
在这里主要向大家做一个 Databend 性能调优相关的分享,共会分为三次向大家介绍,如下所示:
1、基础篇:代码调优的前置知识
2、实践篇1:Databend 源码性能调优实践
3、实践篇2:Databend 的 Group By 聚合查询为什么跑的这么快?
背景
SELECT max(number),
sum(number) FROM numbers_mt(1000000000) GROUP BY number % 3,
number % 4, number % 5 LIMIT 10;
在早期 Databend 的版本中,我们为了衡量分组聚合性能,在性能测试上忽略了 IO 的开销,但上述 SQL 的运行即使在内存表的场景下也运行的很低效,吞吐只约有 700MB/s,对比 clickhouse 的吞吐有 4GB/s,差距有七八倍左右。因此我们花了很多精力在调优上述查询。本文将介绍下我们如何调优 Databend 的 Group By 聚合查询的。
优化分组操作
下图所示,早期的分组我们引入了一个 hashmap,在查询分组的时候,我们将 block 按照对应的 key 打散到不同的 value entry 中,每个 value entry 对应一个小的 block,这样我们可以对小的 block 进行向量化 sum 的计算,sum后的结果再和其他 blocks hash 打散 sum 后的结果按 hash key 进行 merge。
这个过程十分的自然且简单,但它工作的十分低效。
-
首先是 block 打散成子 block,这里会涉及多次内存的分配和拷贝,将内存从大的 block 拷贝到新的 block 中。并且在 key 的规模很大的时候,这个分配拷贝的次数也会增多,性能进一步的下降。
-
其次是虽然子的 block 我们可以复用一下向量化的代码,但经过打散后子 block 的数据长度其实缩小了很多,block 的个数也增加了很多,我们知道 simd 是为了吞吐设计的指令集,在这个场景下,多次 simd 对小数据集进行求和 反而增加了计算的延迟。
无论从内存还是计算的角度考虑,上面的流程都十分不可取。因此我们设计下以下新的流程: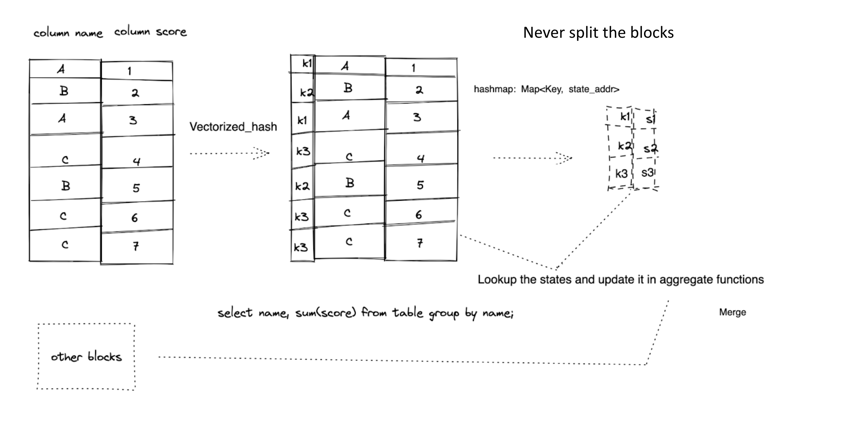
新的流程中,我们不会再去 Split blocks,也就是说 block 还是大的 block,不会再有额外的内存分配和拷贝。但我们还是需要一个 hashmap 来存储分组 key 对应的数据,这里hashmap 存储的 value 不再是一个 block粒度, 而是一个 AggregateState, 代表聚合函数状态的值。
因此我们的计算流程变为:
-
遍历 block 的 key columns,为 block 为每行数据分配一个 hashkey
-
第二次遍历 block,根据对应行的 key 去 hashmap 中找出对应的聚合状态值,如果没有,则分配默认的聚合状态;反之,我们拿出已经有的聚合状态,然后进行状态合并。
-
将 block 级别的聚合状态进行二次合并。
这个流程中,虽然无法沿用手动的向量化代码,但 hashmap 的压力大大的减少了,我们只要存储对应的状态值进行合并,整体测试下来,性能比上个版本提高了 3-4 倍, 是一个非常有象征意义的优化点。
这里插入一个 Spark 新的执行引擎 Photon 在 group by 的一个优化点: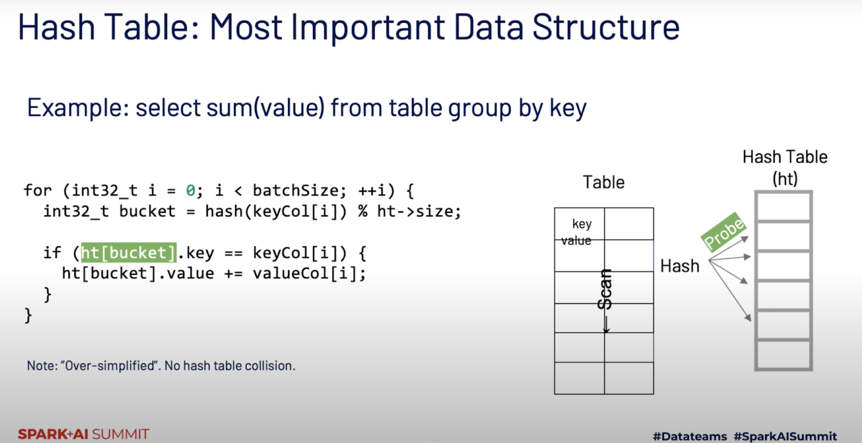
假设没有 hash 冲突的情况下,这里根据 key 从 hashmap probe 到的 value 进行了 merge 操作,这里虽然只有一个循环,但性能表现却不如人意,经过测试发现,66% 的开销在于 memory stalls, 也就是说 CPU 的计算在等待内存访问的延迟。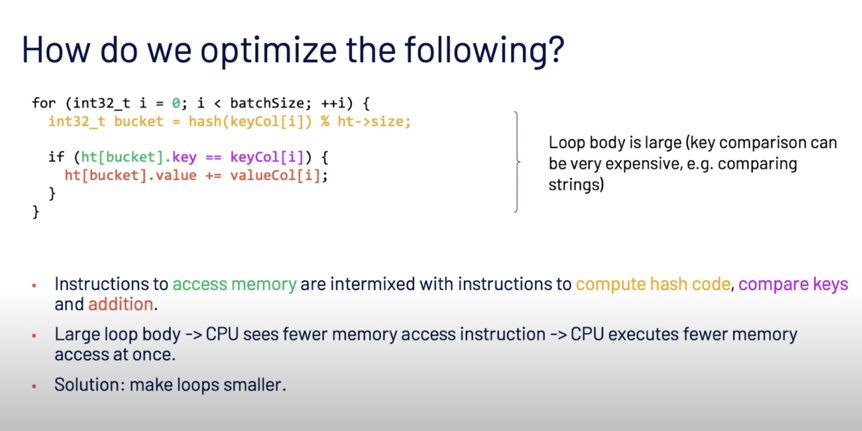

优化的方式是将 loop 拆成多个小的 loop,让 CPU 和内存访问尽量解耦,来提高 CPU 流水线执行。
动态哈希算法
为了进一步优化分组聚合的性能,我们观察到了,其实不同的 SQL GroupBy 的 keys 我们可以用不同的 hash 算法来实现 hashkey 的生成。
在定长的场景下,可以用 u8–>u64 等不同的整形来存储 hashkey,整形 key 的寻址在 hashmap 上也有对应的优化点;在含有 String 的场景下,我们再退化成字节数组的方式存储 hashkey。这样让 hashmap 针对不同的场景能针对性做内存的优化,让 SQL 运行更加高效。
内存池
hashmap 的 value 存储的是聚合 State,为了让 State 的访问尽量触发 cpu cache,我们将 State 分配在一个独立的内存池中,这里使用了 bumpalo 这个 rust crate。
状态合并
另外我们注意到,如果有多个聚合函数,可能需要多个 hashmap 来存储对应的状态,或者 hashmap 对应的 value 需要存储一个聚合状态的数组,这样会增加 hashmap 存储的压力。
结合 SQL 分组查询的特点,即使是多个聚合函数的分组查询,聚合函数对应的 key 对 一行数据来说是唯一固定的,也就是说一个 key 可以对应 多个聚合状态。
那么,我们能不能将多个聚合状态存在一起呢?显然是可以的:
可以把多个聚合状态当做是一个 Struct, 单独的聚合状态作为 Struct 中的成员,这样我们的 hashmap 只要存储 Struct 的地址就行了!通过 Struct 的地址后,我们根据固定长度的 offset 偏移值可以拿到对应位置聚合状态的数据。
流水线 CPU 计算
在上面的 SQL 中,我们发现数值运算中,除法操作或求模操作都存在性能瓶颈。
通过资料发现,除法运算符无法发挥 CPU 流水线执行,他需要 3-30 个 CPU 时钟的延迟,并且除法内部也无法乱序执行,发射时间也和延迟一样,除法的延迟能达到加法的几十倍。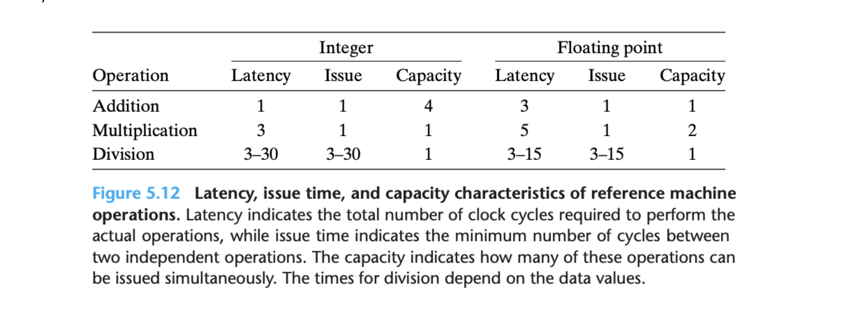
那我们如何去优化 group by number % 3 … 中的求模操作呢?
一个特殊的 case 就是 除数是一个 2^n, 求模操作可以优化为按位取与的操作,number & (2^ - 1)
在其他 case 下,参考了学术界的一些论文:
可以将常量除数下的除法优化成乘法操作:
uint32_t d = ...;// your divisor > 0
uint64_t c = UINT64_C(0xFFFFFFFFFFFFFFFF) / d + 1;
// fastmod computes (n mod d) given precomputed c
uint32_t fastmod(uint32_t n ) {
uint64_t lowbits = c * n;
return ((__uint128_t)lowbits * d) >> 64;
}
工业界也有一些实现,比如:
Databend 中使用的是 Rsut 的 strength_reduce crate 来优化的。
总结
经过上面的若干的优化后,总体测试下来 group by 的性能已经和 clickhouse 不相上下了。上面很多细节的优化也参考了 clickhouse 中的实现,clickhouse 在很多方面的优化都做的非常的细致,源码非常值得一读。
当然,性能优化道路是无止境的,通常是一点点的优化才能积累出一个好的效果,但有的时候 也要跳出一些定势思维,也许不小心就陷入了一些死胡同。这里推荐两本书来作为本文的结尾:
-
CS:APP3e, Bryant and O’Hallaron (cmu.edu)
-
Optimizing software in C++ An optimization guide
共同学习,写下你的评论
评论加载中...
作者其他优质文章



