
Databend 是一个开源的、完全面向云架构的新式数仓,它提供快速的弹性扩展能力,并结合云的弹性、简单性和低成本,使 Data Cloud 构建变得更加容易。
Databend 把数据存储在像 AWS S3 ,Azure Blob 这些云上的存储系统,可以使不同的计算节点挂载同一份数据,从而做到较高的弹性,实现对资源的精细化控制。
Databend 在设计上专注以下能力:
- 弹性 在 Databend 中,存储和计算资源可以按需、按量弹性扩展。
- 安全 Databend 中数据文件和网络传输都是端到端加密,并在 SQL 级别提供基于角色的权限控制。
- 易用 Databend 兼容 ANSI SQL,并可以使用 MySQL 和 ClickHouse 客户端接入,几乎无学习成本。
- 成本 Databend 处理查询非常高效,用户只需要为使用的资源付费。
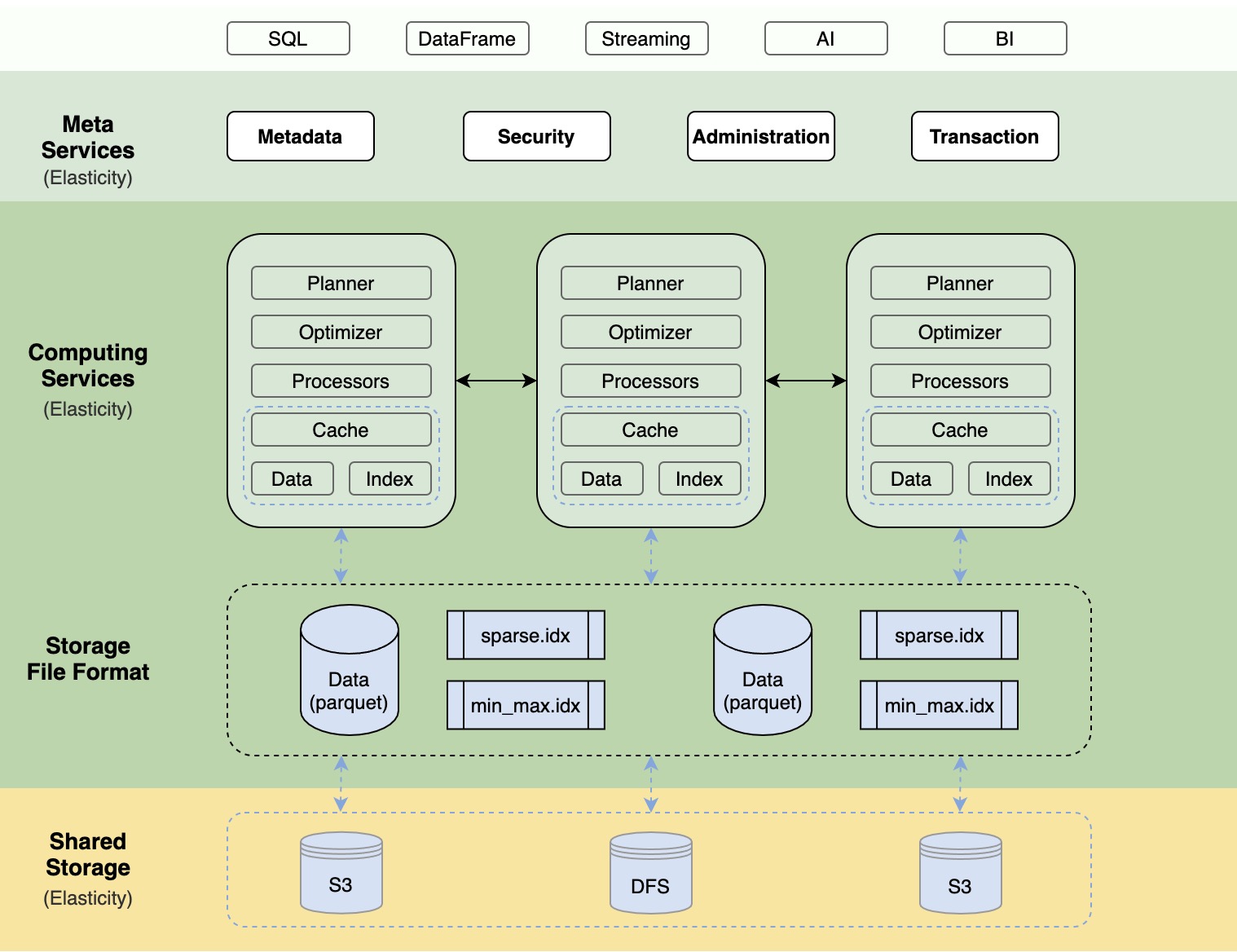
上图是 Databend 的整体架构图,整个系统主要由三大部分组成:Meta service layer、Compute Layer 和 Storage Layer。
1、Meta Service Layer
- Meta Service 是一个多租户、高可用的分布式 key-value 存储服务,具备事务能力,主要用于存储:
- Metadata : 表的元信息、索引信息、集群信息、事务信息等。
- Administration:用户系统、用户权限等信息。
- Security :用户登录认证、数据加密等。
2、Compute Layer
计算层由多个集群(cluster)组成,不同集群可以承担不同的工作负载,每个集群又有多个计算节点(node)组成,你可以轻松的添加、删除节点或集群,做到资源的按需、按量管理。
计算节点是计算层的最小构成单元,其中每个计算节点包含以下几个组件:
执行计划 (Planner)
根据用户输入的 SQL 生成执行计划,它只是个逻辑表达,并不能真正的执行,而是用于指导整个计算流水线(Pipeline)的编排与生成。
比如语句
SELECT number + 1 FROM numbers_mt(10) WHERE number > 8 LIMIT 2
执行计划:
databend :) EXPLAIN SELECT number + 1 FROM numbers_mt(10) WHERE number > 8 LIMIT 2
┌─explain────────────────────────────────────────────────────────────────────────────────────────────┐
│ Limit: 2 │
│ Projection: (number + 1):UInt64 │
│ Expression: (number + 1):UInt64 (Before Projection) │
│ Filter: (number > 8) │
│ ReadDataSource: scan partitions: [1], scan schema: [number:UInt64], statistics: [read_rows: 10, read_bytes: 80] │
└────────────────────────────────────────────────────────────────────────────────────────────────┘
这个执行计划自下而上分别是 :
-
ReadDataSource:表示从哪些文件里读取数据
-
Filter: 表示要做 (number > 8) 表达式过滤
-
Expression: 表示要做 (number + 1) 表达式运算
-
Projection: 表示查询列是哪些
-
Limit: 表示取前 2 条数据
优化器 (Optimizer)
对执行计划做一些基于规则的优化(A Rule Based Optimizer), 比如做一些谓词下推或是去掉一些不必要的列等,以使整个执行计划更优。
处理器 (Processors)
处理器(Processor)是执行计算逻辑的核心组件。根据执行计划,处理器们被编排成一个流水线(Pipeline),用于执行计算任务。
整个 Pipeline 是一个有向无环图,每个点是一个处理器,每条边由处理器的 InPort 和 OutPort 相连构成,数据到达不同的处理器进行计算后,通过边流向下一个处理器,多个处理器可以并行计算,在集群模式下还可以跨节点分布式执行,这是 Datafuse 高性能的一个重要设计。
例如,我们可以通过 EXPLAIN PIPELINE 来查看:
databend :) EXPLAIN PIPELINE SELECT number + 1 FROM numbers_mt(10000) WHERE number > 8 LIMIT 2
┌─explain───────────────────────────────────────────────────────────────┐
│ LimitTransform × 1 processor │
│ Merge (ProjectionTransform × 16 processors) to (LimitTransform × 1) │
│ ProjectionTransform × 16 processors │
│ ExpressionTransform × 16 processors │
│ FilterTransform × 16 processors │
│ SourceTransform × 16 processors │
└───────────────────────────────────────────────────────────────────────┘
同样,理解这个 Pipeline 我们自下而上来看:
- SourceTransform:读取数据文件,16 个物理 CPU 并行处理
- ilterTransform:对数据进行 (number > 8) 表达式过滤,16 个物理 CPU 并行处理
- pressionTransform:对数据进行 (number + 1) 表达式执行,16 个物理 CPU 并行处理
- ojectionTransform:对数据处理生成最终列
- LimitTransform:对数据进行 Limit 2 处理,Pipeline 进行折叠,由一个物理 CPU 来执行
- Databend 通过 Pipeline 并行模型,并结合向量计算最大限度的去压榨 CPU 资源,以加速计算。
缓存 ( Cache )
计算节点使用本地 SSD 缓存数据和索引,以提高数据亲和性来加速计算。
缓存的预热方式有:
LOAD_ON_DEMAND - 按需加载索引或数据块(默认)。
LOAD_INDEX - 只加载索引。
LOAD_ALL - 加载全部的数据和索引,对于较小的表可以采取这种模式。
3. Storage Layer
Databend 使用 Parquet 列式存储格式来储存数据,为了加快查找(Partition Pruning),Databend 为每个 Parquet 提供了自己的索引(根据 Primary Key 生成):
min_max.idx Parquet 文件 minimum 和 maximum 值
sparse.idx 以 N 条记录为颗粒度的稀疏索引
通过这些索引, 我们可以减少数据的交互,并使计算量大大减少。
假设有两个Parquet 文件:f1, f2,f1 的 min_max.idx: [3, 5] ;f2 的 min_max.idx: [4, 6] 。如果查询条件为:where x < 4 , 我们只需要 f1 文件就可以,再根据 sparse.idx 索引定位到 f1 文件中的某个数据页。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



