
原标题:Spring认证|Spring Data JPA 参考文档六(内容来源:Spring中国教育管理中心)
5.1.4. 存储过程
JPA 2.1 规范引入了对使用 JPA 条件查询 API 调用存储过程的支持。我们引入了@Procedure用于在存储库方法上声明存储过程元数据的注释。
以下示例使用以下存储过程:
Example 91. plus1inoutHSQL DB 中过程的定义。
/;
DROP procedure IF EXISTS plus1inout
/;
CREATE procedure plus1inout (IN arg int, OUT res int)
BEGIN ATOMIC
set res = arg + 1;
END
/;
可以通过使用NamedStoredProcedureQuery实体类型上的注释来配置存储过程的元数据。
示例 92.实体上的 StoredProcedure 元数据定义。
@Entity
@NamedStoredProcedureQuery(name = "User.plus1", procedureName = "plus1inout", parameters = {
@StoredProcedureParameter(mode = ParameterMode.IN, name = "arg", type = Integer.class),
@StoredProcedureParameter(mode = ParameterMode.OUT, name = "res", type = Integer.class) })
public class User {}
请注意,@NamedStoredProcedureQuery存储过程有两个不同的名称。 name是 JPA 使用的名称。procedureName是存储过程在数据库中的名称。
您可以通过多种方式从存储库方法中引用存储过程。要调用的存储过程可以直接使用注解的value或procedureName属性定义@Procedure。这直接引用数据库中的存储过程,并忽略通过@
NamedStoredProcedureQuery.
或者,您可以将@
NamedStoredProcedureQuery.name属性指定为@Procedure.name属性。如果没有value,procedureName也没有name被配置,存储库方法的名称被用作name属性。
以下示例显示了如何引用显式映射的过程:
示例 93. 引用数据库中名称为“plus1inout”的显式映射过程。
@Procedure("plus1inout")
Integer explicitlyNamedPlus1inout(Integer arg);
以下示例与前一个示例等效,但使用procedureName别名:
示例 94. 通过procedureName别名在数据库中引用名为“plus1inout”的隐式映射过程。
@Procedure(procedureName = "plus1inout")
Integer callPlus1InOut(Integer arg);
以下再次等效于前两个,但使用方法名称而不是显式注释属性。
示例 95.EntityManager使用方法名称引用隐式映射的命名存储过程“User.plus1” 。
@Procedure
Integer plus1inout(@Param("arg") Integer arg);
以下示例显示如何通过引用@
NamedStoredProcedureQuery.name属性来引用存储过程。
示例 96.在EntityManager.
@Procedure(name = "User.plus1IO")
Integer entityAnnotatedCustomNamedProcedurePlus1IO(@Param("arg") Integer arg);
如果被调用的存储过程有一个单出参数,则该参数可以作为方法的返回值返回。如果在@NamedStoredProcedureQuery注释中指定了多个输出参数,则这些参数可以作为 a 返回,Map键是@NamedStoredProcedureQuery注释中给出的参数名称。
5.1.5. 规格
JPA 2 引入了一个标准 API,您可以使用它以编程方式构建查询。通过编写criteria,您可以定义域类查询的 where 子句。再退一步,这些标准可以被视为对 JPA 标准 API 约束所描述的实体的谓词。
Spring Data JPA 从 Eric Evans 的书“Domain Driven Design”中采用了规范的概念,遵循相同的语义并提供 API 以使用 JPA 标准 API 定义此类规范。为了支持规范,您可以使用该JpaSpecificationExecutor接口扩展您的存储库接口,如下所示:
public interface CustomerRepository extends CrudRepository<Customer, Long>, JpaSpecificationExecutor<Customer> {
…
}
附加接口的方法可以让您以多种方式运行规范。例如,该findAll方法返回与规范匹配的所有实体,如以下示例所示:
List<T> findAll(Specification<T> spec);
的Specification接口被定义为如下:
public interface Specification<T> {
Predicate toPredicate(Root<T> root, CriteriaQuery<?> query,
CriteriaBuilder builder);
}
规范可以很容易地用于在实体之上构建一组可扩展的谓词,然后可以组合和使用这些谓词,JpaRepository而无需为每个需要的组合声明查询(方法),如以下示例所示:
示例 97. 客户规格
public class CustomerSpecs {
public static Specification<Customer> isLongTermCustomer() {
return (root, query, builder) -> {
LocalDate date = LocalDate.now().minusYears(2);
return builder.lessThan(root.get(Customer_.createdAt), date);
};
}
public static Specification<Customer> hasSalesOfMoreThan(MonetaryAmount value) {
return (root, query, builder) -> {
// build query here
};
}
}
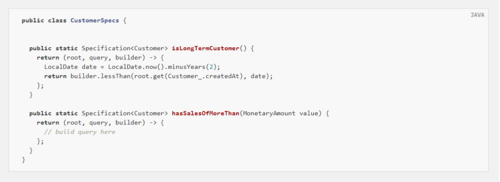
该Customer_类型是使用 JPA 元模型生成器生成的元模型类型(有关示例,请参阅Hibernate 实现的文档)。因此表达式 ,Customer_.createdAt假定Customer具有createdAt类型的属性Date。除此之外,我们在业务需求抽象级别上表达了一些标准并创建了可执行文件Specifications。所以客户端可能会使用 aSpecification如下:
示例 98. 使用简单的规范
List<Customer> customers = customerRepository.findAll(isLongTermCustomer());
为什么不为这种数据访问创建查询?Specification与普通的查询声明相比,使用单个并没有太大的好处。当您将规范组合起来创建新Specification对象时,规范的力量会真正发挥作用。您可以通过Specification我们提供的默认方法来实现这一点,以构建类似于以下内容的表达式:
示例 99. 组合规格
MonetaryAmount amount = new MonetaryAmount(200.0, Currencies.DOLLAR);
List<Customer> customers = customerRepository.findAll(
isLongTermCustomer().or(hasSalesOfMoreThan(amount)));
Specification提供了一些“胶水代码”默认方法来链接和组合Specification实例。这些方法让您可以通过创建新的Specification实现并将它们与现有的实现相结合来扩展数据访问层。
5.1.6. 按示例查询
介绍
本章介绍了 Query by Example 并解释了如何使用它。
示例查询 (QBE) 是一种用户友好的查询技术,具有简单的界面。它允许动态创建查询,并且不需要您编写包含字段名称的查询。事实上,Query by Example 根本不需要您使用特定于商店的查询语言编写查询。
用法
Query by Example API 由三部分组成:
探针:具有填充字段的域对象的实际示例。
ExampleMatcher:ExampleMatcher包含有关如何匹配特定字段的详细信息。它可以在多个示例中重复使用。
Example: AnExample由探针和ExampleMatcher. 它用于创建查询。
Query by Example 非常适合以下几个用例:
使用一组静态或动态约束查询您的数据存储。
频繁重构域对象而不必担心破坏现有查询。
独立于底层数据存储 API 工作。
Query by Example 也有几个限制:
不支持嵌套或分组的属性约束,例如firstname = ?0 or (firstname = ?1 and lastname = ?2).
仅支持字符串的开始/包含/结束/正则表达式匹配以及其他属性类型的精确匹配。
在开始使用 Query by Example 之前,您需要有一个域对象。首先,为您的存储库创建一个接口,如以下示例所示:
示例 100. 示例 Person 对象
public class Person {
@Id
private String id;
private String firstname;
private String lastname;
private Address address;
// … getters and setters omitted
}

前面的示例显示了一个简单的域对象。您可以使用它来创建Example. 默认情况下,null忽略具有值的字段,并使用商店特定的默认值匹配字符串。
将属性包含在 Query by Example 标准中是基于可空性。除非忽略属性路径,否则始终包含使用原始类型 ( int, double, ...)的属性。
可以使用of工厂方法或使用ExampleMatcher. Example是不可变的。以下清单显示了一个简单的示例:
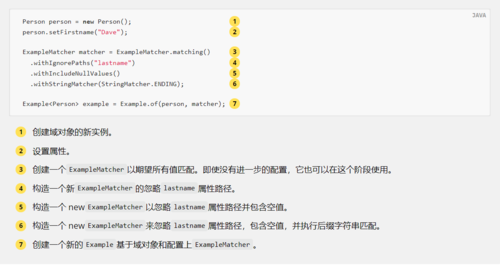
示例 101. 简单示例
Person person = new Person();
person.setFirstname("Dave");
Example<Person> example = Example.of(person);
创建域对象的新实例。
设置要查询的属性。
创建Example.
您可以使用存储库运行示例查询。为此,让您的存储库接口扩展QueryByExampleExecutor<T>. 以下清单显示了QueryByExampleExecutor界面的摘录:
例 102. QueryByExampleExecutor
public interface QueryByExampleExecutor<T> {
<S extends T> S findOne(Example<S> example);
<S extends T> Iterable<S> findAll(Example<S> example);
// … more functionality omitted.
}
示例匹配器
示例不限于默认设置。您可以使用 为字符串匹配、空值处理和特定于属性的设置指定自己的默认值ExampleMatcher,如以下示例所示:
示例 103. 具有自定义匹配的示例匹配器
Person person = new Person();
person.setFirstname("Dave");
ExampleMatcher matcher = ExampleMatcher.matching()
.withIgnorePaths("lastname")
.withIncludeNullValues()
.withStringMatcher(StringMatcher.ENDING);
Example<Person> example = Example.of(person, matcher);
创建域对象的新实例。
设置属性。
创建一个ExampleMatcher以期望所有值匹配。即使没有进一步的配置,它也可以在这个阶段使用。
构造一个新ExampleMatcher的忽略lastname属性路径。
构造一个 newExampleMatcher以忽略lastname属性路径并包含空值。
构造一个 newExampleMatcher来忽略lastname属性路径,包含空值,并执行后缀字符串匹配。
创建一个新的Example基于域对象和配置上ExampleMatcher。
默认情况下,ExampleMatcher期望在探测器上设置的所有值都匹配。如果要获得与任何隐式定义的谓词匹配的结果,请使用
ExampleMatcher.matchingAny().
您可以为单个属性指定行为(例如“名字”和“姓氏”,或者对于嵌套属性,“address.city”)。您可以使用匹配选项和区分大小写来调整它,如以下示例所示:
示例 104. 配置匹配器选项
ExampleMatcher matcher = ExampleMatcher.matching()
.withMatcher("firstname", endsWith())
.withMatcher("lastname", startsWith().ignoreCase());
}
另一种配置匹配器选项的方法是使用 lambdas(在 Java 8 中引入)。这种方法创建了一个回调,要求实现者修改匹配器。您不需要返回匹配器,因为配置选项保存在匹配器实例中。以下示例显示了使用 lambda 的匹配器:
示例 105. 使用 lambda 配置匹配器选项
ExampleMatcher matcher = ExampleMatcher.matching()
.withMatcher("firstname", match -> match.endsWith())
.withMatcher("firstname", match -> match.startsWith());
}
Example使用配置的合并视图创建的查询。默认匹配设置可以在ExampleMatcher级别设置,而单独的设置可以应用于特定的属性路径。已设置上的设置ExampleMatcher由属性路径设置继承,除非它们被明确定义。属性补丁上的设置比默认设置具有更高的优先级。下表描述了各种ExampleMatcher设置的范围:

运行示例
在 Spring Data JPA 中,您可以将 Query by Example 与 Repositories 一起使用,如下例所示:
示例 106. 使用存储库按示例查询
public interface PersonRepository extends JpaRepository<Person, String> { … }
public class PersonService {
@Autowired PersonRepository personRepository;
public List<Person> findPeople(Person probe) {
return personRepository.findAll(Example.of(probe));
}
}
目前,只有SingularAttribute属性可以用于属性匹配。
属性说明符接受属性名称(例如firstname和lastname)。您可以通过将属性与点 ( address.city)链接在一起进行导航。您还可以使用匹配选项和区分大小写来调整它。
下表显示了StringMatcher您可以使用的各种选项以及在名为 的字段上使用它们的结果firstname:

5.1.7. 交易性
默认情况下,从存储库实例继承的 CRUD 方法SimpleJpaRepository是事务性的。对于读取操作,事务配置readOnly标志设置为true。所有其他人都使用普通配置,@Transactional以便应用默认事务配置。由事务存储库片段支持的存储库方法从实际片段方法继承事务属性。
如果您需要为存储库中声明的方法之一调整事务配置,请在存储库接口中重新声明该方法,如下所示:
示例 107. CRUD 的自定义事务配置
public interface UserRepository extends CrudRepository<User, Long> {
@Override
@Transactional(timeout = 10)
public List<User> findAll();
// Further query method declarations
}
这样做会导致findAll()方法以 10 秒的超时时间运行并且没有readOnly标志。
改变事务行为的另一种方法是使用(通常)覆盖多个存储库的外观或服务实现。其目的是为非 CRUD 操作定义事务边界。以下示例展示了如何将这样的外观用于多个存储库:
示例 108. 使用 Facade 为多个存储库调用定义事务
@Service
public class UserManagementImpl implements UserManagement {
private final UserRepository userRepository;
private final RoleRepository roleRepository;
public UserManagementImpl(UserRepository userRepository,
RoleRepository roleRepository) {
this.userRepository = userRepository;
this.roleRepository = roleRepository;
}
@Transactional
public void addRoleToAllUsers(String roleName) {
Role role = roleRepository.findByName(roleName);
for (User user : userRepository.findAll()) {
user.addRole(role);
userRepository.save(user);
}
}
}
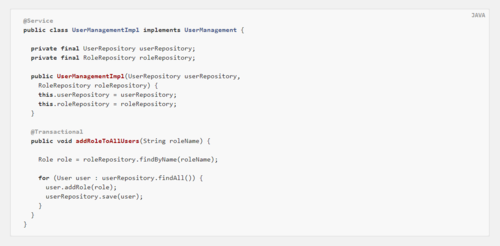
此示例导致调用addRoleToAllUsers(…)在事务内运行(参与现有事务或创建新事务,如果尚未运行)。然后忽略存储库中的事务配置,因为外部事务配置决定了实际使用的事务配置。请注意,您必须显式激活<tx:annotation-driven />或使用@
EnableTransactionManagement才能使外观的基于注释的配置工作。此示例假定您使用组件扫描。
请注意,save从 JPA 的角度来看,调用 to并不是绝对必要的,但仍应存在以与 Spring Data 提供的存储库抽象保持一致。
事务查询方法
要让您的查询方法具有事务性,请@Transactional在您定义的存储库接口处使用,如以下示例所示:
示例 109.在查询方法中使用 @Transactional
@Transactional(readOnly = true)
interface UserRepository extends JpaRepository<User, Long> {
List<User> findByLastname(String lastname);
@Modifying
@Transactional
@Query("delete from User u where u.active = false")
void deleteInactiveUsers();
}
通常,您希望将该readOnly标志设置为true,因为大多数查询方法只读取数据。与此相反,deleteInactiveUsers()使用@Modifying注释并覆盖事务配置。因此,该方法在readOnly标志设置为 的情况下运行false。
您可以将事务用于只读查询,并通过设置readOnly标志来标记它们。但是,这样做并不能检查您是否不会触发操纵查询(尽管某些数据库拒绝INSERT和UPDATE只读事务中的语句)。该readOnly标志会作为对底层 JDBC 驱动程序的提示进行传播,以进行性能优化。此外,Spring 对底层 JPA 提供程序执行了一些优化。例如,当与 Hibernate 一起使用时,刷新模式NEVER在您将事务配置为时设置为readOnly,这会导致 Hibernate 跳过脏检查(对大对象树的显着改进)。
内容来源:Spring中国教育管理中心(Spring认证)

2021年2月,VMware公司正式与北京中科卓望网络科技有限公司(以下简称:中科卓望)达成战略合作,授予其 Spring 中国教育管理中心,携手 VMware 全球最新 Spring技术和认证体系,帮助中国院校构建专业教学内容,全面赋能未来开发人。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



