
从 0 到 1,打造新一代开源函数计算平台
本文是根据霍秉杰在 2021 稀土开发者大会分享的内容整理而来。
作者:霍秉杰,云原生 FaaS 项目 OpenFunction Founder; FluentBit Operator 的发起人;他还是几个可观测性开源项目的发起人,如 Kube-Events、Notification Manager 等;热爱云原生和开源技术,是 Prometheus Operator, Thanos, Loki, Falco 的贡献者。
无服务器计算,即通常所说的 Serverless,已经成为当前云原生领域炙手可热的名词,是继 IaaS,PaaS 之后云计算发展的下一波浪潮。Serverless 强调的是一种架构思想和服务模型,让开发者无需关心基础设施(服务器等),而是专注到应用程序业务逻辑上。加州大学伯克利分校在论文 A Berkeley View on Serverless Computing 中给出了两个关于 Serverless 的核心观点:
- 有服务的计算并不会消失,但随着 Serverless 的成熟,有服务计算的重要性会逐渐降低。
- Serverless 最终会成为云时代的计算范式,它能够在很大程度上替代有服务的计算模式,并给 Client-Server 时代划上句号。
那么什么是 Serverless 呢?
Serverless 介绍
关于什么是 Serverless,加州大学伯克利分校在之前提到的论文中也给出了明确定义:Serverless computing = FaaS + BaaS。云服务按抽象程度从底层到上层传统的分类是硬件、云平台基本组件、PaaS、应用,但 PaaS 层的理想状态是具备 Serverless 的能力,因此这里我们将 PaaS 层替换成了 Serverless,即下图中的黄色部分。
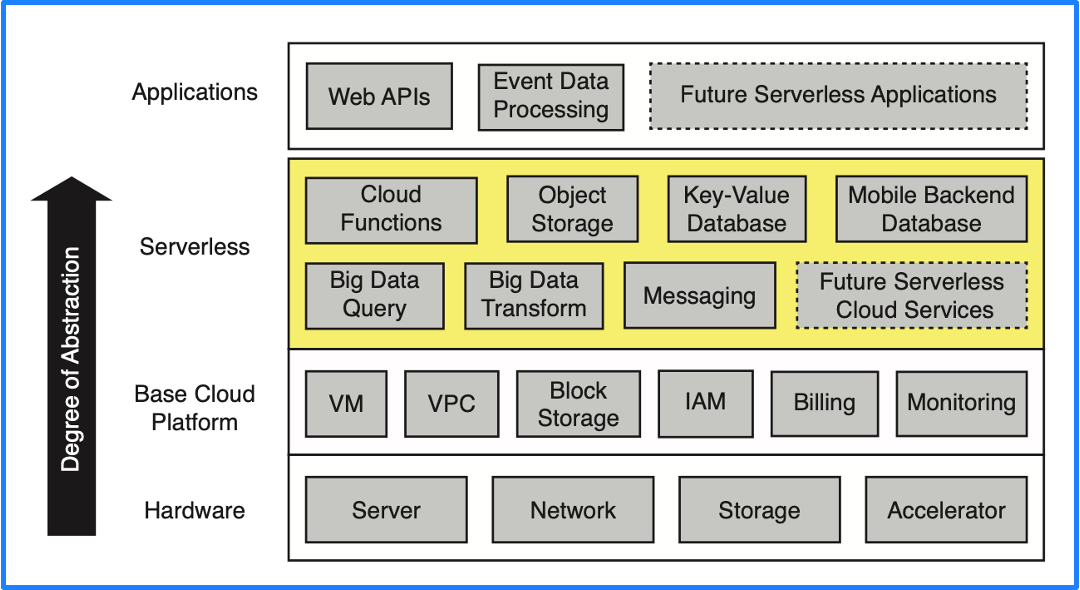
Serverless 包含两个组成部分 BaaS 和 FaaS,其中对象存储、关系型数据库以及 MQ 等云上基础支撑服务属于 BaaS(后端即服务),这些都是每个云都必备的基础服务,FaaS(函数即服务)才是 Serverless 的核心。
现有开源 Serverless 平台分析
KubeSphere 社区从 2020 年下半年开始对 Serverless 领域进行深度调研。经过一段时间的调研后,我们发现:
- 现有开源 FaaS 项目绝大多数启动较早,大部分都在 Knative 出现前就已经存在了;
- Knative 是一个非常杰出的 Serverless 平台,但是 Knative Serving 仅仅能运行应用,不能运行函数,还不能称之为 FaaS 平台;
- Knative Eventing 也是非常优秀的事件管理框架,但是设计有些过于复杂,用户用起来有一定门槛;
- OpenFaaS 是比较流行的 FaaS 项目,但是技术栈有点老旧,依赖于 Prometheus 和 Alertmanager 进行 Autoscaling,在云原生领域并非最专业和敏捷的做法;
- 近年来云原生 Serverless 相关领域陆续涌现出了很多优秀的开源项目如 KEDA、 Dapr、 Cloud Native Buildpacks(CNB)、 Tekton、 Shipwright 等,为创建新一代开源 FaaS 平台打下了基础。
综上所述,我们调研的结论就是:现有开源 Serverless 或 FaaS 平台并不能满足构建现代云原生 FaaS 平台的要求,而云原生 Serverless 领域的最新进展却为构建新一代 FaaS 平台提供了可能。
新一代 FaaS 平台框架设计
如果我们要重新设计一个更加现代的 FaaS 平台,它的架构应该是什么样子呢?理想中的 FaaS 框架应该按照函数生命周期分成几个重要的部分:函数框架 (Functions framework)、函数构建 (Build)、函数服务 (Serving) 和事件驱动框架 (Events Framework)。
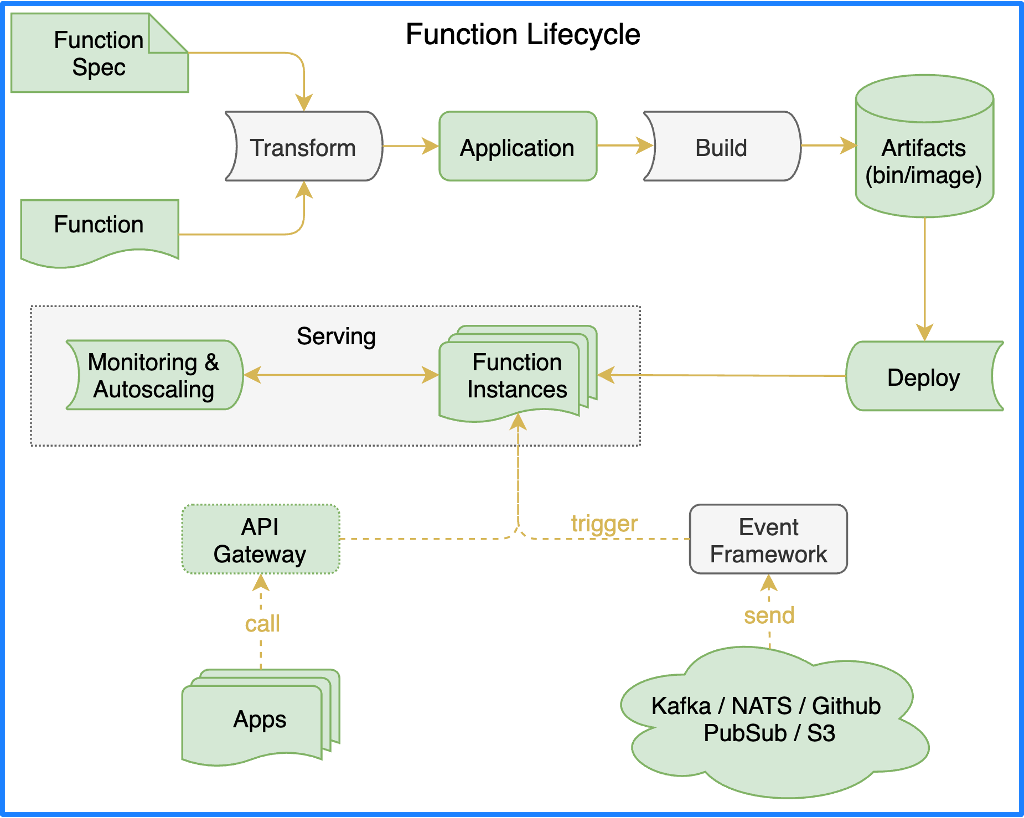
作为 FaaS,首先得有一个 Function Spec 来定义函数该怎么写,有了函数之后,还要转换成应用,这个转换的过程就是靠函数框架来完成;如果应用想在云原生环境中运行,就得构建容器镜像,构建流程依赖函数构建来完成;构建完镜像后,应用就可以部署到函数服务的运行时中;部署到运行时之后,这个函数就可以被外界访问了。
下面我们将重点阐述函数框架、函数构建和函数服务这几个部分的架构设计。
函数框架 (Functions framework)
为了降低开发过程中学习函数规范的成本,我们需要增加一种机制来实现从函数代码到可运行的应用之间的转换。这个机制需要制作一个通用的 main 函数来实现,这个函数用于处理通过 serving url 函数进来的请求。主函数中具体包含了很多步骤,其中一个步骤用于关联用户提交的代码,其余的用于做一些普通的工作(如处理上下文、处理事件源、处理异常、处理端口等等)。
在函数构建的过程中,构建器会使用主函数模板渲染用户代码,在此基础上生成应用容器镜像中的 main 函数。我们直接来看个例子,假设有这样一个函数。
package hello
import (
"fmt"
"net/http"
)
func HelloWorld(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, "Hello, World!\n")
}
经函数框架转换后会生成如下的应用代码:
package main
import (
"context"
"errors"
"fmt"
"github.com/OpenFunction/functions-framework-go/functionframeworks"
ofctx "github.com/OpenFunction/functions-framework-go/openfunction-context"
cloudevents "github.com/cloudevents/sdk-go/v2"
"log"
"main.go/userfunction"
"net/http"
)
func register(fn interface{}) error {
ctx := context.Background()
if fnHTTP, ok := fn.(func(http.ResponseWriter, *http.Request)); ok {
if err := functionframeworks.RegisterHTTPFunction(ctx, fnHTTP); err != nil {
return fmt.Errorf("Function failed to register: %v\n", err)
}
} else if fnCloudEvent, ok := fn.(func(context.Context, cloudevents.Event) error); ok {
if err := functionframeworks.RegisterCloudEventFunction(ctx, fnCloudEvent); err != nil {
return fmt.Errorf("Function failed to register: %v\n", err)
}
} else if fnOpenFunction, ok := fn.(func(*ofctx.OpenFunctionContext, []byte) ofctx.RetValue); ok {
if err := functionframeworks.RegisterOpenFunction(ctx, fnOpenFunction); err != nil {
return fmt.Errorf("Function failed to register: %v\n", err)
}
} else {
err := errors.New("unrecognized function")
return fmt.Errorf("Function failed to register: %v\n", err)
}
return nil
}
func main() {
if err := register(userfunction.HelloWorld); err != nil {
log.Fatalf("Failed to register: %v\n", err)
}
if err := functionframeworks.Start(); err != nil {
log.Fatalf("Failed to start: %v\n", err)
}
}
其中高亮的部分就是前面用户自己写的函数。在启动应用之前,先对该函数进行注册,可以注册 HTTP 类的函数,也可以注册 cloudevents 和 OpenFunction 函数。注册完成后,就会调用 functionframeworks.Start 启动应用。
函数构建 (Build)
有了应用之后,我们还要把应用构建成容器镜像。目前 Kubernetes 已经废弃了 dockershim,不再把 Docker 作为默认的容器运行时,这样就无法在 Kubernetes 集群中以 Docker in Docker 的方式构建容器镜像。还有没有其他方式来构建镜像?如何管理构建流水线?
Tekton 是一个优秀的流水线工具,原来是 Knative 的一个子项目,后来捐给了 CD 基金会 (Continuous Delivery Foundation)。Tekton 的流水线逻辑其实很简单,可以分为三个步骤:获取代码,构建镜像,推送镜像。每一个步骤在 Tekton 中都是一个 Task,所有的 Task 串联成一个流水线。
作容器镜像有多种选择,比如 Kaniko、Buildah、BuildKit 以及 Cloud Native Buildpacks(CNB)。其中前三者均依赖 Dockerfile 去制作容器镜像,而 Cloud Native Buildpacks(CNB)是云原生领域最新涌现出来的新技术,它是由 Pivotal 和 Heroku 发起的,不依赖于 Dockerfile,而是能自动检测要 build 的代码,并生成符合 OCI 标准的容器镜像。这是一个非常惊艳的技术,目前已经被 Google Cloud、IBM Cloud、Heroku、Pivotal 等公司采用,比如 Google Cloud 上面的很多镜像都是通过 Cloud Native Buildpacks(CNB)构建出来的。
面对这么多可供选择的镜像构建工具,如何在函数构建的过程中让用户自由选择和切换镜像构建的工具?这就需要用到另外一个项目 Shipwright,这是由 Red Hat 和 IBM 开源的项目,专门用来在 Kubernetes 集群中构建容器镜像,目前也捐给了 CD 基金会。使用 Shipwright,你就可以在上述四种镜像构建工具之间进行灵活切换,因为它提供了一个统一的 API 接口,将不同的构建方法都封装在这个 API 接口中。
我们可以通过一个示例来理解 Shipwright 的工作原理。首先需要一个自定义资源 Build 的配置清单:
apiVersion: shipwright.io/v1alpha1
kind: Build
metadata:
name: buildpack-nodejs-build
spec:
source:
url: https://github.com/shipwright-io/sample-nodejs
contextDir: source-build
strategy:
name: buildpacks-v3
kind: ClusterBuildStrategy
output:
image: docker.io/${REGISTRY_ORG}/sample-nodejs:latest
credentials:
name: push-secret
这个配置清单分为 3 个部分:
- source 表示去哪获取源代码;
- output 表示源代码构建的镜像要推送到哪个镜像仓库;
- strategy 指定了构建镜像的工具。
其中 strategy 是由自定义资源 ClusterBuildStrategy 来配置的,比如使用 buildpacks 来构建镜像,ClusterBuildStrategy 的内容如下:
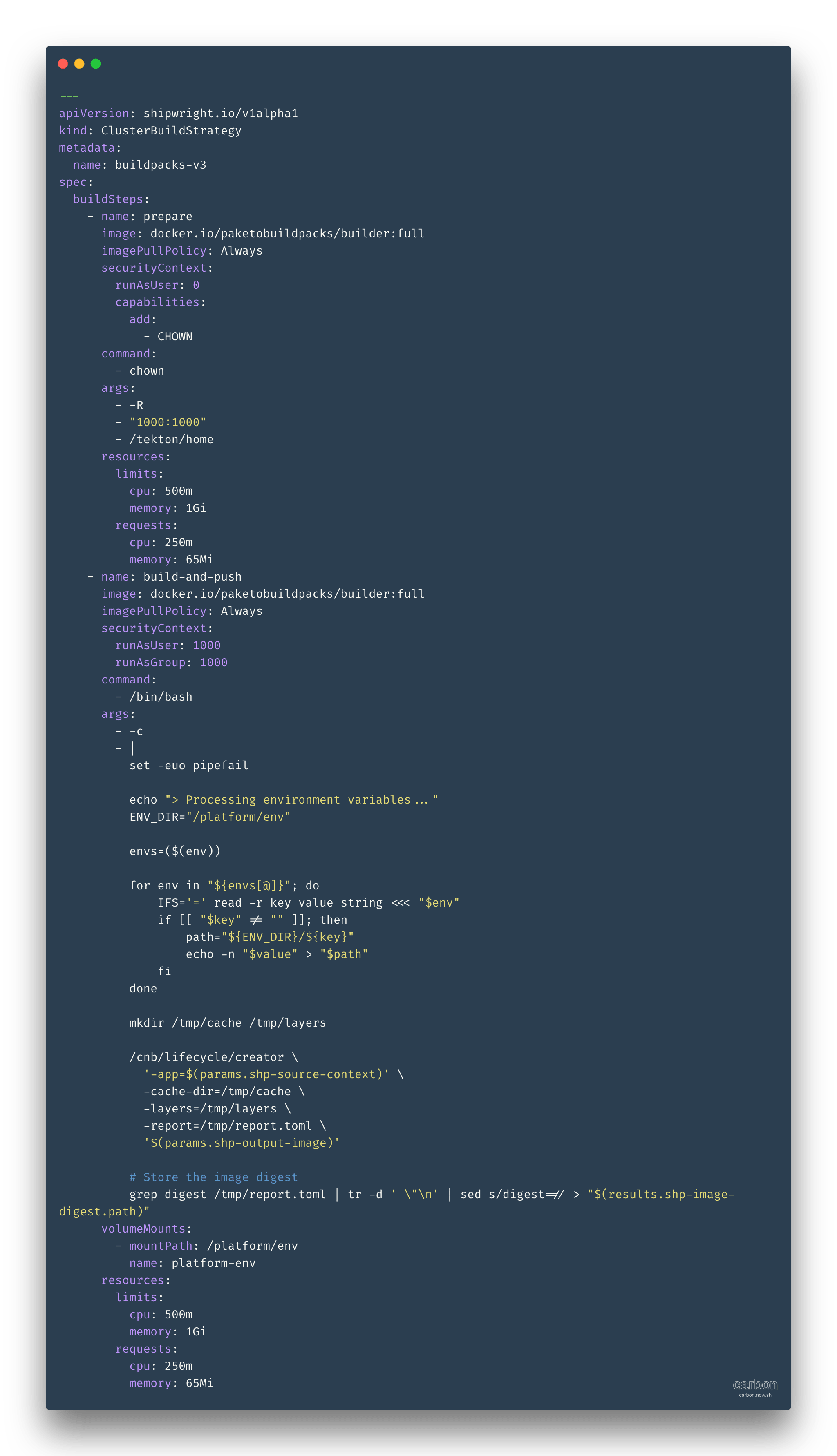
这里分为两个步骤,一个是准备环境,一个是构建并推送镜像。每一步都是 Tekton 的一个 Task,由 Tekton 流水线来管理。
可以看到,Shipwright 的意义在于将镜像构建的能力进行了抽象,用户可以使用统一的 API 来构建镜像,通过编写不同的 strategy 就可以切换不同的镜像构建工具。
函数服务 (Serving)
函数服务 (Serving) 指的是如何运行函数/应用,以及赋予函数/应用基于事件驱动或流量驱动的自动伸缩的能力 (Autoscaling)。CNCF Serverless 白皮书定义了函数服务的四种调用类型:
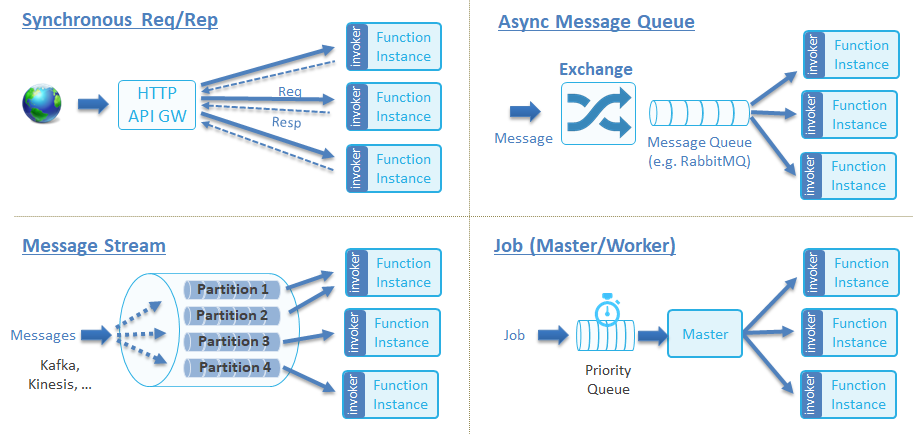
我们可以对其进行精简一下,主要分为两种类型:
- 同步函数:客户端必须发起一个 HTTP 请求,然后必须等到函数执行完成并获取函数运行结果后才返回。
- 异步函数:发起请求之后直接返回,无需等待函数运行结束,具体的结果通过 Callback 或者 MQ 通知等事件来通知调用者,即事件驱动 (Event Driven)。
同步函数和异步函数分别都有不同的运行时来实现:
- 同步函数方面,Knative Serving 是一个非常优秀的同步函数运行时,具备了强大的自动伸缩能力。除了 Knative Serving 之外,还可以选择基于 KEDA http-add-on 配合 Kubernetes 原生的 Deployment 来实现同步函数运行时。这种组合方法可以摆脱对 Knative Serving 依赖。
- 异步函数方面,可以结合 KEDA 和 Dapr 来实现。KEDA 可以根据事件源的监控指标来自动伸缩 Deployment 的副本数量;Dapr 提供了函数访问 MQ 等中间件的能力。
Knative 和 KEDA 在自动伸缩方面的能力不尽相同,下面我们将展开分析。
Knative 自动伸缩
Knative Serving 有 3 个主要组件:Autoscaler、Serverless 和 Activator。Autoscaler 会获取工作负载的 Metric(比如并发量),如果现在的并发量是 0,就会将 Deployment 的副本数收缩为 0。但副本数缩为 0 之后函数就无法调用了,所以 Knative 在副本数缩为 0 之前会把函数的调用入口指向 Activator。
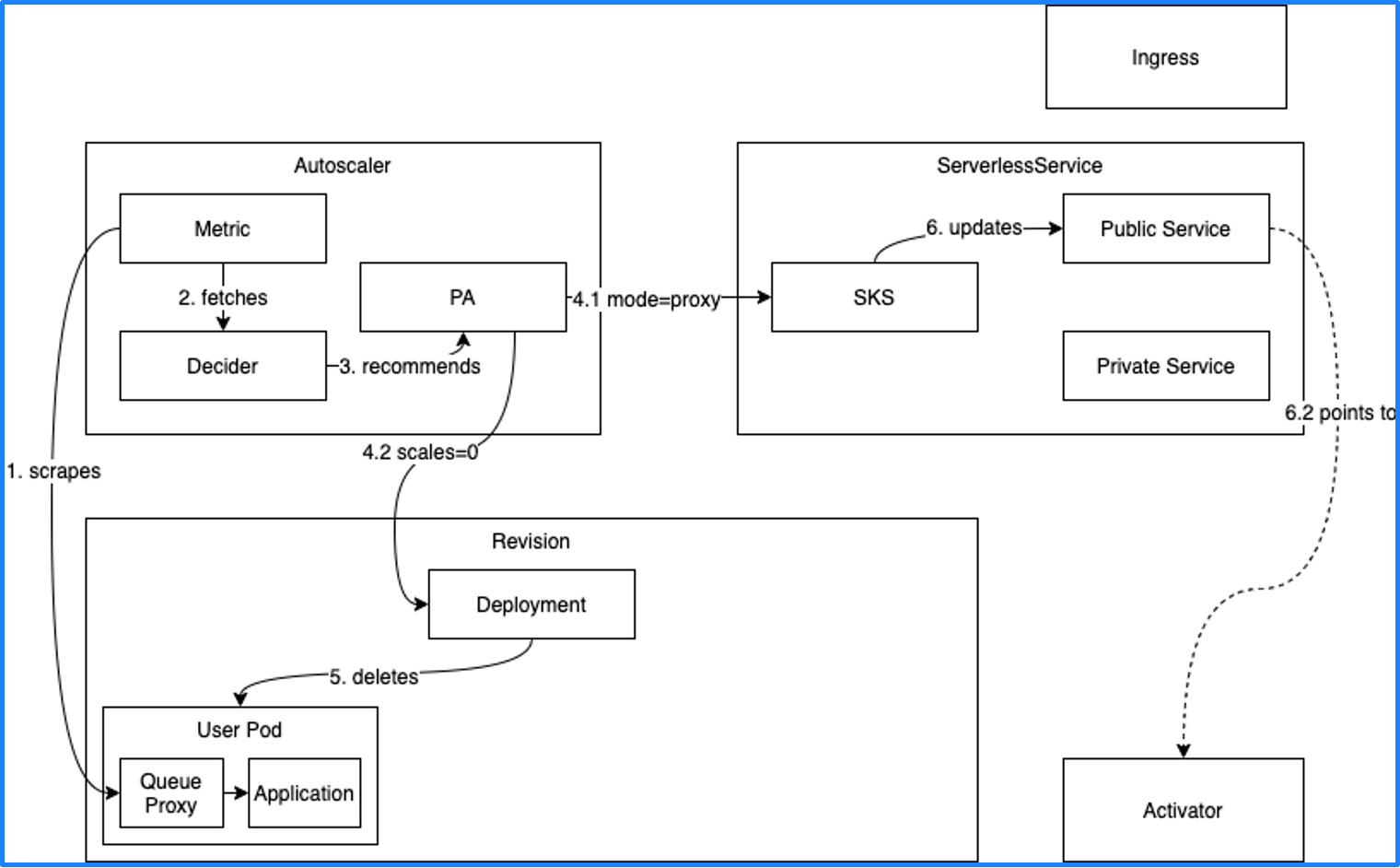
当有新的流量进入时,会先进入 Activator,Activator 接收到流量后会通知 Autoscaler,然后 Autoscaler 将 Deployment 的副本数扩展到 1,最后 Activator 会将流量转发到实际的 Pod 中,从而实现服务调用。这个过程也叫冷启动。
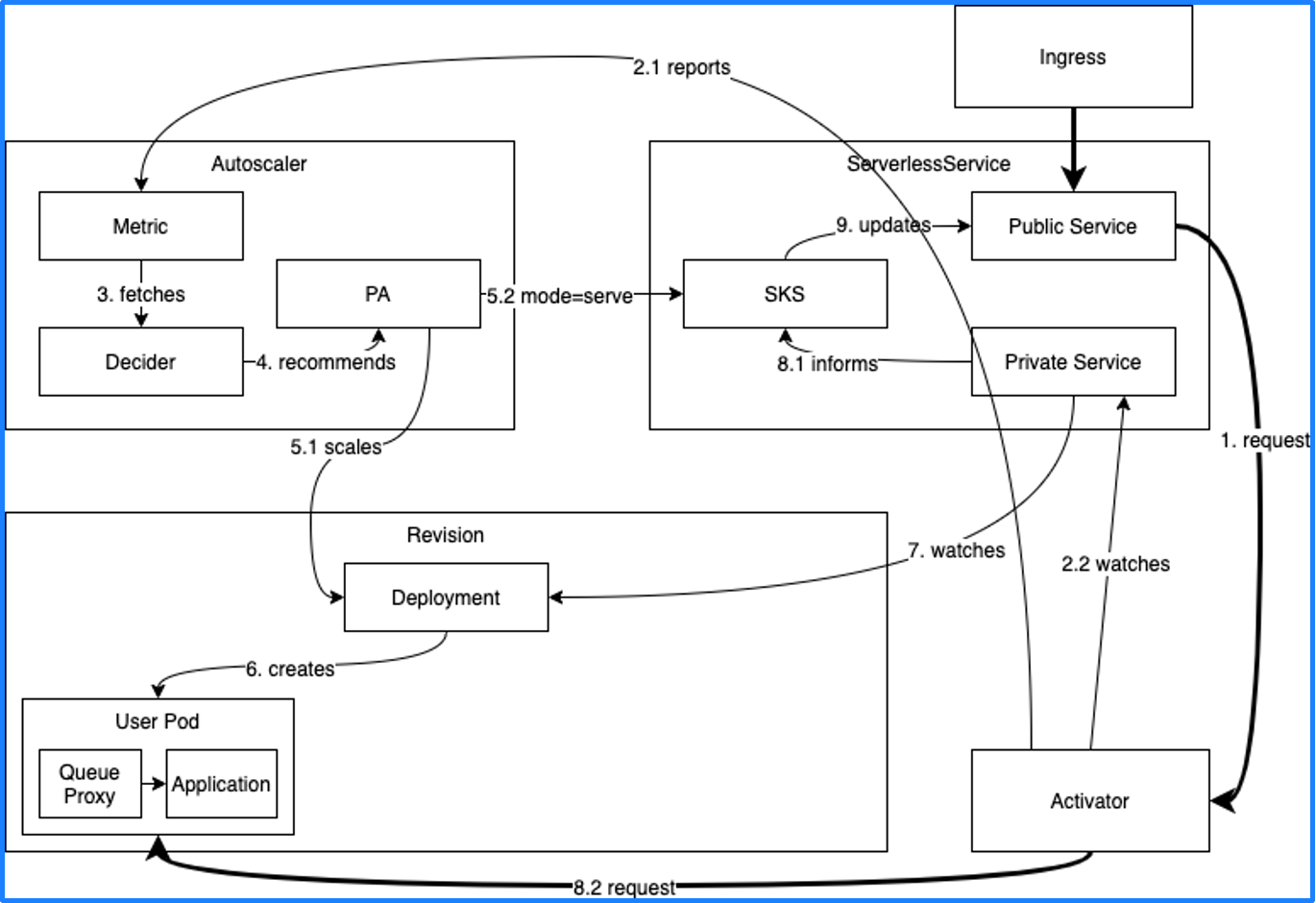
由此可知,Knative 只能依赖 Restful HTTP 的流量指标进行自动伸缩,但现实场景中还有很多其他指标可以作为自动伸缩的依据,比如 Kafka 消费的消息积压,如果消息积压数量过多,就需要更多的副本来处理消息。要想根据更多类型的指标来自动伸缩,我们可以通过 KEDA 来实现。
KEDA 自动伸缩
KEDA 需要和 Kubernetes 的 HPA 相互配合来达到更高级的自动伸缩的能力,HPA 只能实现从 1 到 N 之间的自动伸缩,而 KEDA 可以实现从 0 到 1 之间的自动伸缩,将 KEDA 和 HPA 结合就可以实现从 0 到 N 的自动伸缩。
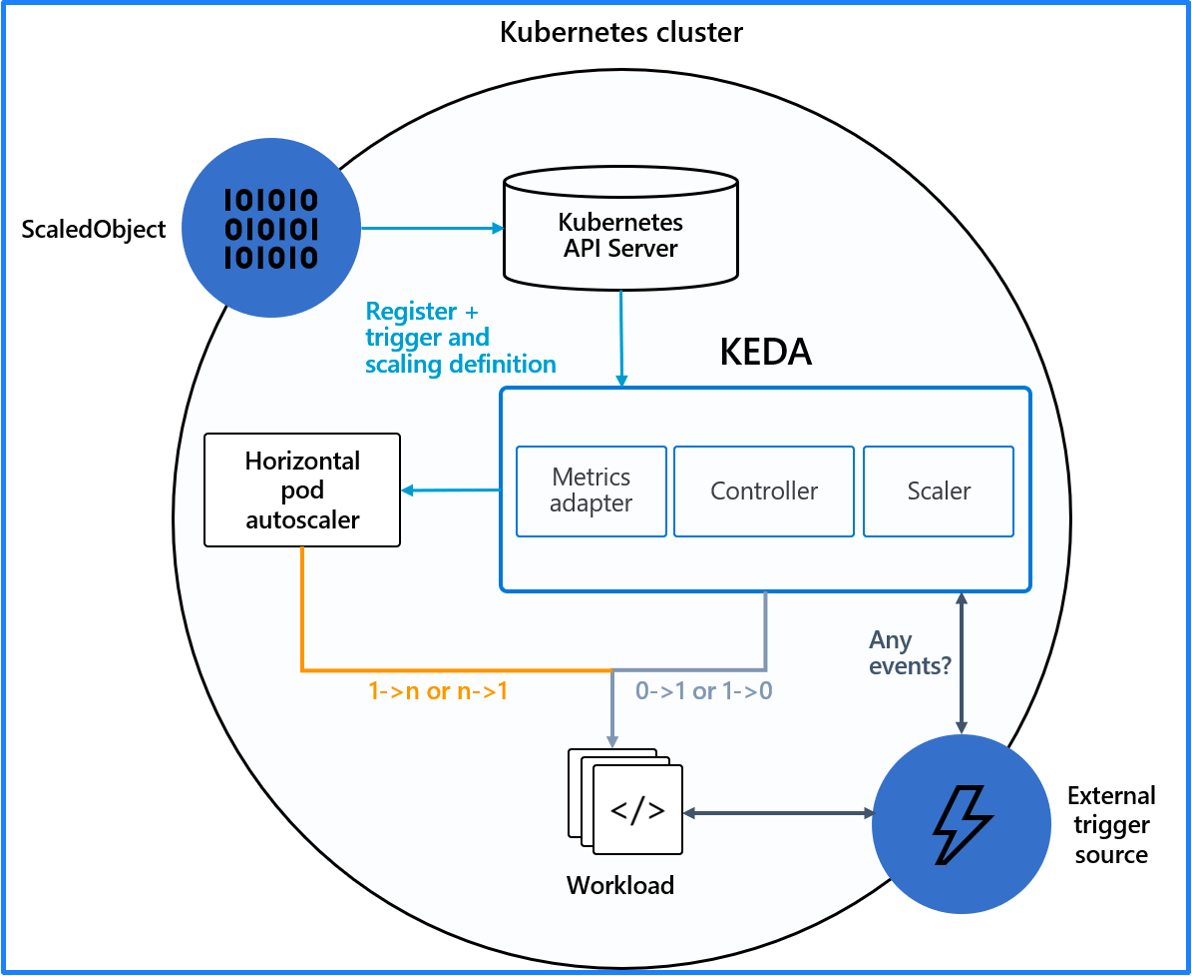
KEDA 可以根据很多类型的指标来进行自动伸缩,这些指标可以分为这么几类:
- 云服务的基础指标,比如 AWS 和 Azure 的相关指标;
- Linux 系统相关指标,比如 CPU、内存;
- 开源组件特定协议的指标,比如 Kafka、MySQL、Redis、Prometheus。

例如要根据 Kafka 的指标进行自动伸缩,就需要这样一个配置清单:
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: kafka-scaledobject
namespace: default
labels:
deploymentName: kafka-consumer-deployment # Required Name of the deployment we want to scale.
spec:
scaleTargetRef:
deploymentName: kafka-consumer-deployment # Required Name of the deployment we want to scale.
pollingInterval: 15
minReplicaCount: 0
maxReplicaCount: 10
cooldownPeriod: 30
triggers:
- type: kafka
metadata:
topic: logs
bootstrapServers: kafka-logs-receiver-kafka-brokers.default.svc.cluster.local
consumerGroup: log-handler
lagThreshold: "10"
副本伸缩的范围在 0~10 之间,每 15 秒检查一次 Metrics,进行一次扩容之后需要等待 30 秒再决定是否进行伸缩。
同时还定义了一个触发器,即 Kafka 服务器的 “logs” topic。消息堆积阈值为 10,即当消息数量超过 10 时,logs-handler 的实例数量就会增加。如果没有消息堆积,就会将实例数量减为 0。
这种基于组件特有协议的指标进行自动伸缩的方式比基于 HTTP 的流量指标进行伸缩的方式更加合理,也更加灵活。
虽然 KEDA 不支持基于 HTTP 流量指标进行自动伸缩,但可以借助 KEDA 的 http-add-on 来实现,该插件目前还是 Beta 状态,我们会持续关注该项目,等到它足够成熟之后就可以作为同步函数的运行时来替代 Knative Serving。
Dapr
现在的应用基本上都是分布式的,每个应用的能力都不尽相同,为了将不同应用的通用能力给抽象出来,微软开发了一个分布式应用运行时,即 Dapr (Distributed Application Runtime)。Dapr 将应用的通用能力抽象成了组件,不同的组件负责不同的功能,例如服务之间的调用、状态管理、针对输入输出的资源绑定、可观测性等等。这些分布式组件都使用同一种 API 暴露给各个编程语言进行调用。
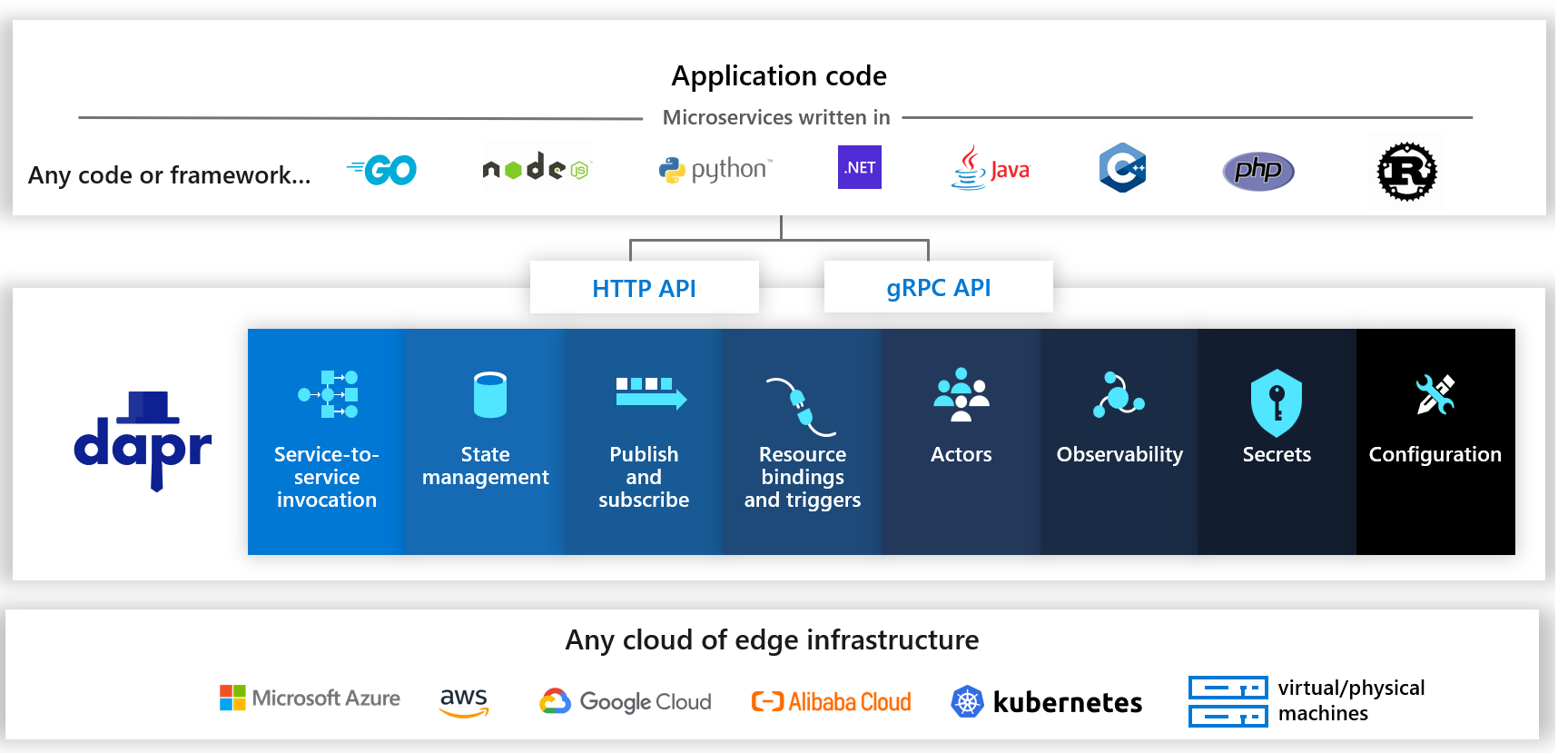
函数计算也是分布式应用的一种,会用到各种各样的编程语言,以 Kafka 为例,如果函数想要和 Kafka 通信,Go 语言就得使用 Go SDK,Java 语言得用 Java SDK,等等。你用几种语言去访问 Kafka,就得写几种不同的实现,非常麻烦。
再假设除了 Kafka 之外还要访问很多不同的 MQ 组件,那就会更麻烦,用 5 种语言对接 10 个 MQ(Message Queue) 就需要 50 种实现。使用了 Dapr 之后,10 个 MQ 会被抽象成一种方式,即 HTTP/GRPC 对接,这样就只需 5 种实现,大大减轻了开发分布式应用的工作量。
由此可见,Dapr 非常适合应用于函数计算平台。
新一代开源函数计算平台 OpenFunction
结合上面讨论的所有技术,就诞生了 OpenFunction 这样一个开源项目,它的架构如图所示。
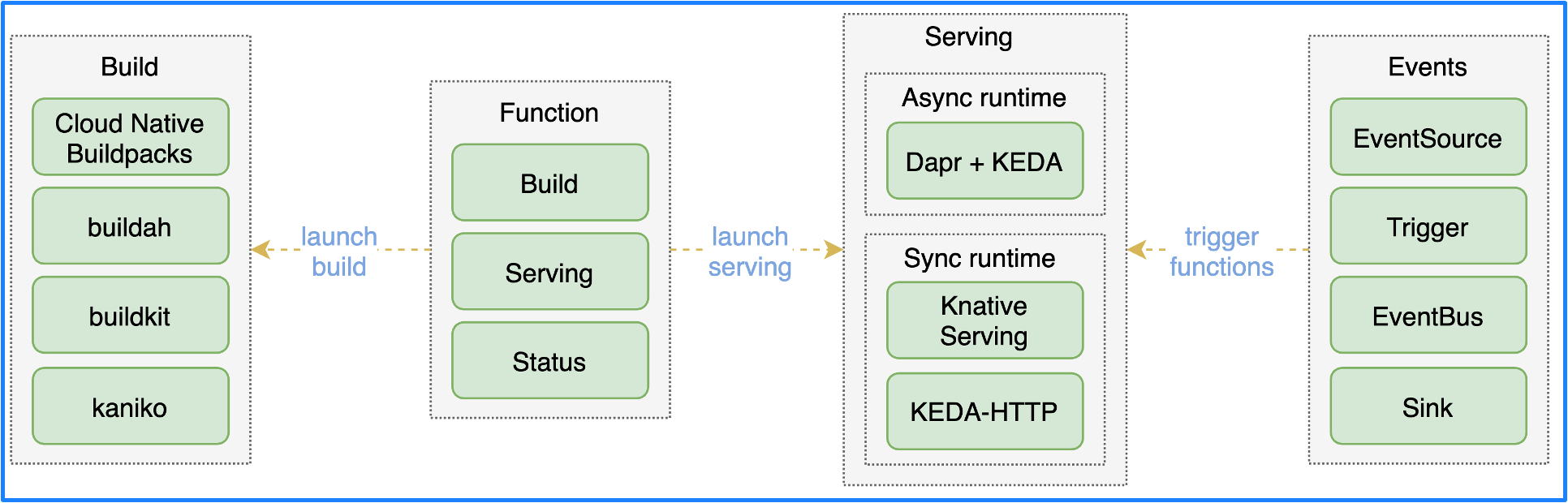
主要包含 4 个组件:
-
Function : 将函数转换为应用;
-
Build : 通过 Shipwright 选择不同的镜像构建工具,最终将应用构建为容器镜像;
-
Serving : 通过 Serving CRD 将应用部署到不同的运行时中,可以选择同步运行时或异步运行时。同步运行时可以通过 Knative Serving 或者 KEDA-HTTP 来支持,异步运行时通过 Dapr+KEDA 来支持。
-
Events : 对于事件驱动型函数来说,需要提供事件管理的能力。由于 Knative 事件管理过于复杂,所以我们研发了一个新型事件管理驱动叫 OpenFunction Events。

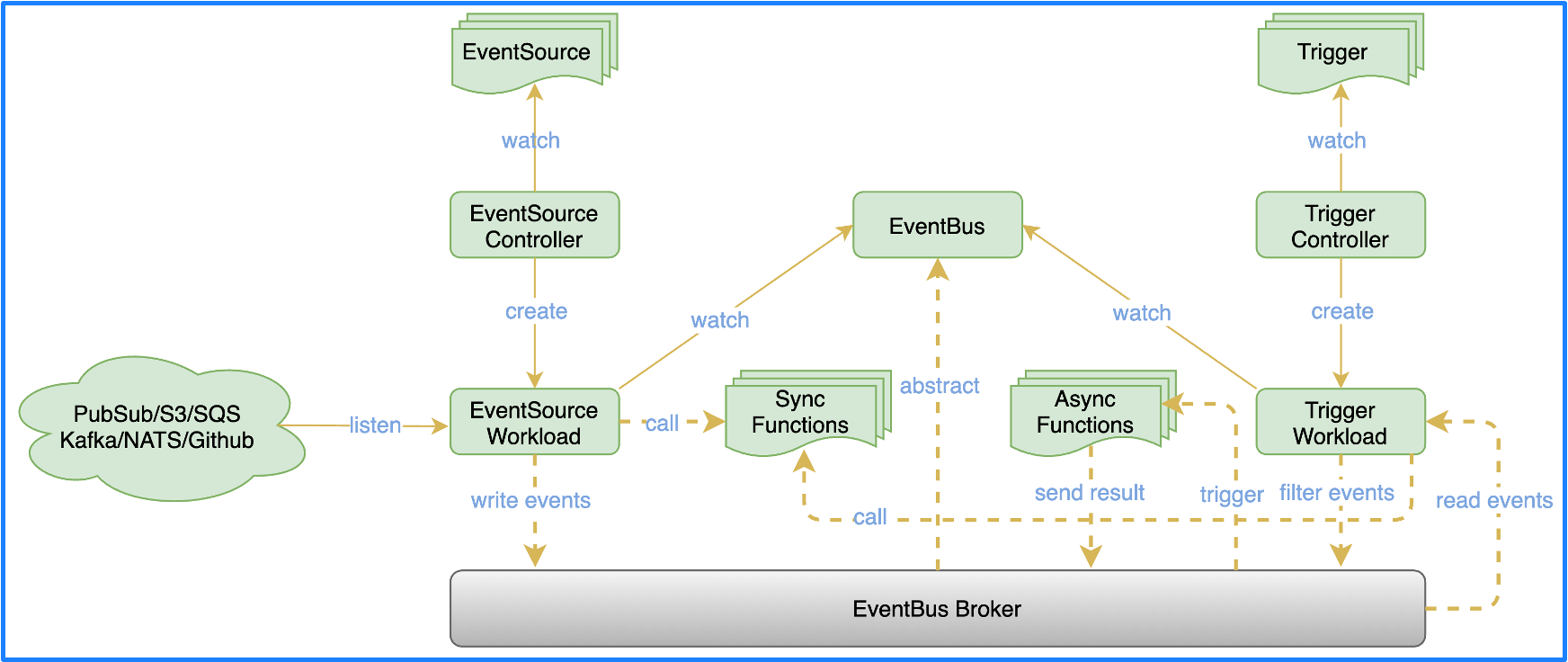
OpenFunction Events 借鉴了 Argo Events 的部分设计,并引入了 Dapr。整体架构分为 3 个部分:
- EventSource : 用于对接多种多样的事件源,通过异步函数来实现,可以根据事件源的指标自动伸缩,使事件的消费更加具有弹性。
- EventBus :
EventBus利用 Dapr 的能力解耦了 EventBus 与底层具体 Message Broker 的绑定,你可以对接各种各样的 MQ。EventSource消费事件之后有两种处理方式,一种是直接调用同步函数,然后等待同步函数返回结果;另一种方式是将其写入EventBus,EventBus 接收到事件后会直接触发一个异步函数。 - Trigger : Trigger 会通过各种表达式对
EventBus里面的各种事件进行筛选,筛选完成后会写入EventBus,触发另外一个异步函数。
关于 OpenFunction 的实际使用案例可以参考这篇文章:以 Serverless 的方式用 OpenFunction 异步函数实现日志告警(点击下方图片跳转阅读)。
OpenFunction Roadmap
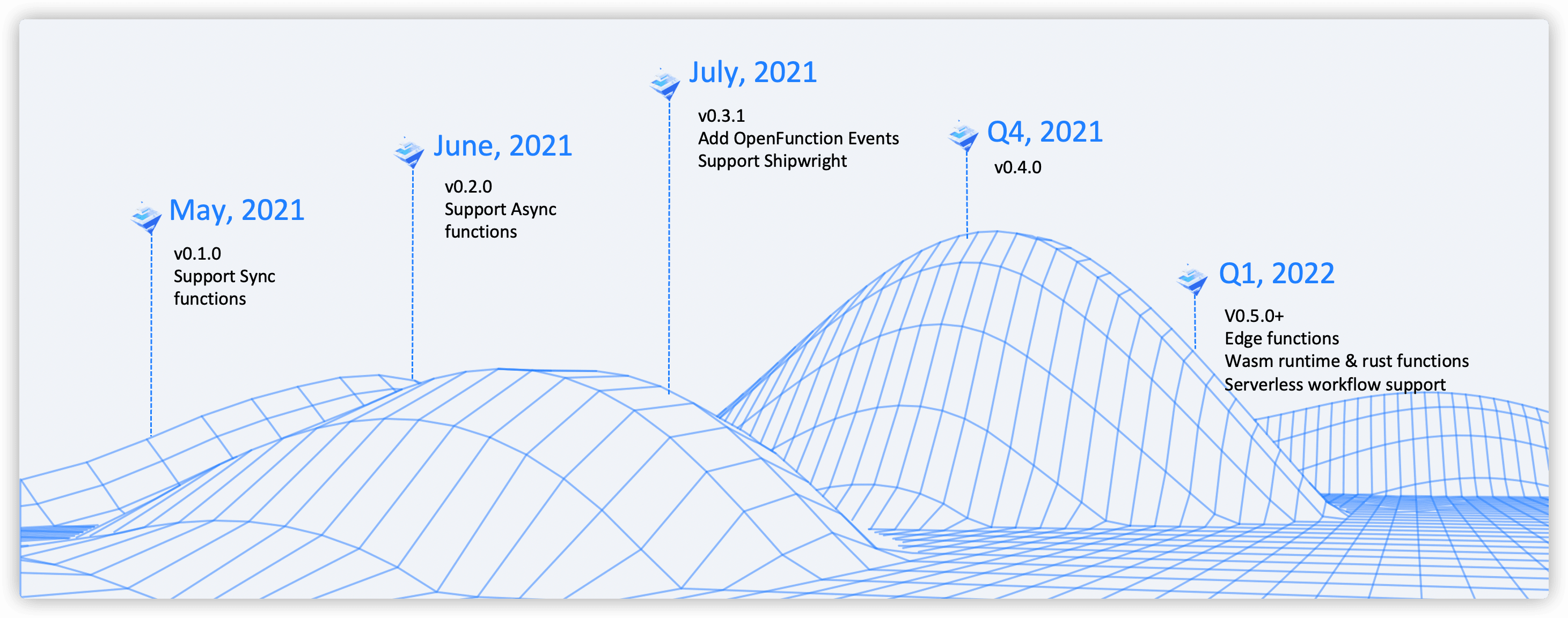
OpenFunction 的第一个版本于今年 5 月份发布,从 v0.2.0 开始支持异步函数,v0.3.1 开始新增了 OpenFunction Events,并支持了 Shipwright,v0.4.0 新增了 CLI。
后续我们还会引入可视化界面,支持更多的 EventSource,支持对边缘负载的处理能力,通过 WebAssembly 作为更加轻量的运行时,结合 Rust 函数来加速冷启动速度。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



