
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、CPU活动进行监控。他是对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析。vmstat 工具提供了一种低开销的系统性能观察方式。因为 vmstat 本身就是低开销工具,在非常高负荷的服务器上,你需要查看并监控系统的健康情况,在控制窗口还是能够使用vmstat 输出结果.
物理内存和虚拟内存区别
直接从物理内存读写数据要比从硬盘读写数据要快的多,因此,我们希望所有数据的读取和写入都在内存完成,而内存是有限的,这样就引出了物理内存与虚拟内存的概念。
物理内存就是系统硬件提供的内存大小,是真正的内存,相对于物理内存,在linux下还有一个虚拟内存的概念,虚拟内存就是为了满足物理内存的不足而提出的策略,它是利用磁盘空间虚拟出的一块逻辑内存,用作虚拟内存的磁盘空间被称为交换空间(Swap Space)。
作为物理内存的扩展,linux会在物理内存不足时,使用交换分区的虚拟内存,更详细的说,就是内核会将暂时不用的内存块信息写到交换空间,这样以来,物理内存得到了释放,这块内存就可以用于其它目的,当需要用到原始的内容时,这些信息会被重新从交换空间读入物理内存。
linux的内存管理采取的是分页存取机制,为了保证物理内存能得到充分的利用,内核会在适当的时候将物理内存中不经常使用的数据块自动交换到虚拟内存中,而将经常使用的信息保留到物理内存。
要深入了解linux内存运行机制,需要知道下面提到的几个方面:
-
首先,Linux系统会不时的进行页面交换操作,以保持尽可能多的空闲物理内存,即使并没有什么事情需要内存,Linux也会交换出暂时不用的内存页面。这可以避免等待交换所需的时间。
-
其次,linux进行页面交换是有条件的,不是所有页面在不用时都交换到虚拟内存,linux内核根据”最近最经常使用“算法,仅仅将一些不经常使用的页面文件交换到虚拟内存,有时我们会看到这么一个现象:linux物理内存还有很多,但是交换空间也使用了很多。其实,这并不奇怪,例如,一个占用很大内存的进程运行时,需要耗费很多内存资源,此时就会有一些不常用页面文件被交换到虚拟内存中,但后来这个占用很多内存资源的进程结束并释放了很多内存时,刚才被交换出去的页面文件并不会自动的交换进物理内存,除非有这个必要,那么此刻系统物理内存就会空闲很多,同时交换空间也在被使用,就出现了刚才所说的现象了。关于这点,不用担心什么,只要知道是怎么一回事就可以了。
-
最后,交换空间的页面在使用时会首先被交换到物理内存,如果此时没有足够的物理内存来容纳这些页面,它们又会被马上交换出去,如此以来,虚拟内存中可能没有足够空间来存储这些交换页面,最终会导致linux出现假死机、服务异常等问题,linux虽然可以在一段时间内自行恢复,但是恢复后的系统已经基本不可用了。
虚拟内存原理
在系统中运行的每个进程都需要使用到内存,但不是每个进程都需要每时每刻使用系统分配的内存空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。
在Linux内存管理中,主要是通过“调页Paging”和“交换Swapping”来完成上述的内存调度。调页算法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整个进程,而不是部分页面,全部交换到磁盘上。
分页(Page)写入磁盘的过程被称作Page-Out,分页(Page)从磁盘重新回到内存的过程被称作Page-In。当内核需要一个分页时,但发现此分页不在物理内存中(因为已经被Page-Out了),此时就发生了分页错误(Page Fault)。
当系统内核发现可运行内存变少时,就会通过Page-Out来释放一部分物理内存。尽管Page-Out不是经常发生,但是如果Page-out频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作thrashing(颠簸)。
命令格式
vmstat [-a] [-n] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
命令功能
用来显示虚拟内存的信息
命令参数
- -a:显示活跃和非活跃内存
- -f:显示从系统启动至今的fork数量 。
- -m:显示slabinfo
- -n:只在开始时显示一次各字段名称。
- -s:显示内存相关统计信息及多种系统活动数量。
- delay:刷新时间间隔。如果不指定,只显示一条结果。
- count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
- -d:显示磁盘相关统计信息。
- -p:显示指定磁盘分区统计信息
- -S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
- -V:显示vmstat版本信息。
显示虚拟内存使用情况
> vmstat | column -t

column -t是为了表头和数据列对齐,便于查看
表头字段说明
- Procs(进程):
- r: 运行队列中进程数量
- b: 等待IO的进程数量
- Memory(内存):
- swpd: 使用虚拟内存大小
- free: 可用内存大小
- buff: 用作缓冲的内存大小
- cache: 用作缓存的内存大小
Swap:
- si: 每秒从交换区写到内存的大小
- so: 每秒写入交换区的内存大小
- IO:(现在的Linux版本块的大小为1024bytes)
- bi: 每秒读取的块数
- bo: 每秒写入的块数
系统:
- in: 每秒中断数,包括时钟中断。
- cs: 每秒上下文切换数。
- CPU(以百分比表示):
- us: 用户进程执行时间(user time)
- sy: 系统进程执行时间(system time)
- id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。
- wa: 等待IO时间
备注:如果 r经常大于 4 ,且id经常少于40,表示cpu的负荷很重。如果pi,po 长期不等于0,表示内存不足。如果disk 经常不等于0, 且在 b中的队列 大于3, 表示 io性能不好。Linux在具有高稳定性、可靠性的同时,具有很好的可伸缩性和扩展性,能够针对不同的应用和硬件环境调整,优化出满足当前应用需要的最佳性能。因此企业在维护Linux系统、进行系统调优时,了解系统性能分析工具是至关重要的。
5秒时间内进行5次采样
> vmstat 1 5
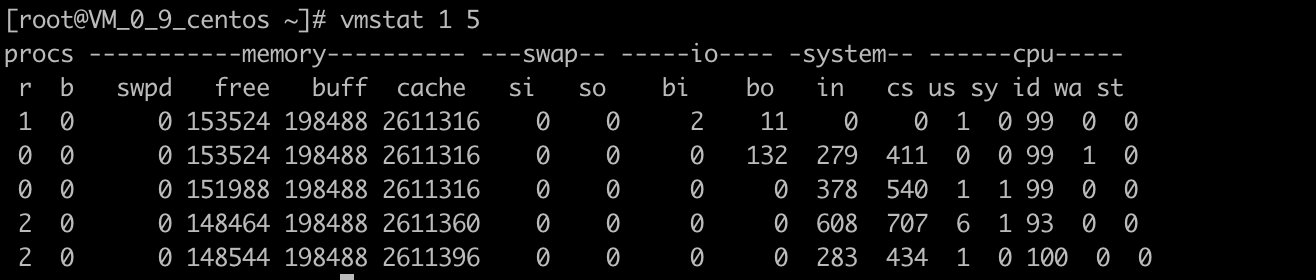
1是采样时间间隔,单位是秒. 5是采样的总次数
显示活跃和非活跃内存
> vmstat -a 1 5
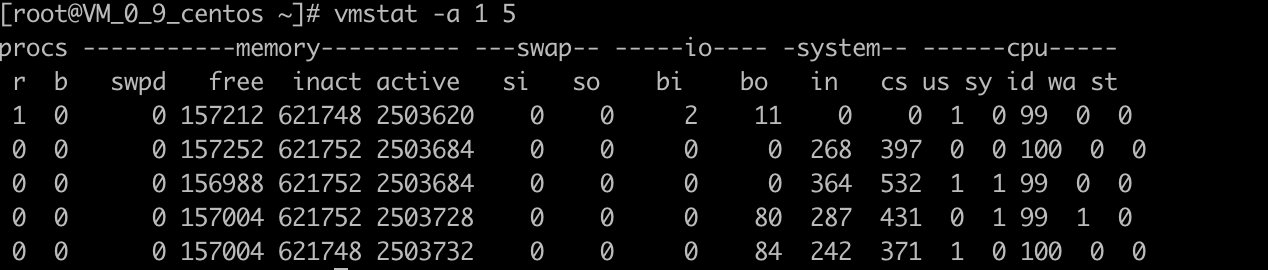
使用-a选项显示活跃和非活跃内存时,所显示的内容除增加inact和active外,其他显示内容与例子1相同。
Memory(内存)
- inact: 非活跃内存大小(当使用-a选项时显示)
- active: 活跃的内存大小(当使用-a选项时显示)
查看系统已经fork了多少次
> vmstat -f
164889872 forks
这个数据是从
/proc/stat中的processes字段里取得的
查看内存使用的详细信息
> vmstat -s
3882032 K total memory
921952 K used memory
2505960 K active memory
621748 K inactive memory
154180 K free memory
198460 K buffer memory
2607440 K swap cache
0 K total swap
0 K used swap
0 K free swap
111113294 non-nice user cpu ticks
17688 nice user cpu ticks
52090953 system cpu ticks
17962243142 idle cpu ticks
20022667 IO-wait cpu ticks
0 IRQ cpu ticks
888181 softirq cpu ticks
0 stolen cpu ticks
442073539 pages paged in
2006672432 pages paged out
0 pages swapped in
0 pages swapped out
252048353 interrupts
2496649494 CPU context switches
1524477152 boot time
164890019 forks
这些信息的分别来自于
/proc/meminfo,/proc/stat和/proc/vmstat
查看磁盘的读/写
> vmstat -d

这些信息主要来自于/proc/diskstats.merged:表示一次来自于合并的写/读请求,一般系统会把多个连接/邻近的读/写请求合并到一起来操作.
查看/dev/sda1磁盘的读/写
> vmstat -p /dev/vda1
vda1 reads read sectors writes requested writes
30818491 884145470 230580804 4013352345
这些信息主要来自于
/proc/diskstats。
- reads:来自于这个分区的读的次数。
- read sectors:来自于这个分区的读扇区的次数。
- writes:来自于这个分区的写的次数。
- requested writes:来自于这个分区的写请求次数。
查看系统的slab信息
> vmstat -m
Cache Num Total Size Pages
isofs_inode_cache 12 12 640 12
ext4_groupinfo_4k 420 420 136 30
ext4_inode_cache 208902 208995 1032 15
ext4_xattr 92 92 88 46
ext4_free_data 1408 1408 64 64
ext4_allocation_context 64 64 128 32
ext4_io_end 3416 3528 72 56
ext4_extent_status 96068 257346 40 102
jbd2_journal_handle 170 170 48 85
jbd2_journal_head 900 900 112 36
jbd2_revoke_table_s 256 256 16 256
jbd2_revoke_record_s 1152 1664 32 128
ip6_dst_cache 36 36 448 18
RAWv6 13 13 1216 13
UDPLITEv6 0 0 1216 13
UDPv6 26 26 1216 13
tw_sock_TCPv6 240 240 256 16
TCPv6 76 135 2176 15
cfq_queue 34 34 232 17
Cache Num Total Size Pages
bsg_cmd 0 0 312 13
mqueue_inode_cache 18 18 896 18
hugetlbfs_inode_cache 13 13 608 13
configfs_dir_cache 92 92 88 46
dquot 208 208 256 16
userfaultfd_ctx_cache 0 0 128 32
fanotify_event_info 2044 2044 56 73
dnotify_mark 630 952 120 34
pid_namespace 0 0 2176 15
posix_timers_cache 0 0 248 16
UDP-Lite 0 0 1088 15
flow_cache 0 0 144 28
xfrm_dst_cache 0 0 576 14
UDP 135 135 1088 15
tw_sock_TCP 256 256 256 16
TCP 144 144 1984 16
scsi_data_buffer 0 0 24 170
blkdev_queue 15 15 2128 15
blkdev_requests 63 63 384 21
Cache Num Total Size Pages
blkdev_ioc 195 195 104 39
user_namespace 0 0 280 14
sock_inode_cache 185 252 640 12
net_namespace 0 0 4992 6
shmem_inode_cache 855 888 680 12
Acpi-ParseExt 3472 3472 72 56
Acpi-Namespace 510 510 40 102
taskstats 24 24 328 12
proc_inode_cache 22416 22980 656 12
sigqueue 50 50 160 25
bdev_cache 38 38 832 19
sysfs_dir_cache 12276 12276 112 36
inode_cache 8602 8840 592 13
dentry 760606 769671 192 21
iint_cache 0 0 80 51
selinux_inode_security 9843 9843 80 51
buffer_head 337830 354003 104 39
vm_area_struct 5411 5940 216 18
mm_struct 180 240 1600 20
Cache Num Total Size Pages
files_cache 173 204 640 12
signal_cache 147 168 1152 14
sighand_cache 137 180 2112 15
task_xstate 361 361 832 19
task_struct 202 224 4016 8
anon_vma 2604 3162 80 51
shared_policy_node 9652 12325 48 85
numa_policy 15 15 264 15
radix_tree_node 97524 106330 584 14
idr_layer_cache 240 240 2112 15
dma-kmalloc-8192 0 0 8192 4
dma-kmalloc-4096 0 0 4096 8
dma-kmalloc-2048 0 0 2048 16
dma-kmalloc-1024 0 0 1024 16
dma-kmalloc-512 32 32 512 16
dma-kmalloc-256 0 0 256 16
dma-kmalloc-128 0 0 128 32
dma-kmalloc-64 0 0 64 64
dma-kmalloc-32 0 0 32 128
Cache Num Total Size Pages
dma-kmalloc-16 0 0 16 256
dma-kmalloc-8 0 0 8 512
dma-kmalloc-192 0 0 192 21
dma-kmalloc-96 0 0 96 42
kmalloc-8192 28 44 8192 4
kmalloc-4096 86 128 4096 8
kmalloc-2048 354 512 2048 16
kmalloc-1024 1135 1360 1024 16
kmalloc-512 638 688 512 16
kmalloc-256 1907 2704 256 16
kmalloc-192 99755 99855 192 21
kmalloc-128 11290 11616 128 32
kmalloc-96 2028 2352 96 42
kmalloc-64 11465 25600 64 64
kmalloc-32 1792 1792 32 128
kmalloc-16 2816 2816 16 256
kmalloc-8 3584 3584 8 512
kmem_cache_node 192 192 64 64
kmem_cache 112 112 256 16
这组信息来自于
/proc/slabinfo
slab:由于内核会有许多小对象,这些对象构造销毁十分频繁,比如i-node,dentry,这些对象如果每次构建的时候就向内存要一个页(4kb),而其实只有几个字节,这样就会非常浪费,为了解决这个问题,就引入了一种新的机制来处理在同一个页框中如何分配小存储区,而slab可以对小对象进行分配,这样就不用为每一个对象分配页框,从而节省了空间,内核对一些小对象创建析构很频繁,slab对这些小对象进行缓冲,可以重复利用,减少内存分配次数。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



