
创建安装目录 /usr/local/softs
mkdir /usr/local/softs
1. 安装JDK(CentOS)
1.1. 安装jdk之前需要先卸载自带的jdk
1.1.1. 查看自带的jdk
rpm -qa|grep java
1.1.2. 卸载openjdk
rpm -e –nodeps java-1.8.0-openjdk-1.8.0.262.bl0-1.el7.x86_64
2. 安装JDK(RedHat)
2.1. 安装jdk
2.1.1. 新建目录(安装目录只能是usr目录下,不要新建多级目录)
mkdir /usr/java
2.1.2. 解压到指定目录
tar -zxvf /usr/local/softs/jdk-8u211-linux-x64.tar.gz -C /usr/java
2.1.3. 编辑环境变量
vi /etc/profile
2.1.4. 在文件末尾添加(vi操作跳到行尾:大写灯亮按字母G)
JAVA_HOME=/usr/java/jdk1.8.0_211
JRE_HOME=/usr/java/jdk1.8.0_211/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
2.1.5. 刷新环境变量
source /etc/profile
2.1.6. 查看Jdk版本
查看java版本确认安装成功(如果不能查看版本则检查是否存在两级以上的目录)
java –version
如果看不到版本,请重启电脑再次确认
3. 关闭防火墙
systemctl stop firewalld.service
4. 禁止防火墙开机启动
systemctl disable firewalld.service
5. 部署Scala
5.1. 部署Scala
5.1.1. 解压到指定目录
tar -zxvf /usr/local/softs/scala-2.12.10.tgz -C /usr/local
5.1.2. 编辑环境变量
vi /etc/profile
5.1.3. 在“PATH=”上一行添加“export SCALA_HOME=/usr/local/scala-2.12.10”
5.1.4. 在“PATH=”末尾添加“:$SCALA_HOME/bin”
export SCALA_HOME=/usr/local/scala-2.12.10
export PATH=$PATH:${JAVA_HOME}/bin:$SCALA_HOME/bin
5.1.5. 刷新环境变量
source /etc/profile
5.1.6. 输入Scala验证
6. 部署Maven
6.1. 部署Maven
6.1.1. 解压到指定目录
tar -zxvf /usr/local/softs/apache-maven-3.6.3-bin.tar.gz -C /usr/local
6.1.2. 编辑环境变量
vi /etc/profile
6.1.3. 在“PATH=”上一行添加“export MAVEN_HOME=/usr/local/apache-maven-3.6.3”
6.1.4. 在“PATH=”末尾添加“:${MAVEN_HOME}/bin”
export MAVEN_HOME=/usr/local/apache-maven-3.6.3
export PATH=$PATH:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${MAVEN_HOME}/bin
6.1.5. 刷新环境变量
source /etc/profile
6.1.6. 输入 mvn -version 验证
6.1.7. 创建本地仓库目录
mkdir /usr/local/maven_repos
6.1.8. 编辑配置文件
vi /usr/local/apache-maven-3.6.3/conf/settings.xml
6.1.9. 查找字符串“<localRepository>/path/to/local/repo</localRepository>”
6.1.10. 在注释结尾后面添加一行
<localRepository>/usr/local/maven_repos</localRepository>
7. 安装rsync
7.1. 已联网
7.1.1. 执行命令yum install -y rsync
7.1.2. 执行命令yum install -y vim
8. 部署Hadoop(单机)
8.1. 部署Hadoop
8.1.1. 解压到指定目录
tar -zxvf /usr/local/softs/hadoop-3.1.3.tar.gz -C /usr/local
8.1.2. 编辑环境变量
vi /etc/profile
8.1.3. 在“PATH=”上一行添加“export HADOOP_HOME=/usr/local/hadoop-3.1.3”
8.1.4. 在“PATH=”末尾添加“:${HADOOP_HOME}/bin”
export HADOOP_HOME=/usr/local/hadoop-3.1.3
export PATH=$PATH:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${MAVEN_HOME}/bin:${HADOOP_HOME}/bin
8.1.5. 刷新环境变量
source /etc/profile
8.1.6. 修改配置文件
vi /usr/local/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
8.1.7. 查找字符串“export JAVA_HOME”修改
export JAVA_HOME=/usr/java/jdk1.8.0_211
8.1.8. 修改配置文件
vi /usr/local/hadoop-3.1.3/etc/hadoop/core-site.xml
8.1.9. 查找字符串“<configuration>”在标签里添加
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop102:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop_app/tmp/dfs5162</value>
</property>
8.1.10. 修改配置文件
vi /usr/local/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
8.1.11. 查找字符串“<configuration>”在标签里添加
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
8.1.12. 复制文件
cp /usr/local/hadoop-3.1.3/etc/hadoop/mapred-site.xml.template /usr/local/hadoop-3.1.3/etc/hadoop/mapred-site.xml
8.1.13. 修改配置文件
vi /usr/local/hadoop-3.1.3/etc/hadoop/mapred-site.xml
8.1.14. 查找字符串“<configuration>”在标签里添加
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
8.1.15. 修改配置文件
vi /usr/local/hadoop-3.1.3/etc/hadoop/yarn-site.xml
8.1.16. 查找字符串“<configuration>”在标签里添加
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
8.1.17. 修改配置文件
vi /usr/local/hadoop-3.1.3/etc/hadoop/slaves
8.1.18. 将localhost改为主机名(192.168.11.233)
8.1.19. 进入目录
cd /usr/local/hadoop-3.1.3/bin
8.2. 格式化
8.2.1. 执行命令
./hdfs namenode -format
8.2.2. 查看输出界面是否存在
INFO common.Storage: Storage directory /usr/local/hadoop_app/tmp/dfs5162/dfs/name has been successfully formatted
8.2.3. 进入目录
cd /usr/local/hadoop-3.1.3/sbin
8.3. 启动node
8.3.1. 输入命令
./hadoop-daemon.sh start namenode
8.3.2. 输入命令
./hadoop-daemon.sh start datanode
8.3.3. 输入命令
jps
8.3.4. 查看是否存在namenode 和 datanode进程
8.3.5. 查看日志(ctrl+c退出)
tail -200f /usr/local/hadoop-3.1.3/logs/hadoop-root-datanode-ybjgpmdw.log
8.4. 启动manager
8.4.1. 输入命令
./yarn-daemon.sh start resourcemanager
8.4.2. 输入命令
./yarn-daemon.sh start nodemanager
8.4.3. 验证,先进入目录
cd /usr/local/hadoop-3.1.3/share/hadoop/mapreduce
8.4.4. 输入命令
hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.16.2.jar pi 2 3
8.4.5. 查看是否可以输出结果4.000000
8.5. 停止
8.5.1. 停止
./yarn-daemon.sh stop nodemanager
./yarn-daemon.sh stop resourcemanager
./hadoop-daemon.sh stop datanode
./hadoop-daemon.sh stop namenode
9. 部署Hadoop(集群)
9.1. 集群Hadoop
9.1.1. 重复
准备三台服务器,执行步骤2.0到8.1.7(jdk安装 到 部署Hadoop单机 格式化之前)
服务器1:192.168.11.50 hadoop102
服务器2:192.168.11.79 hadoop103
服务器3:192.168.11.141 hadoop104
注:不要直接使用IP地址,一定要起别名(所有机器hosts文件都修改)
9.2. 设置免密登录
9.2.1. 生成密钥
ssh-keygen -t rsa
9.2.2. 发生给其他服务器(其他机器也要执行7.2.1和7.2.2)
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
9.3. 配置分发脚本
9.3.1. 进入用户目录(如果只有root用户则只需要进入home目录)
cd /home
例如本机:cd /home/caeser
9.3.2. 创建文件夹
mkdir bin
9.3.3. 进入文件夹
cd bin
9.3.4. 编辑创建文件
vi xsync
9.3.5. 输入内容(复制粘贴后注意核对内容是否一致)
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if [ $pcount -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
# 也可以采用:
# for host in hadoop{102..104};
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
echo pdir=$pdir
#6. 获取当前文件的名称
fname=$(basename $file)
echo fname=$fname
#7. 通过ssh执行命令:在$host主机上递归创建文件夹(如果存在该文件夹)
ssh $host "mkdir -p $pdir"
#8. 远程同步文件至$host主机的$USER用户的$pdir文件夹下
rsync -av $pdir/$fname $USER@$host:$pdir
else
echo $file does not exists!
fi
done
done
9.3.6. 修改权限
chmod 777 xsync
9.3.7. 编辑环境变量
vi /etc/profile
9.3.8. 在“PATH=”末尾添加“:/home/bin”
export PATH=$PATH:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${MAVEN_HOME}/bin:${HADOOP_HOME}/bin:${ZK_HOME}/bin:${FLUME_HOME}/bin:${KAFKA_HOME}/bin:${SPARK_HOME}/bin:/home/bin
9.3.9. 刷新环境变量
source /etc/profile
9.3.10. 测试脚本
xsync /home/bin
9.4. 服务器1配置
9.4.1. 修改配置文件
vi /usr/local/hadoop-3.1.3/etc/hadoop/core-site.xml
9.4.2. 查找字符串“<configuration>”
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop_app/data</value>
</property>
</configuration>
9.4.3. 修改配置文件
vi /usr/local/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
9.4.4. 查找字符串“<configuration>”
<configuration>
<!-- NameNode web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- SecondaryNameNode web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
9.4.5. 修改配置文件
vi /usr/local/hadoop-3.1.3/etc/hadoop/yarn-site.xml
9.4.6. 查找字符串“<configuration>”
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
9.4.7. 修改配置文件
vi /usr/local/hadoop-3.1.3/etc/hadoop/mapred-site.xml
9.4.8. 查找字符串“<configuration>”在标签里添加
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
9.4.9. 分发配置文件
xsync /usr/local/hadoop-3.1.3/etc/hadoop/
9.4.10. 配置workers
vim /usr/local/hadoop-3.1.3/etc/hadoop/workers
9.4.11. 输入内容
hadoop102
hadoop103
hadoop104
9.4.12. 同步所有节点配置文件
xsync /usr/local/hadoop-3.1.3/etc
9.5. 配置启动参数
9.5.1. 编辑文件
vi /usr/local/hadoop-3.1.3/sbin/start-dfs.sh
9.5.2. 第二行输入内容
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
9.5.3. 编辑文件
vi /usr/local/hadoop-3.1.3/sbin/stop-dfs.sh
9.5.4. 第二行输入内容
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
9.5.5. 编辑文件
vi /usr/local/hadoop-3.1.3/sbin/start-yarn.sh
9.5.6. 第二行输入内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
9.5.7. 编辑文件
vi /usr/local/hadoop-3.1.3/sbin/stop-yarn.sh
9.5.8. 第二行输入内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
9.5.9. 分发修改文件
xsync /usr/local/hadoop-3.1.3/sbin
9.6. 初始化
9.6.1. 进入目录
cd /usr/local/hadoop-3.1.3/bin
9.6.2. 执行命令
./hdfs namenode -format
9.7. 启动集群
9.7.1. 进入目录
cd /usr/local/hadoop-3.1.3/sbin
9.7.2. 执行命令
./start-dfs.sh
./start-yarn.sh
9.8. 查看URL
9.8.1. 本机电脑找到 C:\Windows\System32\drivers\etc 修改hosts
192.168.11.50 hadoop102
192.168.11.79 hadoop103
192.168.11.141 hadoop104
9.8.2. 浏览器输入hadoop2:9870
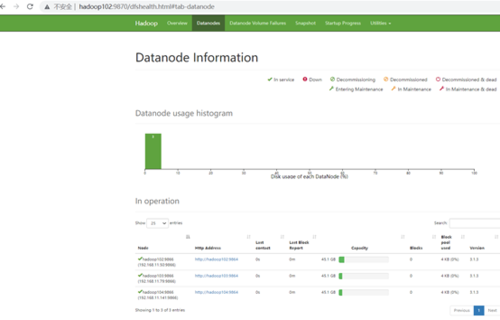
10. 部署Zookeeper(可选)
10.1. 部署Zookeeper
10.1.1. 解压到指定目录
tar -zxvf /usr/local/softs/zookeeper-3.4.5-cdh5.16.2.tar.gz -C /usr/local
10.1.2. 编辑环境变量
vi /etc/profile
10.1.3. 在“PATH=”上一行添加“export ZK_HOME= /usr/local/zookeeper-3.4.5-cdh5.16.2”
10.1.4. 在“PATH=”末尾添加“:${ZK_HOME}/bin”
export ZK_HOME=/usr/local/zookeeper-3.4.5-cdh5.16.2
export PATH=$PATH:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${MAVEN_HOME}/bin:${HADOOP_HOME}/bin:${ZK_HOME}/bin
10.1.5. 刷新环境变量
source /etc/profile
10.1.6. 进入目录
cd /usr/local/zookeeper-3.4.5-cdh5.16.2/conf
10.1.7. 复制文件
cp zoo_sample.cfg zoo.cfg
10.1.8. 编辑文件
vi zoo.cfg
10.1.9. 查找字符串“dataDir=/tmp/zookeeper”修改
dataDir=/usr/local/hadoop_app/tmp/zookeeper
10.1.10. 进入目录
cd /usr/local/zookeeper-3.4.5-cdh5.16.2/bin
10.1.11. 输入命令
./zkServer.sh start
11. 部署Flume(可选)
11.1. 部署Flume
11.1.1. 解压到指定目录
tar -zxvf /usr/local/softs/flume-ng-1.6.0-cdh5.14.2.tar.gz -C /usr/local
11.1.2. 编辑环境变量
vi /etc/profile
11.1.3. 在“PATH=”上一行添加
export FLUME_HOME=/usr/local/apache-flume-1.6.0-cdh5.14.2-bin
11.1.4. 在“PATH=”末尾添加“:${FLUME_HOME}/bin”
export FLUME_HOME=/usr/local/apache-flume-1.6.0-cdh5.14.2-bin
export PATH=$PATH:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${MAVEN_HOME}/bin:${HADOOP_HOME}/bin:${ZK_HOME}/bin:${FLUME_HOME}/bin
11.1.5. 刷新环境变量
source /etc/profile
11.1.6. 复制文件
cp /usr/local/apache-flume-1.6.0-cdh5.14.2-bin/conf/flume-env.sh.template /usr/local/apache-flume-1.6.0-cdh5.14.2-bin/conf/flume-env.sh
11.1.7. 编辑文件
vi /usr/local/apache-flume-1.6.0-cdh5.14.2-bin/conf/flume-env.sh
11.1.8. 查找字符串“export JAVA_HOME”在下方添加
export JAVA_HOME= /usr/java/jdk1.8.0_271
11.1.9. 进入文件夹
cd /usr/local/apache-flume-1.6.0-cdh5.14.2-bin/bin
11.1.10. 输入命令查看版本
./flume-ng version
12. 部署Kafka(可选)
12.1. 部署Kafka
12.1.1. 解压到指定目录
tar -zxvf /usr/local/softs/kafka_2.12-2.5.0.tgz -C /usr/local
12.1.2. 编辑环境变量
vi /etc/profile
12.1.3. 在“PATH=”上一行添加“export KAFKA_HOME=/usr/local/kafka_2.12-2.5.0”
12.1.4. 在“PATH=”末尾添加“:${KAFKA_HOME}/bin”
export KAFKA_HOME=/usr/local/kafka_2.12-2.5.0
export PATH=$PATH:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${MAVEN_HOME}/bin:${HADOOP_HOME}/bin:${ZK_HOME}/bin:${FLUME_HOME}/bin:${KAFKA_HOME}/bin
12.1.5. 刷新环境变量
source /etc/profile
12.1.6. 后台启动方式
/usr/local/kafka_2.12-2.5.0/bin/kafka-server-start.sh -daemon /usr/local/kafka_2.12-2.5.0/config/server.properties
13. 安装Spark
13.1. 编译Spark
13.1.1. 解压到指定目录
tar -zxvf /usr/local/softs/spark-3.0.3.tgz -C /usr/local
13.1.2. 进入目录
cd /usr/local/spark-3.0.3
13.1.3. 开始编译(“3.1.3”将合成到编译后的文件名里)
注意:第一次编译需要3个小时左右,可以直接使用本文编译好的包spark-3.0.3-bin-3.1.3.tgz
./dev/make-distribution.sh \
--name 3.1.3 \
--tgz -Phive -Phive-thriftserver \
-Pyarn
13.2. 解压Spark
13.2.1. 解压
tar -zxvf /usr/local/softs/spark-3.0.3-bin-3.1.3.tgz -C /usr/local
13.2.2. 编辑环境变量
vi /etc/profile
13.2.3. 在“PATH=”上一行添加
export SPARK_HOME=/usr/local/spark-3.0.3-bin-3.1.3
13.2.4. 在“PATH=”末尾添加“:${SPARK_HOME}/bin”
export SPARK_HOME=/usr/local/spark-3.0.3-bin-3.1.3
export PATH=$PATH:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${MAVEN_HOME}/bin:${HADOOP_HOME}/bin:${ZK_HOME}/bin:${FLUME_HOME}/bin:${KAFKA_HOME}/bin:${SPARK_HOME}/bin
13.2.5. 刷新环境变量
source /etc/profile
export HADOOP_CONF_DIR=/usr/local/hadoop-3.1.3/etc/hadoop
13.2.6. 执行命令
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
/usr/local/spark-3.0.3-bin-3.1.3/examples/jars/spark-examples*.jar \
2
13.3. 安装nc
yum install -y nc
14. 部署Spark集群
14.1. 重复步骤
14.1.1. 执行13.2.1到13.2.5(安装spark 到 刷新环境变量)
14.2. 环境配置文件
14.2.1. 复制并重命名环境配置文件
cp /usr/local/spark-3.0.3-bin-3.1.3/conf/spark-env.sh.template /usr/local/spark-3.0.3-bin-3.1.3/conf/spark-env.sh
14.2.2. 编辑配置文件
vi /usr/local/spark-3.0.3-bin-3.1.3/conf/spark-env.sh
14.2.3. 文件末尾添加内容
# 指定 Java Home(根据自己机器的路径修改)
export JAVA_HOME=/usr/java/jdk1.8.0_211
# 指定 Spark Master 地址
export SPARK_MASTER_HOST=hadoop102
export SPARK_MASTER_PORT=7077
14.2.4. 复制并重命名环境配置文件
cp /usr/local/spark-3.0.3-bin-3.1.3/conf/slaves.template /usr/local/spark-3.0.3-bin-3.1.3/conf/slaves
14.2.5. 编辑配置文件
vi /usr/local/spark-3.0.3-bin-3.1.3/conf/slaves
14.2.6. 将localhost替换为下面的别称
hadoop102
hadoop103
hadoop104
14.3. 分发文件
14.3.1. 分发Spark
xsync /usr/local/spark-3.0.3-bin-3.1.3
14.4. 启动集群
14.4.1. 进入目录
cd /usr/local/spark-3.0.3-bin-3.1.3/sbin
14.4.2. 启动命令
./start-all.sh
注:出现Permission denied, please try again.请重新执行“9.2设置免密登录”
14.4.3. 执行测试命令
cd /usr/local/spark-3.0.3-bin-3.1.3/
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077,hadoop103:7077,hadoop104:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/usr/local/spark-3.0.3-bin-3.1.3/examples/jars/spark-examples_2.12-3.0.3.jar \
100
14.5. 查看结果
14.5.1. 浏览器查看
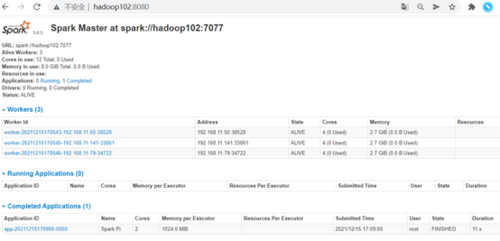
共同学习,写下你的评论
评论加载中...
作者其他优质文章



