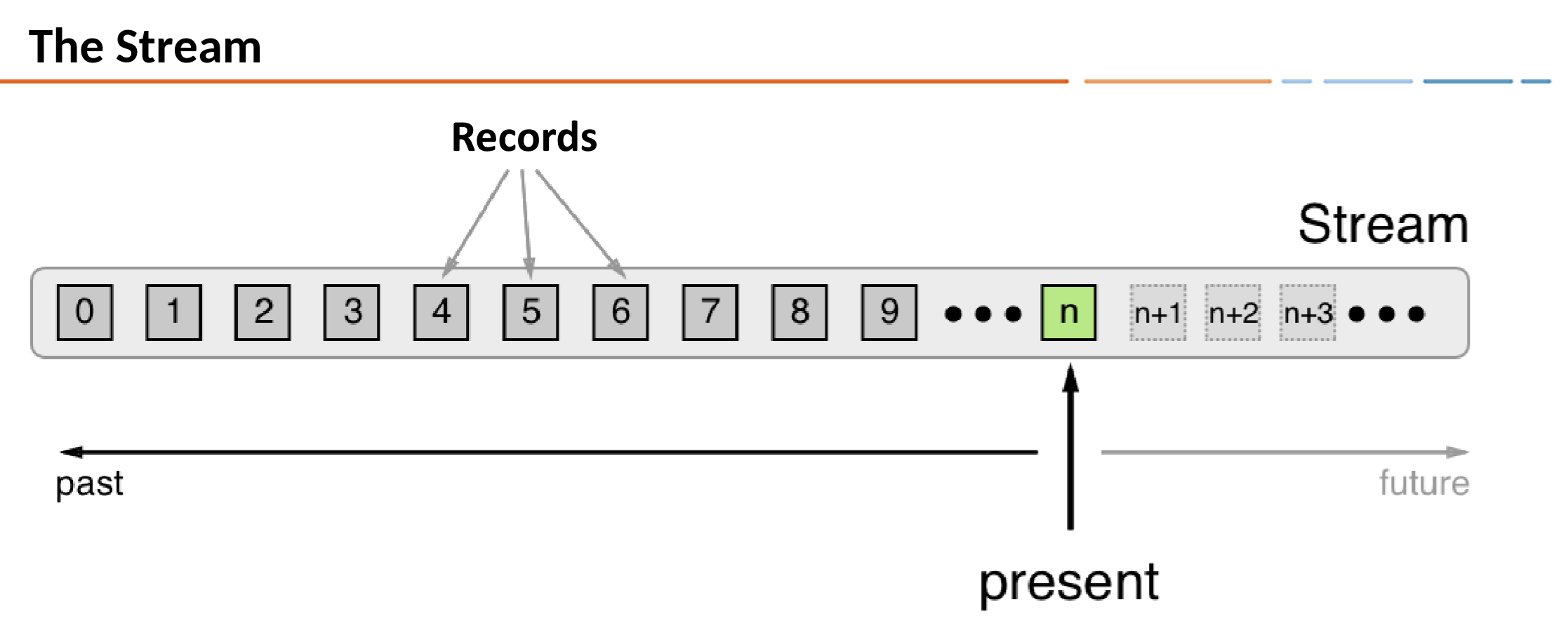
在ksqlDB中,记录事件在时间上的不变的。每个记录都带有一个时间戳,该时间戳确定其在时间轴上的位置。
这是ksqlDB用于处理记录的默认时间戳。时间戳由生产者应用程序或ApacheKafka?代理程序设置,具体取决于主题的配置。记录在流中可能是乱序的。
时间戳由时间相关的操作使用,例如聚合和联接。
时间语义
时间戳有不同的含义,具体取决于实现方式。记录的时间戳可以指事件发生的时间,将记录吸收到Kafka中的时间或处理记录的时间。这些时间是事件时间,摄取时间和处理时间。
事件时间
数据源创建记录的时间。要实现事件时间语义,需要在事件发生并生成记录时将时间戳嵌入记录中。
例如,如果记录是汽车中GPS传感器报告的地理位置变化,则相关事件时间是GPS传感器捕获位置变化的时间。
摄取时间
Kafka代理将记录存储在主题分区中的时间。摄取时间与事件时间类似,因为时间戳嵌入在记录中,但是摄取时间戳是在Kafka代理将记录追加到目标主题时生成的。
如果创建记录与将记录提取到Kafka之间的时间差很小,则提取时间可以近似为事件时间。
对于无法使用事件时间语义的用例,可以选择采用摄取时间。当数据生产者未在记录中嵌入时间戳时(例如在较早版本的Kafka的Java生产者客户端中),或当生产者无法直接分配时间戳(例如无法访问本地时钟时)时,请考虑使用提取时间。
处理时间
流处理应用程序使用记录的时间。处理时间可以在摄取时间之后立即发生,也可能会延迟几毫秒,几小时,几天或更长时间。
例如,假设有一个分析应用程序读取并处理从汽车传感器报告的地理位置数据,并将其呈现给车队管理仪表板。在这种情况下,分析应用程序中的处理时间可能比事件发生时间晚了数分钟或数小时,因为汽车可能会离开移动接收设备一段时间,并且必须在本地缓冲记录。
流时间
到目前为止,在所有已处理记录上看到的最大时间戳。
重要提示
不要混合具有不同时间语义的流或表。
时间戳分配
记录的时间戳由记录的生产者或Kafka Broker设置,具体取决于主题的时间戳配置。主题的message.timestamp.type设置可以是CreateTime或LogAppendTime。
CreateTime:代理使用生产者设置的记录时间戳。此设置强制执行事件时语义。LogAppendTime:当代理将记录追加到主题的日志时,代理会用代理的本地时间覆盖记录的时间戳。此设置将强制提取时间的语义。如果LogAppendTime已配置,则生产者无法控制时间戳。
ksqlDB不直接支持处理时间操作,但是您可以实现访问当前时间的用户定义函数(UDF)。有关更多信息,请参见函数。
默认情况下,当ksqlDB导入主题以创建流时,它将使用记录的时间戳,但是您可以添加WITH(TIMESTAMP=‘some-field’)子句以使用与记录值不同的字段作为时间戳。可选的TIMESTAMP_FORMAT属性指示ksqlDB应该如何解析该字段。您指定的字段可以是事件时间或摄取时间。这种方法实现了有效载荷时间语义。
重要提示
如果使用WITH(TIMESTAMP=…)子句,则此时间戳必须表示为Unix纪元时间(以毫秒为单位),这是自1970年1月1日UTC / GMT午夜以来经过的毫秒数。另外,提供TIMESTAMP_FORMAT时,可以将时间戳记指定为字符串。
在处理时间时,还应确保在流数据管道中正确地同步(或至少可以理解和跟踪)时间的其他方面(例如时区和日历)。它有助于在系统中的任何地方约定以UTC或Unix时间指定时间信息,例如自Unix纪元以来的秒数。
ksqlDB输出流的时间戳
当ksqlDB应用程序将新记录写入Kafka时,会将时间戳分配给它创建的记录。ksqlDB使用底层的Kafka Streams实现来计算时间戳。时间戳是根据上下文分配的:
通过直接处理输入记录生成新的输出记录时,输出记录时间戳将从输入记录时间戳继承。当通过定期函数生成新的输出记录时,输出记录时间戳记定义为流任务的当前内部时间。对于无状态操作,将传递输入记录时间戳记。对于flatMap和发出多个记录的同级,所有输出记录都从相应的输入记录继承时间戳。
聚合和联接的时间戳
对于聚合和联接,时间戳是通过使用以下规则来计算的。
对于具有左右输入记录的联接(stream-stream,table-table),将分配输出记录的时间戳max(left.ts, right.ts)。对于流表联接,将为统招全日制输出记录分配流记录中的时间戳。对于聚合,结果更新记录的时间戳取自触发更新的最新输入记录。对于聚合,max时间戳是针对每个键(全局(对于非窗口式)或每个窗口)在所有记录上计算的。
生产者和时间戳
生产者应用程序可以将其记录上的时间戳记设置为任何值,但是通常情况下,它选择合理的事件时间或当前的挂钟时间。
如果主题的message.timestamp.type配置设置为CreateTime,则对于生产者,以下内容成立:
创建生产者记录时,默认情况下,它不包含时间戳记。生产者可以在记录上明确设置时间戳。如果在生产者应用程序调用该producer.send()方法时未设置时间戳记,则将自动设置当前的挂钟时间。
在所有这三种情况下,时间语义都被认为是事件时间。
时间戳提取器
当ksqlDB导入主题以创建流时,它将使用时间戳提取器类从主题的消息中获取时间戳。时间戳提取器实现TimestampExtractor接口。
时间戳提取器的具体实现可以根据数据记录的实际内容(例如嵌入式时间戳字段)来检索或计算时间戳,以提供事件时间或提取时间语义,或者它们可以使用任何其他方法,例如返回当前墙。实现处理时语义的时钟时间。
通过创建自定义的时间戳提取器类,您可以根据业务逻辑的要求来实施不同的时间观念或时间语义。有关更多信息,请参见
default.timestamp.extractor。
窗口中的SQL查询
始终如一地表示时间,可以对具有不同时间边界的流和表(例如SUM)进行聚合操作。在ksqlDB中,这些边界称为windows。
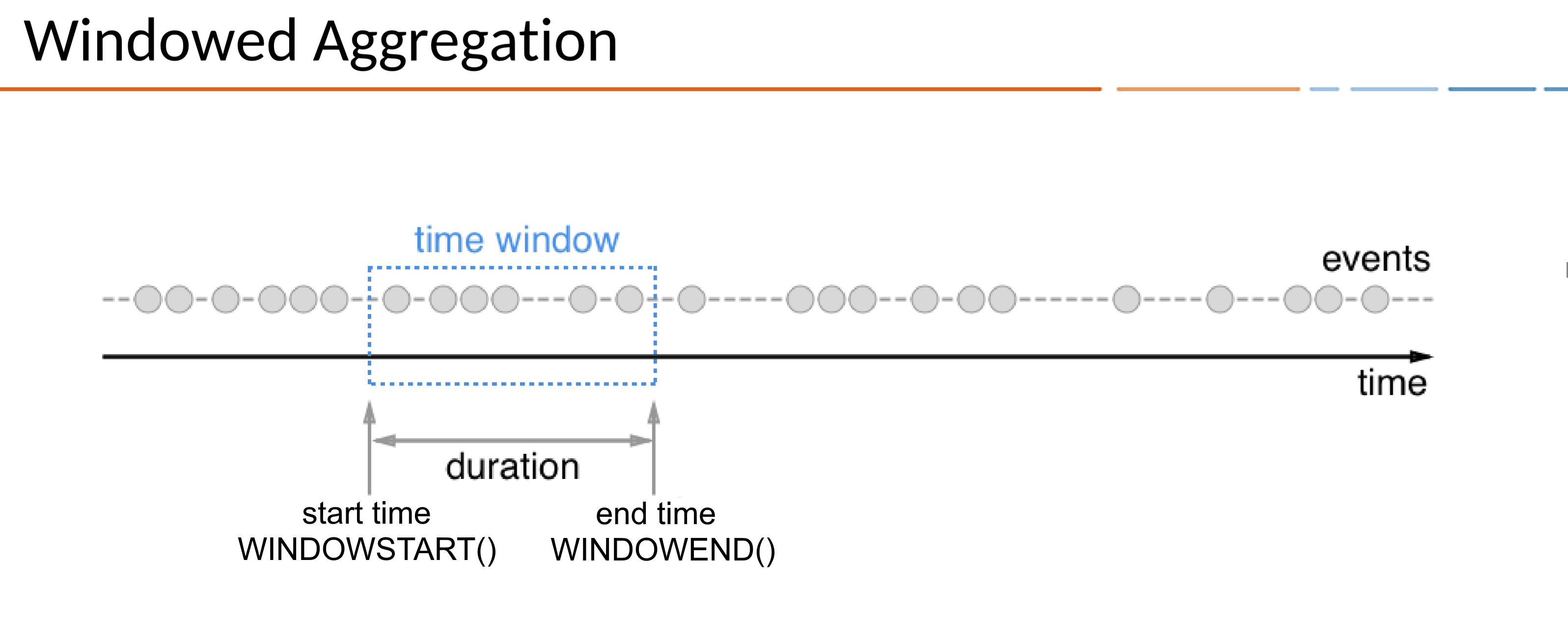
窗口具有开始时间和结束时间,您可以使用WINDOWSTART和WINDOWEND系统列在查询中进行访问。
重要提示
ksqlDB基于UTC时区中的Unix纪元时间,这可能会影响时间窗口。例如,如果您定义24小时滚动时间窗口,则该时间窗口将位于UTC时区,如果您希望在时区中设置每日时间窗口,则该时间窗口可能不合适。
通过窗口化,可以控制如何将具有相同键的有状态操作(例如聚合或联接)的记录分为多个时间段。ksqlDB跟踪每个记录键的窗口。
注意
一个相关的操作是分组,该操作将所有具有相同键的记录分组,以确保为后续操作正确地对记录进行分区或“键控”。当您在查询中使用GROUP BY子句时,通过窗口操作,您可以进一步将键的记录分组。
窗口查询必须按查询中选择的键分组。
在SQL查询中使用窗口时,聚合函数仅应用于在特定时间窗口内发生的记录。乱序到达的记录将按照您的期望进行处理:尽管窗口结束时间已过,但乱序记录仍与正确的窗口相关联。
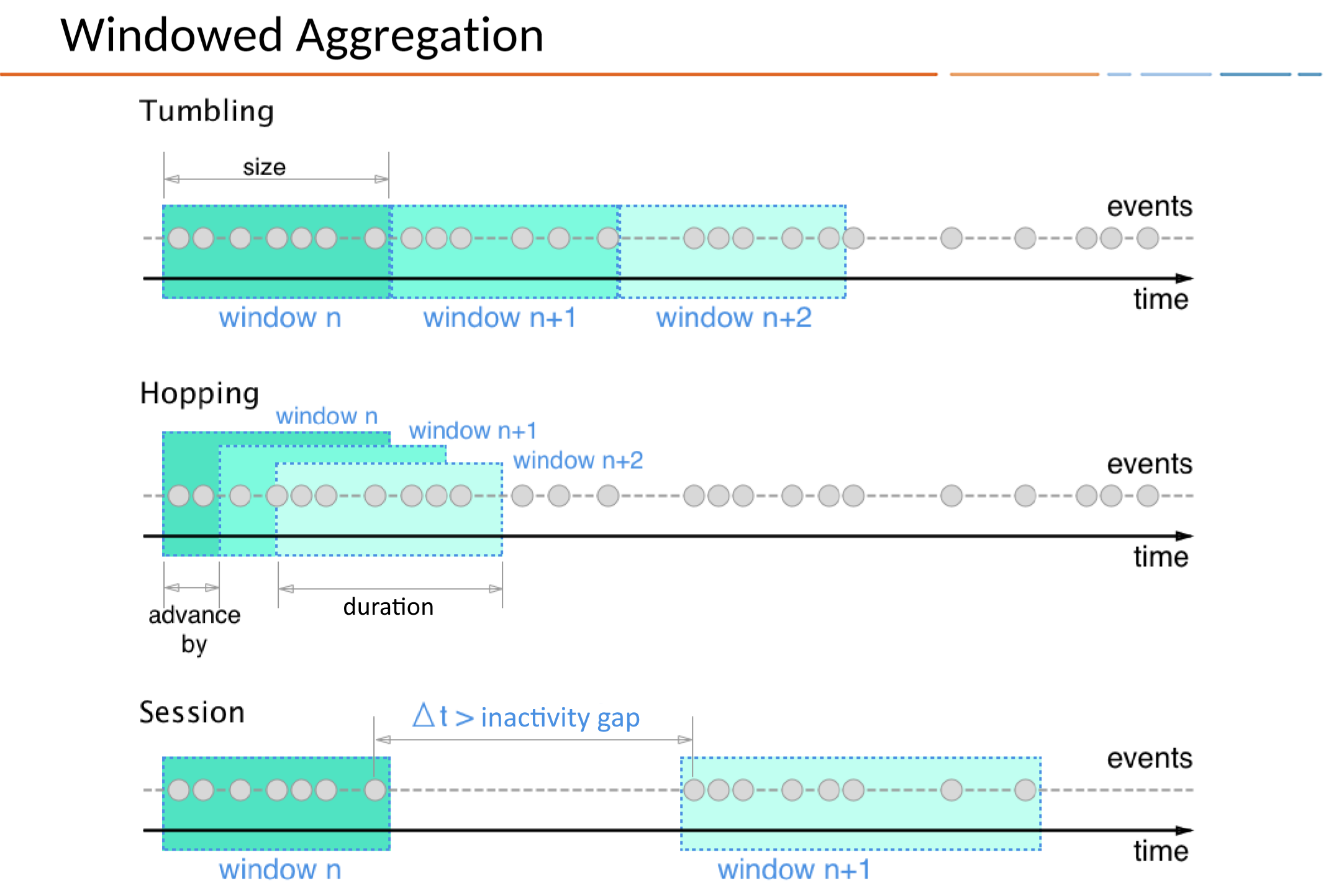
窗口类型
在ksqlDB中定义时间窗口的方法有以下三种:跳跃窗口,滚动窗口和会话窗口。跳跃和滚动窗口是时间窗口,因为它们由您指定的固定持续时间定义。会话窗口是根据传入数据动态调整大小的,并由活动间隔(由不活动的间隙分隔)定义。
窗口类型
行为
描述
滚动窗口 Tumbling
基于时间
固定时间,不重叠,无间隙的窗口
跳跃窗口 Hopping
基于时间
固定持续时间的重叠窗口
会话窗口 Session
基于会话
动态大小,不重叠的数据驱动窗口
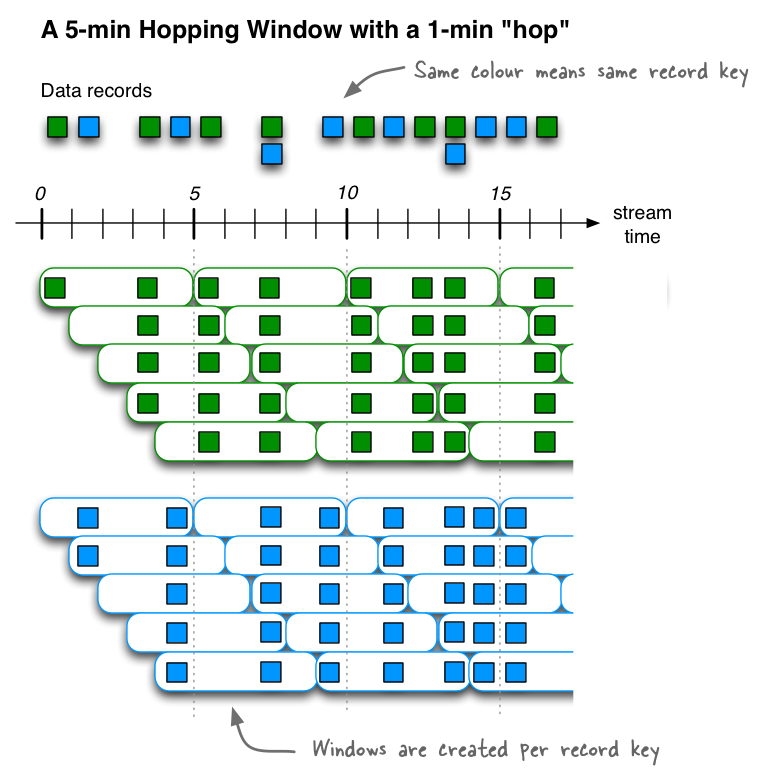
跳跃窗口
跳跃窗口基于时间间隔。他们建模固定大小的窗口,可能重叠。跳跃窗口由两个属性定义:窗口的持续时间及其前进间隔。前进间隔指定窗口相对于前一个窗口在时间上向前移动的距离。例如,您可以将跳跃窗口配置为持续时间为五分钟,前进间隔为一分钟。因为跳跃窗口可以重叠(通常是重叠的),所以一条记录可以属于多个这样的窗口。
所有跳跃窗口的持续时间相同,但是它们可能会重叠,具体取决于ADVANCE BY属性中指定的时间长度。
例如,如果您只希望Region_6女性用户在30秒的跳窗(增加10秒)中的综合浏览量,则可以运行如下查询:
SELECT regionid, COUNT(*) FROM pageviews
WINDOW HOPPING (SIZE 30 SECONDS, ADVANCE BY 10 SECONDS)
WHERE UCASE(gender)=‘FEMALE’ AND LCASE (regionid) LIKE ‘%_6’
GROUP BY regionid
EMIT CHANGES;
跳跃窗口的开始时间包括在内,但结束时间不包括在内。这对于非重叠窗口很重要,在非重叠窗口中,每条记录必须恰好包含在一个窗口中。
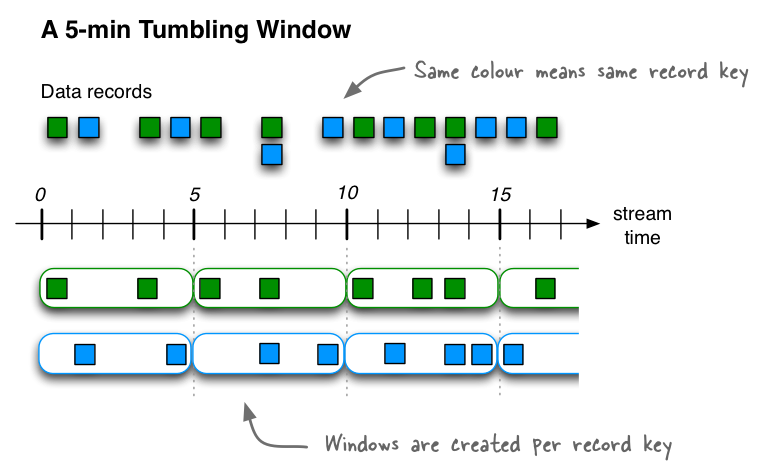
滚动窗口
滚动窗口是跳跃窗口的一种特殊情况。像跳跃窗口一样,滚动窗口也基于时间间隔。他们为固定大小,不重叠,无间隙的窗口建模。滚动窗口由单个属性定义:窗口的持续时间。翻滚窗口是跳窗,其窗口持续时间等于其前进间隔。由于滚动窗口永远不会重叠,因此一条记录将属于一个且仅属于一个窗口。
所有滚动窗口的大小相同且彼此相邻,这意味着每当一个窗口结束时,下一个窗口就会开始。
例如,如果要计算orders流中每小时每个邮政编码的五个最高价值订单,则可以运行如下查询:
SELECT orderzip_code, TOPK(order_total, 5) FROM orders
WINDOW TUMBLING (SIZE 1 HOUR) GROUP BY order_zipcode
EMIT CHANGES;
这是另一个示例:要检测authorization_attempts流中潜在的信用卡欺诈行为,您可以在五秒钟的时间间隔内查询特定卡上大于三的授权尝试次数。
SELECT card_number, count(*) FROM authorization_attempts
WINDOW TUMBLING (SIZE 5 SECONDS)
GROUP BY card_number HAVING COUNT(*) > 3
EMIT CHANGES;
滚动窗口的开始时间包括在内,但结束时间不包括在内。这对于非重叠窗口很重要,在非重叠窗口中,每条记录必须恰好包含在一个窗口中。
会话窗口
会话窗口将记录聚合到一个会话中,该会话代表一个活动周期,该活动周期由指定的不活动间隔或“空闲”分隔。在现有会话的不活动间隙内发生的任何带有时间戳的记录都将合并到现有会话中。如果记录的时间戳发生在会话间隔之外,则会创建一个新会话。
如果最后到达的记录的时间比指定的不活动间隔还早,则会启动一个新的会话窗口。
会话窗口与其他窗口类型不同,因为:
ksqlDB跨键独立跟踪所有会话窗口,因此不同键的窗口通常具有不同的开始和结束时间。会话窗口的持续时间会有所不同。即使是同一键的窗口通常也具有不同的持续时间。
会话窗口对于用户行为分析特别有用。基于会话的分析范围从简单的指标(如统计新闻网站或社交平台上的用户访问量)到更复杂的指标(如客户转化渠道和事件流)。
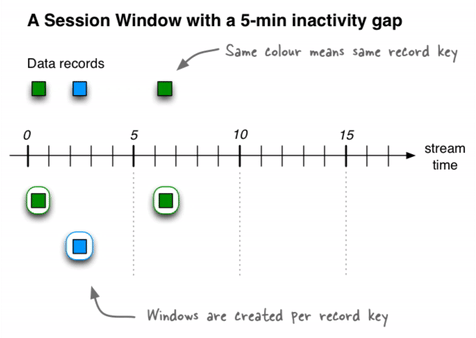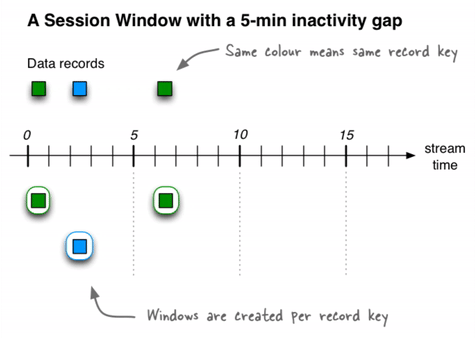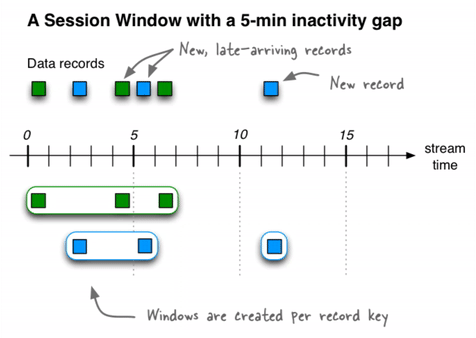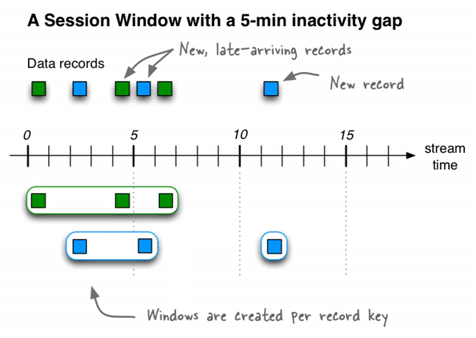
例如,为了计算每个区域浏览量会话窗口的数量为60秒的会话不活动间隙,则可能运行下面的查询,这sessionizes输入数据和执行每个区域的计数/聚合步骤:
SELECT regionid, COUNT(*) FROM pageviews
WINDOW SESSION (60 SECONDS)
GROUP BY regionid
EMIT CHANGES;
与时间窗口相比,会话窗口的开始时间和结束时间都包括在内。
一个会话窗口至少包含一个记录。会话窗口不可能有零条记录。
如果会话窗口仅包含一条记录,则该记录的ROWTIME时间戳与该窗口的开始和结束时间相同。通过使用WINDOWSTART和WINDOWEND系统列来访问它们。
如果会话窗口包含两个或多个记录,则最早/最旧记录的ROWTIME时间戳与窗口的开始时间相同,而最新/最新记录的ROWTIME时间戳与窗口的结束时间相同。
基于窗口的联接 Join
ksqlDB支持通过使用WITHIN子句在JOIN查询中使用Windows。
例如,要查找一条orders物流和一条shipments物流在最后一个小时内发货的订单,您可以运行以下查询:
SELECT o.order_id, o.total_amount, o.customer_name, s.shipment_id, s.warehouse
FROM new_orders o
INNER JOIN shipments s
WITHIN 1 HOURS
ON o.order_id=s.order_id
EMIT CHANGES;
乱序事件
通常,属于窗口的事件可能会乱序到达(例如,通过慢速网络),并且可能需要宽限期以确保事件被接受到窗口中。ksqlDB可以为每种窗口类型配置此行为。
例如,要允许事件在窗口结束后最多两个小时被接受,您可以运行如下查询:
SELECT orderzip_code, TOPK(order_total, 5) FROM orders
WINDOW TUMBLING (SIZE 1 HOUR, GRACE PERIOD 2 HOURS)
GROUP BY order_zipcode
EMIT CHANGES;
宽限期结束后到达的事件称为“延迟”,不包含在聚合结果中。
窗口保留
对于每种窗口类型,可以配置ksqlDB保留的过去的窗口数。对于使用ksqlDB作为其主要服务数据存储区的交互式应用程序,此功能非常有用。
例如,要将计算的窗口聚合结果保留一周,您可以运行以下查询:
CREATE TABLE pageviews_per_region AS
SELECT regionid, COUNT(*) FROM pageviews
WINDOW HOPPING (SIZE 30 SECONDS, ADVANCE BY 10 SECONDS, RETENTION 7 DAYS, GRACE PERIOD 30 MINUTES)
WHERE UCASE(gender)=‘FEMALE’ AND LCASE (regionid) LIKE ‘%_6’
GROUP BY regionid
EMIT CHANGES;
请注意,指定的保留期应大于窗口大小和任何宽限期的总和。
用户自定义函数
ksqlDB附带了许多内置函数。但是,当您需要使用ksqlDB没有的函数时会发生什么呢?
用户自定义函数使您可以使用Java挂钩添加新函数。
连接器
Kafka Connect是ApacheKafka?的开源组件,可简化Kafka与外部系统之间的数据加载和导出。ksqlDB提供了管理和与Connect集成的功能:
创建连接器描述连接器导入由Connect创建的主题到ksqlDB
设置连接集成
有两种方法来部署ksqlDB-Connect集成:
外部的:如果有可用的连接集群,请ksql.connect.url在您的ksqlDB服务器配置文件中设置属性。的默认值是localhost:8083。嵌入式:ksqlDB可以兼用作Connect服务器,并将运行在ksqlDB服务器实例上共存的分布式模式群集。为此,请将连接属性配置文件提供给服务器,然后在ksql.connecter.config属性中指定此文件。
注意
对于需要共享连接群集并提供可预测的工作负载的环境,建议在外部运行“连接”。
外挂程式
ksqlDB没有附带预安装的连接器,因此您必须下载并安装连接器。安装连接器的一种好方法是使用Confluent Hub。
本地支持的连接器
尽管可以创建,描述和列出所有类型的连接器,但ksqlDB本机支持一些连接器。ksqlDB提供了简化连接器创建的模板和自定义代码,以探索由这些连接器创建的主题到ksqlDB中:
Kafka连接JDBC连接器(源库):因为JDBC连接器不为它产生Kafka消息自动填充键,ksqlDB提供在传递能力"key"=’'中WITH子句从值提取柱,并使其成为键。Apache Kafka入门
ksqlDB是专门为ApacheKafka?构建的事件流数据库。尽管它旨在为您提供比Kafka更高层次的基元集,但不可避免的是,Kafka的所有概念不能也不应被完全抽象掉。本节介绍有效使用ksqlDB所需的最少数量的Kafka概念。有关更多信息,请查阅Apache Kafka官方文档。
记录/事件
事件是Kafka中数据的主要单位。事件模拟了某个时间点在世界上发生的事情。在Kafka中,您使用称为记录的数据结构表示每个事件。记录中包含几种不同类型的数据:键,值,时间戳,主题,分区,偏移量和标题。
记录的关键字是表示事件标识的任意数据。如果事件是网页上的点击,则合适的键可能是进行点击的用户的ID。
该值也是代表感兴趣的主要数据的任意数据。click事件的值可能包含发生该事件的页面,被单击的DOM元素以及其他有趣的信息。
该时间戳表示的事件发生时。可以跟踪几种不同的时间。这些在此不再赘述,但他们是有用的了解不过。
的主题和分区描述了较大的收集和事件的子集这一特定事件属于,和偏移描述了较大的集合内它的确切位置(低于更多)。
最后,标头携带有关记录的用户提供的任意元数据。
ksqlDB对其中的一些信息进行了抽象,因此您无需考虑它们。其他的则直接暴露出来,并且是编程模型的组成部分。例如,ksqlDB中数据的基本单位是row。行是对Kafka记录的有用抽象。行具有两种类型的列:键列和值列。它们还带有用于元数据的伪列,例如timestamp。
通常,ksqlDB避免提出不构成高级编程模型的Kafka级别的实现细节。
主题 Topic
主题被称为记录的集合。他们的目的是让您将共同感兴趣的事件放在一起。一系列点击记录可能会存储在“点击”主题中,以便您可以在一个位置访问所有这些记录。主题是仅追加的。将记录添加到主题后,就无法单独更改或删除它。
对于可以将哪些类型的记录放入主题中,没有任何规则。他们不需要遵循相同的结构,涉及相同的情况或类似情况。您管理主题发布的方式完全取决于用户约定和执行。
ksqlDB通过流和表在主题上提供了更高级别的抽象。流或表将模式与Kafka主题相关联。该模式控制允许存储在主题中的记录的形状。这种静态类型可以使您更轻松地了解主题中的行类型,并且通常可以帮助您减少处理行的错误。
分区 Partition
将记录放入主题中时,会将其放入特定的分区中。分区是按偏移量记录的完全有序序列。主题可能具有多个分区,以使存储和处理更具可伸缩性。创建主题时,可以选择一个主题。
当您将记录追加到主题时,分区策略会选择将其存储在哪个分区中。有很多分区策略。最常见的一种是将记录的键的内容与分区总数进行哈希运算。这具有将具有相同标识的所有记录放入同一分区的效果,这由于强大的排序保证而很有用。
记录的顺序由一条称为偏移量的数据跟踪,偏移量是在追加记录时设置的。偏移量为10的记录早于偏移量为20的同一分区中的记录发生。
这里的许多机制都是由ksqlDB代表您自动处理的。创建流或表时,可以选择基础主题的分区数,以便可以控制其可伸缩性。声明模式时,可以选择哪些列是键的一部分,哪些列是值的一部分。除此之外,您无需考虑各个分区或偏移量。这里有一些例子。
处理记录时,将对其键内容进行哈希处理,以便其新的下游分区将与具有相同键的所有其他记录保持一致。附加记录后,即使出现故障或错误,它们也会遵循正确的偏移顺序。当流的主要内容发生变化,因为查询想如何处理行(通过GROUP BY或PARTITION BY),基础记录键被重新计算,并记录发送到一个新的分区在新的主题组进行计算。
生产者和消费者
生产者和消费者促进记录在主题之间的移动。当应用程序想要发布记录或订阅记录时,它会调用API(通常称为client)来这样做。客户端通过结构化网络协议与代理进行通信(请参见下文)。
消费者从某个主题中读取记录时,他们从不删除或以任何方式对其进行突变。能够重复读取相同信息的这种模式有助于以一种无冲突的方式在同一数据集上构建多个应用程序。它也是支持“重播”的主要构建块,其中应用程序可以倒回其事件流并再次读取旧信息。
生产者和消费者公开了一个相当低级的API。您需要构造自己的记录,管理其架构,配置其序列化以及处理将内容发送到何处。
ksqlDB表现为高级别的,连续的生产者和使用者。您只需声明记录的形状,然后发出描述如何填充,更改和查询数据的高级SQL命令。这些SQL程序被转换为低级客户端API调用,这些调用将为您处理详细信息。
代理/经纪人 Broker
代理是用于存储和管理对主题的访问的服务器。多个代理可以聚集在一起,以高可用性,容错的方式复制主题。客户与经纪人进行通信以读取和写入记录。
当您运行ksqlDB服务器或集群时,其每个节点都与Kafka代理通信以进行处理。从Kafka经纪人的角度来看,每个ksqlDB服务器都像一个客户端。代理上不进行任何处理。ksqlDB的服务器在自己的节点上执行所有计算。
数据序列化
由于没有一种数据格式能够完美解决所有问题,因此Kafka的设计不考虑其记录的键和值部分中的数据内容。当记录从客户端移动到代理时,必须将用户有效负载(键和值)转换为字节数组。这使Kafka可以处理一系列不透明的字节,而无需了解它们的内容。当记录交付给使用者时,这些字节数组需要转换回其原始主题,以对应用程序有意义。转换为字节表示形式或从字节表示形式转换的过程分别称为序列化和反序列化。
生产者将记录发送到主题时,它必须决定使用哪些序列化程序将键和值转换为字节数组。键和值序列化器是独立选择的。使用者收到记录时,必须决定使用哪个反序列化器将字节数组转换回其原始值。串行器和解串器成对出现。如果使用其他反序列化器,则将无法理解字节的内容。
ksqlDB大大提高了序列化的抽象。您无需在流/表创建时使用配置选项声明格式,而无需手动配置序列化器。ksqlDB不必维护有关以哪种方式序列化哪些主题的信息,而是维护有关每个流和表的字节表示形式的元数据。消费者被自动配置为使用正确的解串器。
模式 Schema
尽管序列化到Kafka的记录是不透明的字节,但它们必须具有一些有关其结构的规则,以便可以处理它们。这种结构的一方面是数据的架构,它定义了数据的形状和字段。是整数吗?它是用按键的地图foo,bar和baz?还有别的吗
如果没有任何执行机制,则Schema是隐式的。消费者需要以某种方式知道所生成数据的形式。通常,这是通过使一群人在模式上以口头方式达成共识而发生的。但是,这种方法容易出错。如果可以集中管理,审核和以编程方式实施架构,通常会更好。
Kafka之外的一个项目Confluent Schema Registry帮助进行模式管理。架构注册表使生产者可以向架构注册主题,以便在生成任何其他数据时,如果不符合架构,则将拒绝该主题。消费者可以咨询Schema Registry来找到他们不知道的主题的架构。
不是将生产者,使用者和Schema配置粘合在一起,而是将ksqlDB与Schema Registry透明集成。通过启用配置选项以使两个系统可以相互通信,ksqlDB将所有流和表模式存储在Schema Registry中。然后,任何使用ksqlDB数据的应用程序都可以下载和使用这些模式。此外,ksqlDB可以自动推断现有主题的Schema,因此,当您在其上定义流或表时,无需声明其结构。
消费者群体
使用者程序启动时,它将自己注册到一个使用者组中,多个使用者可以进入该组。每次有资格消费一条记录时,组中的一位消费者便会读取该记录。这有效地为一组流程提供了一种方法来协调和负载平衡记录的消耗。
因为单个主题中的记录打算由组中的一个进程使用,所以预订中的每个分区一次只能由一个使用者读取。每个使用者负责的分区数由源分区的总数除以使用者数来定义。如果使用者动态加入该组,则将重新计算所有权并重新分配分区。如果消费者离开组,则将进行相同的计算。
ksqlDB基于此功能强大的负载平衡原语。当您将持久性查询部署到ksqlDB服务器集群时,工作负载将根据源分区的数量分布在整个集群中。您不需要显式管理组成员身份,因为所有这些都会自动发生。
例如,如果将具有十个源分区的持久查询部署到具有两个节点的ksqlDB集群,则每个节点将处理五个分区。如果您丢失一台服务器,则剩下的唯一一台服务器将自动重新平衡并处理所有十台服务器。如果现在再添加四个服务器,则每个服务器将重新平衡以处理两个分区。
保留和压缩
通常需要一段时间后清理较旧的记录。保留和压缩是执行此操作的两种不同选择。它们都是可选的,可以结合使用。
保留时间定义了一条记录在删除之前要存储多长时间。保留是删除主题中记录的唯一方法之一。此参数在流处理中特别重要,因为它定义了可以重播事件流的时间范围。如果要修复错误,构建新应用程序或对现有逻辑进行回测,则重播非常有用。
使用ksqlDB,您可以直接控制基本流和表的基础主题的保留,因此理解该概念很重要。
相比之下,压缩是在每个Kafka代理上在后台运行的过程,该过程会定期删除每个键中除最新记录以外的所有记录。这是一个可选的选择加入过程。当您的记录代表某种状态的某种更新,而最后一次更新才是最重要的更新时,压缩尤其有用。
ksqlDB直接利用压缩来支持支持其物化表的基础变更日志。它们允许ksqlDB在发生故障转移时存储重建表所需的最少信息量。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



