
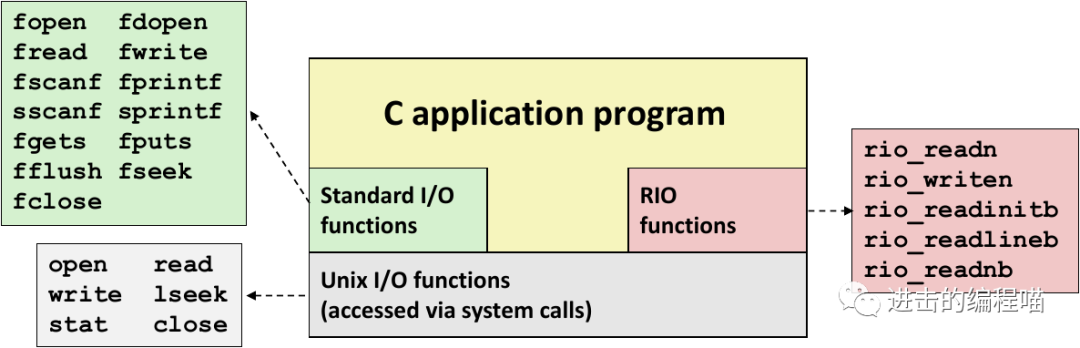
0. 学习原因
大多时候,高级别I/O函数工作良好,没必要直接用Unix I/O,为何需学习?
-
了解Unix I/O将帮助理解其他系统概念。I/O是系统操作不可或缺的部分,因此经常遇到I/O和其他系统概念之间的循环依赖
-
有时必须用Unix I/O,用高级I/O不太可能或不合适,如标准I/O库没提供读取文件元数据的方式,此外I/O库存在一些问题
1. Unix I/O
输入/输出(I/O)是主存和外部设备之间复制数据的过程,在 Linux 中,文件就是字节的序列。所有的 I/O 设备(如网络、内核、磁盘和终端等)都被模型化为文件,而所有的输入和输出都被当作对相应文件的读和写来执行。这种将设备映射为文件的机制,允许内核引出简单、优雅的应用接口Unix I/O,使得所有输入和输出都以统一的方式执行,如 open()/close() 打开/关闭文件,read()/ write() 读/写文件。seek()改变当前文件位置。Unix I/O主要分为两大类:
为区分不同文件的类型,会有一个 type 来进行区别:
-
普通文件:包含任意数据
-
目录:相关文件组的索引
-
Socket:用于另一台机器上的进程通信
还有一些特别的类型仅做了解:命名管道(FIFOs)、符号链接、字符和块设备
普通文件
普通文件包含任意数据,应用程序通常需区分文本文件和二进制文件。前者只包含 ASCII 或 Unicode 字符。除此之外的都是二进制文件(对象文件, JPEG 图片, 等等)。内核不能区分出区别。
文本文件是文本行的序列,每行以 \n 结尾,新行是 0xa,和 ASCII 码中LF一样。不同系统判断行结束的符号不同(End of line, EOL),Linux & Mac OS是\n(0xa)等价line feed(LF),而Windows & 网络协议是\r\n (0xd 0xa)等价Carriage return(CR) followed by line feed(LF)
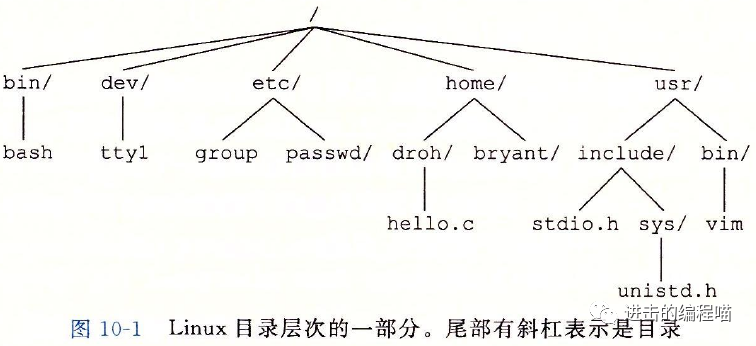
目录
目录包含一个链接(link)数组,且每个目录至少包含两记录:.(dot) 当前目录、..(dot dot) 上层目录
操作命令主要有 mkdir, ls, rmdir。目录以树状结构组织,根目录是 /(slash)。
内核会为每个进程保存当前工作目录(cwd, current working directory),可用 cd 命令进行更改。通过路径名来确定文件的位置,分为绝对路径和相对路径。
2. 文件操作
2.1 打开文件
打开文件会通知内核已准备好访问该文件
int fd; // 文件描述符 file descriptor
if ((fd = open("/etc/hosts", O_RDONLY)) < 0)
{
perror("open");
exit(1);
}
返回值是一个小的整型称为文件描述符(file descriptor),若该值等于 -1 则说明发生错误。每个由 Linux shell创建的进程都会默认打开三个文件(注意这里的文件概念):
-
0: standard input(stdin)
-
1: standard output(stdout)
-
2: standar error(stderr)
2.2 关闭文件
关闭文件会通知内核已完成对该文件的访问
int fd; // 文件描述符
int retval; // 返回值
int ((retval = close(fd)) < 0)
{
perror("close");
exit(1);
}
关闭一个已经关闭的文件是线程程序中的灾难(稍后会详细介绍),所以一定要检查返回值,哪怕是看似良好的函数如 close()
2.3 读取文件
读取文件将字节从当前文件位置复制到内存,然后更新文件位置
char buf[512];
int fd;
int nbytes
// 打开文件描述符,并从中读取 512 字节的数据
if ((nbytes = read(fd, buf, sizeof(buf))) < 0)
{
perror("read");
exit(1);
}
返回值是读取的字节数量,是一个 ssize_t 类型(其实就是一个有符号整型),如果 nbytes < 0 那么表示出错。nbytes < sizeof(buf) 这种情况(short counts) 是可能发生的,而且并不是错误。
2.4 写入文件
写入文件将字节从内存复制到当前文件位置,然后更新当前文件位置
char buf[512];
int fd;
int nbytes;
// 打开文件描述符,并向其写入 512 字节的数据
if ((nbytes = write(fd, buf, sizeof(buf)) < 0)
{
perror("write");
exit(1);
}
返回值是写入的字节数量,如果 nbytes < 0 表示出错。nbytes < sizeof(buf) 这种情况(short counts) 是可能发生的,且不是错误。
2.5 读取目录
可用readdir系列函数读取目录的内容,每次对readdir的调用返回的都是指向流dirp中下一个目录项的指针,或没有更多目录项则返回NULL,每个目录项都有结构体:
struct dirent{
ino_t d_ino; /* inode number */
char d_name[256]; /* filename */
};
2.6 简单Unix I/O 例子
拷贝文件到标准输出,一次一个字节:
#include "csapp.h"
int main(int argc, char *argv[])
{
char c;
int infd = STDIN_FILENO;
if (argc == 2) {
infd = Open(argv[1], O_RDONLY, 0);
}
while(Read(infd, &c, 1) != 0)
Write(STDOUT_FILENO, &c, 1);
exit(0);
}
前面提到的 short count 会在下面的情形下发生:
-
读取的时遇到 EOF(end-of-file)
-
从终端中读取文本行
-
读和写网络 sockets
但下面的情况下不会发生
-
从磁盘文件中读取(除 EOF 外)
-
写入到磁盘文件中
最好总是允许 short count,这样就可以避免处理这么多不同的情况。
#include "csapp.h"
#define BUFSIZE 64
int main(int argc, char *argv[])
{
char buf[BUFSIZE];
int infd = STDIN_FILENO;
if (argc == 2) {
infd = Open(argv[1], O_RDONLY, 0);
}
while((nread = Read(infd, buf, BUFSIZE)) != 0)
Write(STDOUT_FILENO, buf, nread);
exit(0);
}
3. 元数据
元数据是用来描述数据的数据,由内核维护,可以通过 stat 和 fstat 函数来访问,结构是:
struct stat
{
dev_t st_dev; // Device
ino_t st_ino; // inode
mode_t st_mode; // Protection & file type
nlink_t st_nlink; // Number of hard links
uid_t st_uid; // User ID of owner
gid_t st_gid; // Group ID of owner
dev_t st_rdev; // Device type (if inode device)
off_t st_size; // Total size, in bytes
unsigned long st_blksize; // Blocksize for filesystem I/O
unsigned long st_blocks; // Number of blocks allocated
time_t st_atime; // Time of last access
time_t st_mtime; // Time of last modification
time_t st_ctime; // Time of last change
}
对应的访问例子:
int main (int argc, char **argv)
{
struct stat stat;
char *type, *readok;
Stat(argv[1], &stat);
if (S_ISREG(stat.st_mode)) // 确定文件类型
type = "regular";
else if (S_ISDIR(stat.st_mode))
type = "directory";
else
type = "other";
if ((stat.st_mode & S_IRUSR)) // 检查读权限
readok = "yes";
else
readok = "no";
printf("type: %s, read: %s\n", type, readok);
exit(0);
}
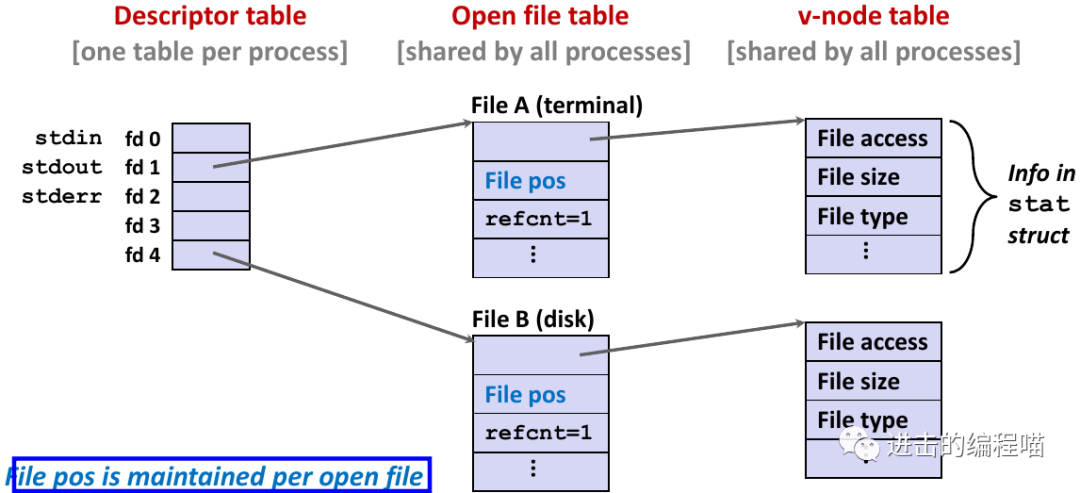
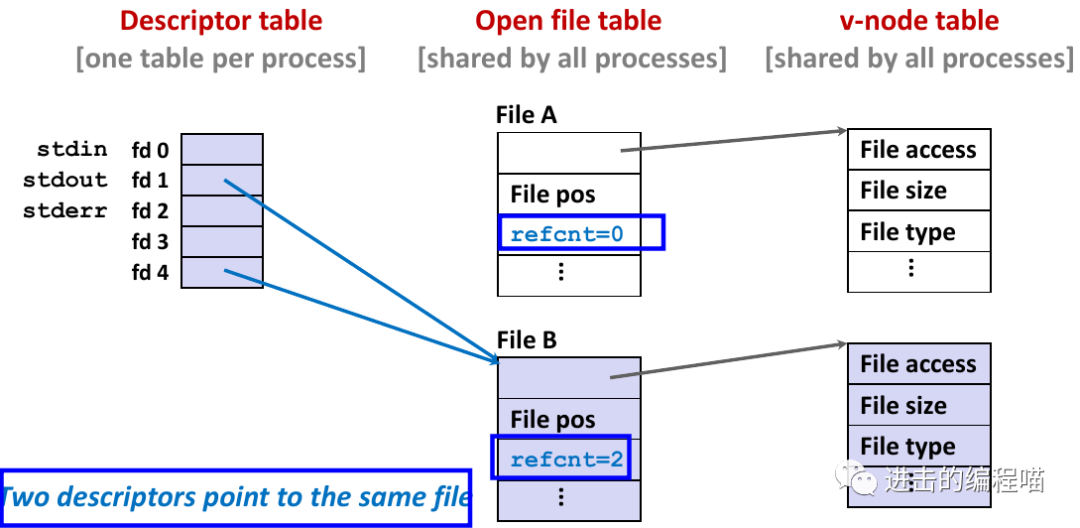
3.1 共享文件
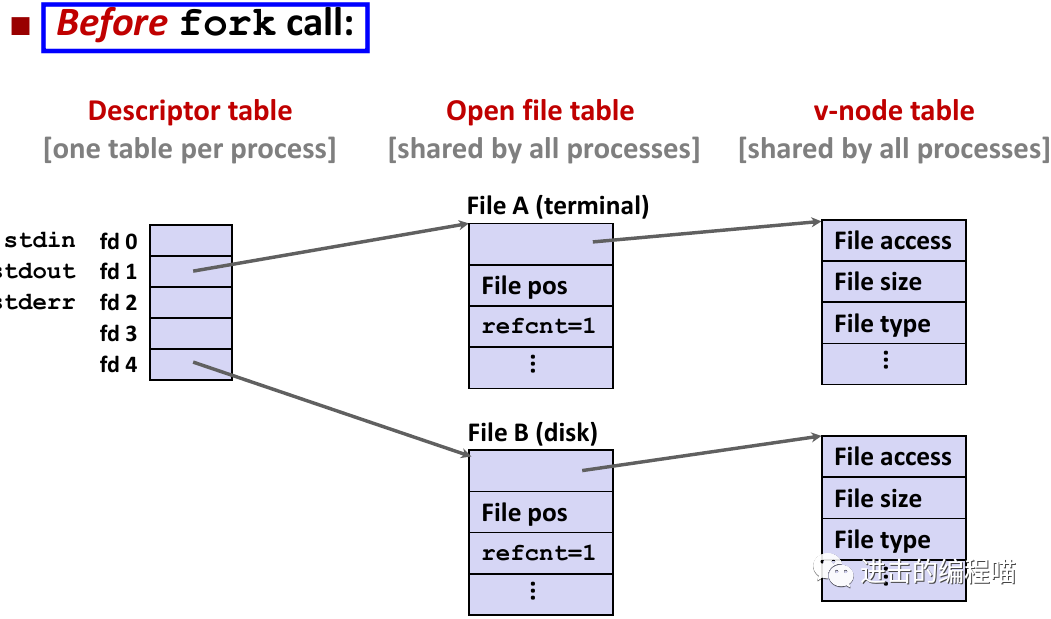
可用许多不同的方式共享Linux文件。要理解文件共享就得理解三个表示打开文件的数据结构。
-
描述符表:每个进程都有独立的描述符表,表项是进程打开的文件描述符索引,每个打开的描述符表指向文件表中的一个表项
-
文件表:打开文件的集合是由一张文件表表示,所有进程共享该表,每个文件表的表项组成包括当前文件位置、引用计数、指向v-node表中对应表项的指针。关闭描述符减少文件表项引用计数直到为0会删除文件表项
-
v-node表:同文件表一样所有进程共享该v-node表,每个表包含stat结构中的大多数信息,包括st_mode和st_size成员
两个描述符引用两个不同的打开文件。描述符 1(stdout)指向终端,描述符 4 指向打开的磁盘文件
两个不同的描述符通过两个不同的打开文件表条目共享同一个磁盘文件,使用相同的文件名参数调用 open 两次,关键思想是每个描述符都有自己的文件位置,所以对不同描述符的读操作可从文件不同位置获取数据
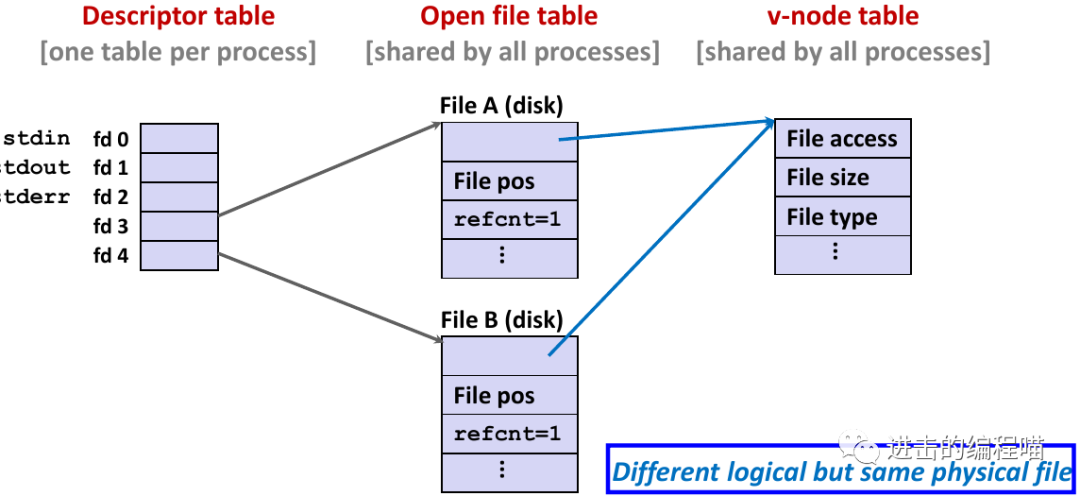
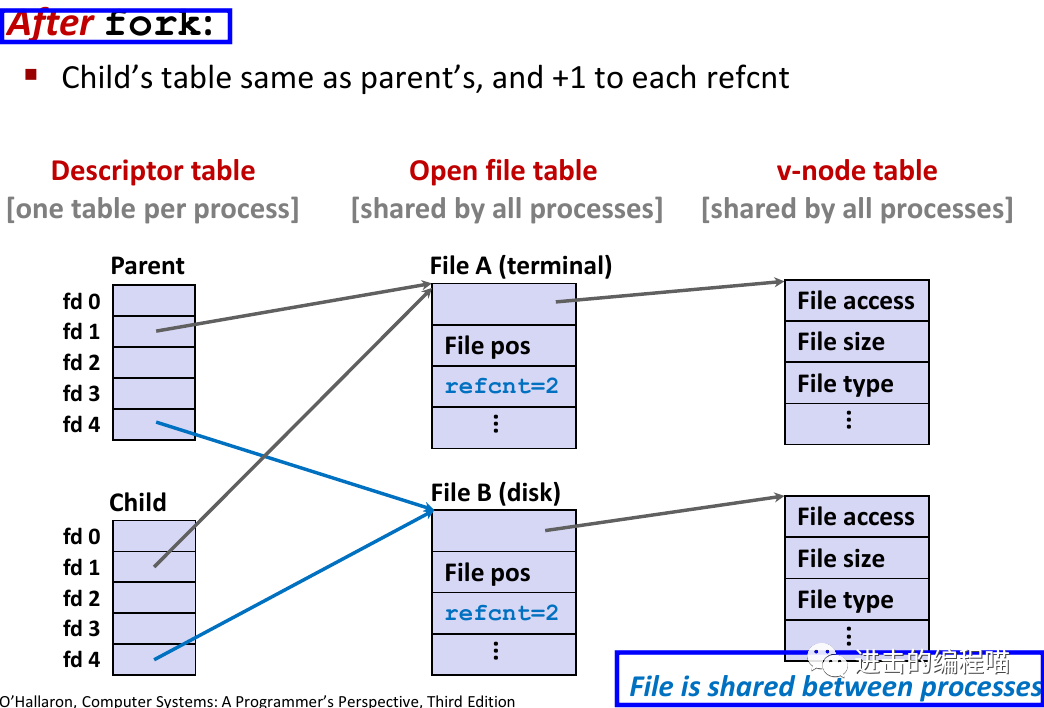
3.2 进程如何共享文件:fork
子进程继承其父进程的打开文件,注意:exec 函数不会改变情况(使用 fcntl 来改变)
在 fork 之后,子进程实际上和父进程的指向是一样的,这里需要注意的是会把引用计数加 1
4. I/O重定向
了解了这个,就知道重定向如何实现。其实很简单,只要调用 dup2(oldfd, newfd)函数即可。改变文件描述符指向的文件,就完成重定向,下图中我们把原来指向终端的文件描述符指向了磁盘文件,也就把终端上的输出保存在了文件中:
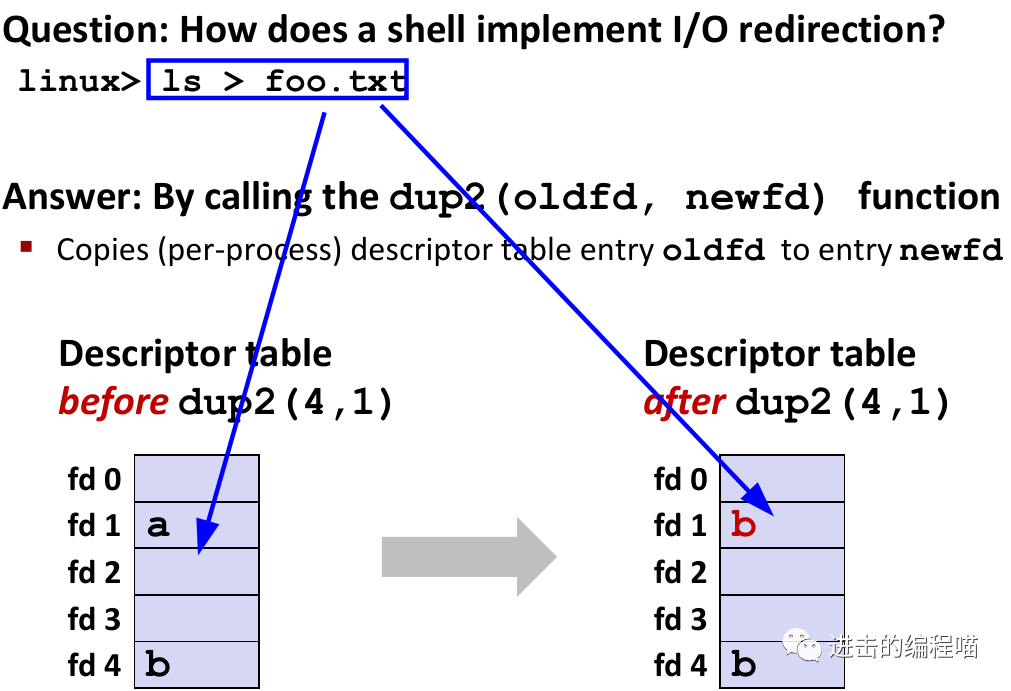
具体来说:
-
打开标准输出应该重定向到的文件,发生在执行 shell 代码的子进程中,在 exec 之前

-
调用
dup2(4,1),导致fd=1 (stdout) 引用 fd=4 指向的磁盘文件,注意引用计数的变化
4.1 I/O重定向的例子

4.2 进程控制和I/O

5. 标准I/O
C标准库中包含一系列高层的标准 IO 函数,比如
-
打开和关闭文件:
fopen,fclose -
读取和写入字节:
fread,fwrite -
读取和写入行:
fgets,fputs -
格式化读取和写入:
fscanf,fprintf
标准 IO 会用流的形式打开文件,所谓流(stream)实际是文件描述符和缓冲区(buffer)在内存中的抽象。C 程序一般以三个流开始,如下所示:
#include <stdio.h>
extern FILE *stdin; // 标准输入 descriptor 0
extern FILE *stdout; // 标准输出 descriptor 1
extern FILE *stderr; // 标准错误 descriptor 2
int main()
{
fprintf(stdout, "Hello, Da Wang\n");
}
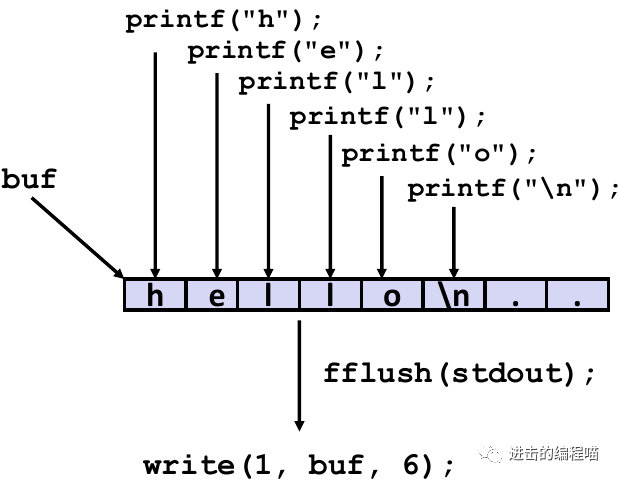
用缓冲区的原因,程序经常会一次读/写一个字符,比如 getc, putc, ungetc,同时也会一次读/写一行,比如 gets, fgets。如果用 Unix I/O 的方式来进行调用是非常昂贵的, read 和 write 因需内核调用,需大于10000 个时钟周期。
办法是用 read 一次读取一块数据,再由高层的用户输入函数,一次从缓冲区读取一个字符(当缓冲区用完的时候需要重新填充)

5.1 标准I/O中的缓冲
标准I/O函数使用缓冲的I/O,缓冲区通过\n刷新到输出fd,调用fflush或exit,或从main返回
可通过strace程序看缓冲如何起作用
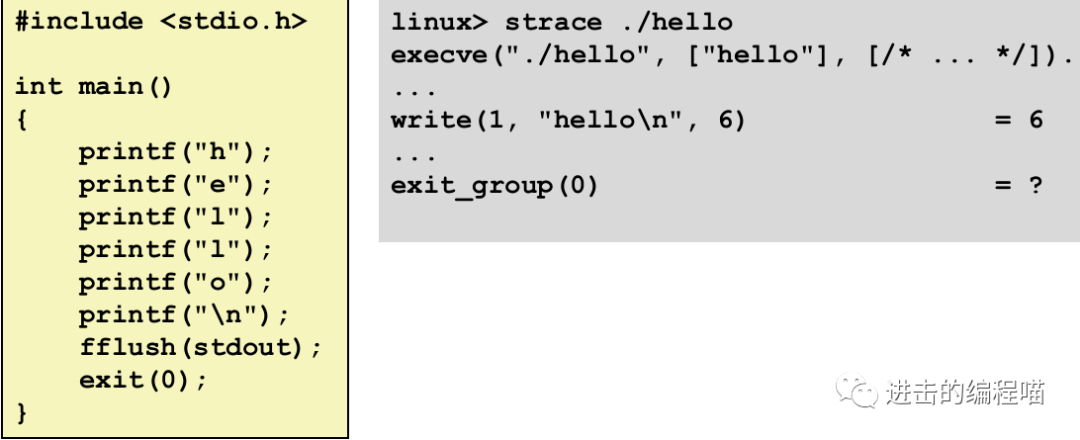
6. RIO
RIO和C准库IO库是在Unix I/O上构建的两个不兼容的库,RIO提供了方便高效的IO访问,可以从一个描述符中读二进制非缓存输入和输出、缓存的文本行和二进制数据(线程安全可在同一描述符上任意交叉使用)。有两类输入输出函数:
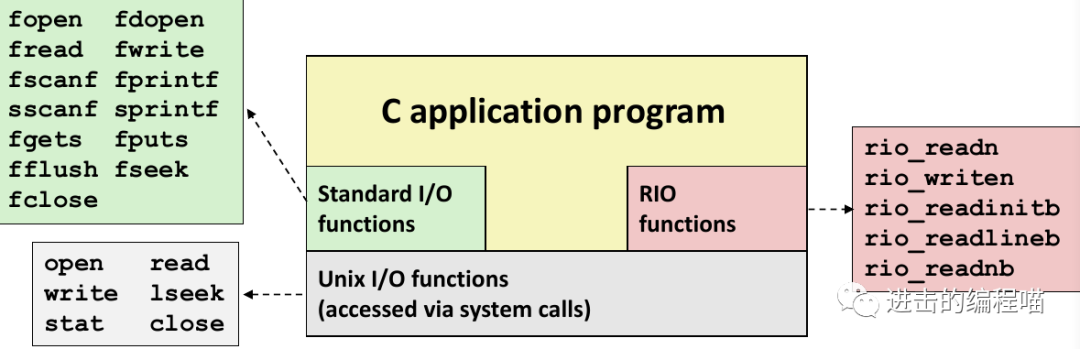
① 无缓冲输入输出:和Unix的read/write接口相同,对网络传输数据尤其有用
对于同一个描述表,可以任意的交错调用rio_readn和rio_wiriten
/*
* rio_readn - Robustly read n bytes (unbuffered)
*/
ssize_t rio_readn(int fd, void *usrbuf, size_t n)
{
size_t nleft = n;
ssize_t nread;
char *bufp = usrbuf;
while (nleft > 0) {
if ((nread = read(fd, bufp, nleft)) < 0) {
if (errno == EINTR) /* Interrupted by sig handler return */
nread = 0;/* and call read() again */
else
return -1;/* errno set by read() */
}
else if (nread == 0)
break;/* EOF */
nleft -= nread;
bufp += nread;
}
return (n - nleft);/* Return >= 0 */
}
从上面的代码不难看出,如果程序的信号处理程序返回中断,这个函数会手动重启read或者write。
② 带缓冲的输入函数
这个函数有一个好处是,它从内部读缓冲区拷贝的一行,能有效地从部分缓存在内部内存缓冲区中的文件中读取文本行和二进制数据,当缓冲区为空的时候,自动调用read填满缓冲区,效率很高。
ssize_t rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen);,rio_readlineb从文件fd中读取最多maxlen字节的文本行,并将其存储在usrbuf中,当读到maxlen字节、EOF发生、\n发生时停止。
ssize_t rio_readnb(rio_t *rp, void *usrbuf, size_t n);,rio_readnb从文件fd读取最多n个字节,当读到n个字节、EOF发生时停止,对rio_readlineb和rio_readnb的调用可以在同一个描述符上任意交错
缓存IO实现
读文件时,文件有关联的缓冲区来保存已经从文件中读取但还没有被用户代码读取的字节
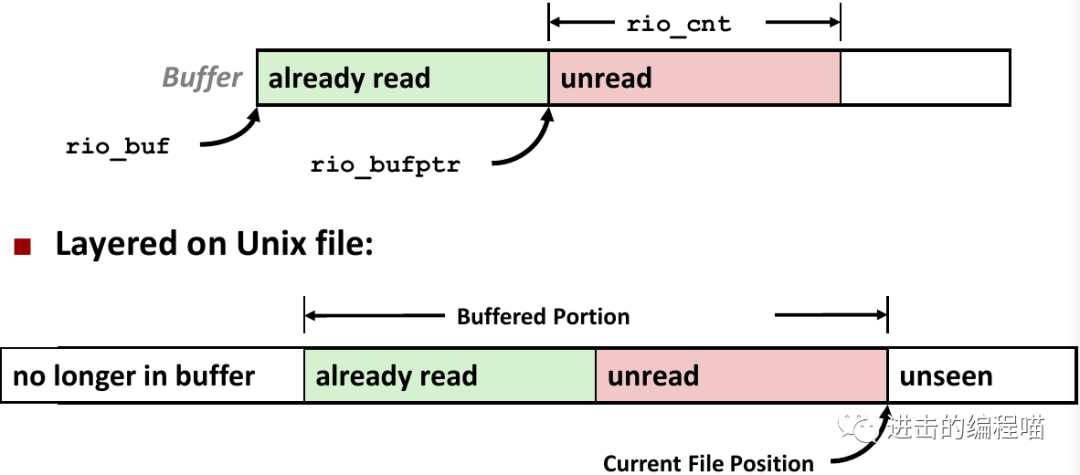
缓存IO声明
typedef struct {
int rio_fd;/* descriptor for this internal buf */
int rio_cnt;/* unread bytes in internal buf */
char *rio_bufptr;/* next unread byte in internal buf */
char rio_buf[RIO_BUFSIZE]; /* internal buffer */
} rio_t;

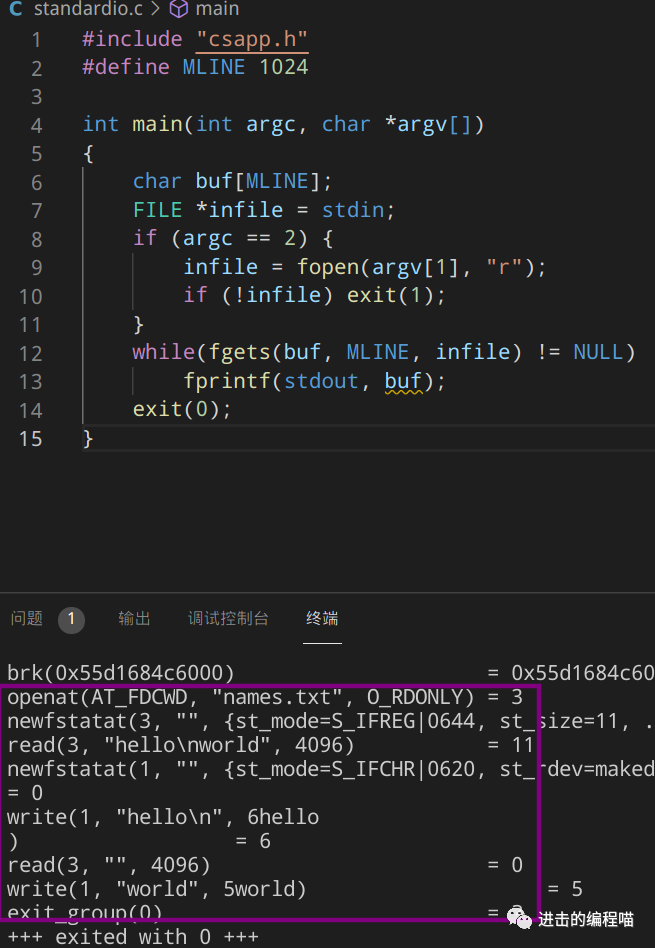
#include "csapp.h"
#define MLINE 1024
int main(int argc, char *argv[])
{
rio_t rio;
char buf[MLINE];
int infd = STDIN_FILENO;
ssize_t nread = 0;
if (argc == 2) {
infd = Open(argv[1], O_RDONLY, 0);
}
Rio_readinitb(&rio, infd);
while((nread = Rio_readlineb(&rio, buf, MLINE)) != 0)
Rio_writen(STDOUT_FILENO, buf, nread);
exit(0);
}
复制文件到标准输出,用mmap加载整个文件
#include "csapp.h"
int main(int argc, char **argv)
{
struct stat stat;
if (argc != 2) exit(1);
int infd = Open(argv[1], O_RDONLY, 0);
Fstat(infd, &stat);
size_t size = stat.st_size;
char *bufp = Mmap(NULL, size, PROT_READ,MAP_PRIVATE, infd, 0);
Write(1, bufp, size);
exit(0);
}
7. 总结
Unix I/O 是最底层的,通过系统调用进行操作,C的标准I/O库建立在此之上,对应的函数为:
| I/O | 优点 | 缺点 |
|---|---|---|
| Unix I/O | 最通用最底层的I/O方法,异步信号安全,即可在信号处理器中调用,提供访问文件元数据的功能 | 底层和基础,故需处理的情况多且易错,高效率的读写需缓冲区,也易错,这是标准I/o要解决的问题 |
| 标准I/O | 缓冲通过减少读和写系统调用的数量来提高效率,短计数即获得的字符没达到SIZE的问题 | 不提供文件元数据访问功能,标准I/O非异步信号安全,不适合信号处理和网络套接字输入/出 |
选择I/O函数
通用规则:尽量用高层的I/O函数,但理解用的函数。当用磁盘或终端文件时,用标准I/O,在信号处理程序内部,极少数需要最高性能时用Unix I/O

处理二进制文件
任意字节序列,包含0x00的字节的二进制文件,永远不要用面向文本的I/O,如fgets、scanf等,而使用rio_readn或rio_readnb,以及字符串函数,如strlen、strcpy、strcat等。

共同学习,写下你的评论
评论加载中...
作者其他优质文章



