
欢迎访问我的GitHub
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
本篇概览
- 本文是《disruptor笔记》系列的终篇,前面咱们看了那么多代码,也写了那么多代码,现在咱们去看几个知识点,在轻松的阅读过程中完成disruptor之旅;
- 要关注的知识点有以下四处:
- 伪共享
- Translators
- Lambda风格
- 清理数据
- 接下来开始逐个了解;
伪共享
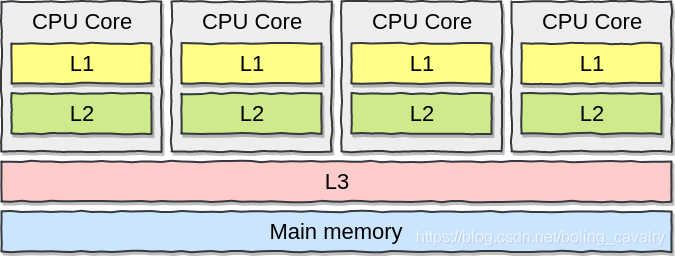
- 下图是多核处理器的CPU缓存,可见每个核都有自己的L1和L2缓存,而L3缓存是共享的:
-
假设disruptor的Sequence是long型,那么一个生产者和一个消费者的disruptor应该有两个long型Sequence,在L1中缓存这两个数字时,因为每个缓存行大小是64字节,所以两个Sequence很有可能在一个缓存行中
-
此时如果程序修改了生产者Sequence的值,就会让L1上对应的缓存行失效,再从Main memory中读取最新的值,此时因为消费者Sequence也在同一个缓存行中,因此也被失效了,这就导致一个没有变化的值也被清理掉,还要再去Main memory中取一次,这是影响性能的行为
-
看到这里,聪明的您一定想到解决问题的思路:不要让两个Sequence在同一个缓存行中
-
具体的手段呢?您有没有联想到日常生活中的占座位,在身边座位放个背包,其他人就不能使用了(这是不文明行为,仅举例用)
-
实际上disruptor用的也是占座的套路,咱们来看看Sequence的源码就一目了然了,如下图所示,Sequence的值是Value对象的成员变量value:
// 父类,
class LhsPadding
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding
{
protected volatile long value;
}
class RhsPadding extends Value
{
protected long p9, p10, p11, p12, p13, p14, p15;
}
public class Sequence extends RhsPadding
{
...
- 类图如下,可见Value的父子类中都是占位的long型:
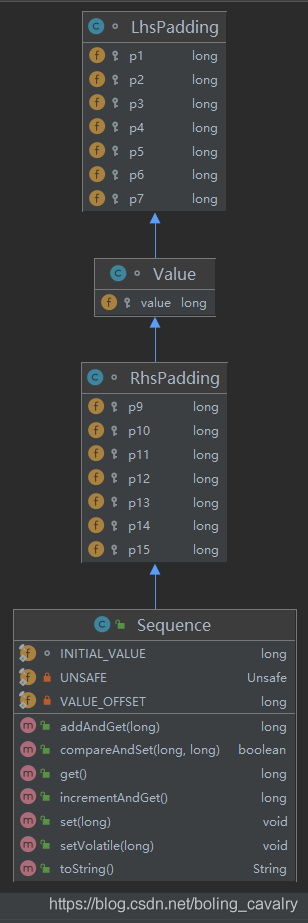
- 因此,Sequence对象有16个成员变量,在L1 cache中是下图的排列方式:

- 想像一下,L1 cache的缓存行,每64字节为一个,也就是说上面那一串,每八个就占据一个缓存行(每个long型8字节),于是就有以下三种排列的可能:
- V出现在一个缓存行的首位;
- V出现在一个缓存行的末尾;
- V出现在一个缓存行的首位和末尾之间的其他六个位置之一;
- 也就是下图三种可能(U是L1 cache中的其他内容),可见不论哪种可能,V都能用P把自己所在缓存行全部占座,这样就不会出现两个Sequence出现在同一个缓存行的情况了:

Translators
-
Translators是个小的编程技巧,disruptor帮使用者做了些封装,让发布事件的代码更简洁;
-
打开disruptor-tutorials项目的consume-mode这个module,回顾一下,业务发布事件要调用的方法,在OrderEventProducer.java中:
public void onData(String content) {
// ringBuffer是个队列,其next方法返回的是下最后一条记录之后的位置,这是个可用位置
long sequence = ringBuffer.next();
try {
// sequence位置取出的事件是空事件
OrderEvent orderEvent = ringBuffer.get(sequence);
// 空事件添加业务信息
orderEvent.setValue(content);
} finally {
// 发布
ringBuffer.publish(sequence);
}
}
-
上面的代码中,其实开发者最关注的是orderEvent.setValue(content)这部分,其他几行是我从官方demo抄的…
-
显然disruptor也发现了这个小问题,于是从3.0版本开始提供了EventTranslatorOneArg接口,开发者将业务逻辑放入放在此接口的实现类中,至于前面代码中的ringBuffer.next()、ringBuffer.get(sequence)这些,以及try-finally代码块这些东西统统都省去了,咱们可以将OrderEventProducer.java改造成一个新的类,代码如下,可见新增内部类EventTranslatorOneArg,里面是将数据转为事件的业务逻辑,对外提供调用的onData方法中,只需一行代码即可,和业务无关的代码全部省掉了:
package com.bolingcavalry.service;
import com.lmax.disruptor.EventTranslatorOneArg;
import com.lmax.disruptor.RingBuffer;
public class OrderEventProducerWithTranslator {
// 存储数据的环形队列
private final RingBuffer<OrderEvent> ringBuffer;
public OrderEventProducerWithTranslator(RingBuffer<OrderEvent> ringBuffer) {
this.ringBuffer = ringBuffer;
}
/**
* 内部类
*/
private static final EventTranslatorOneArg<OrderEvent, String> TRANSLATOR = new EventTranslatorOneArg<OrderEvent, String>() {
@Override
public void translateTo(OrderEvent event, long sequence, String arg0) {
event.setValue(arg0);
}
};
public void onData(String content) {
ringBuffer.publishEvent(TRANSLATOR, content);
}
}
-
在consume-mode中,上述代码有对应的服务类TranslatorPublishServiceImpl.java,并且有对应的单元测试代码(ConsumeModeServiceTest.testTranslatorPublishService),这里就不占篇幅了,您若有兴趣可以自行查阅;
-
看看ringBuffer.publishEvent的内部实现,是如何帮咱们省去之前那几行的,首先是调用了sequencer.next:
@Override
public <A> void publishEvent(EventTranslatorOneArg<E, A> translator, A arg0)
{
final long sequence = sequencer.next();
translateAndPublish(translator, sequence, arg0);
}
- 再打开translateAndPublish看看,ringBuffer.get、try-finally代码块、sequencer.publish都在,这下放心了,以前咱们做的事情,现在disruptor帮我们做了,咱们可以专心业务逻辑了:
private <A> void translateAndPublish(EventTranslatorOneArg<E, A> translator, long sequence, A arg0)
{
try
{
translator.translateTo(get(sequence), sequence, arg0);
}
finally
{
sequencer.publish(sequence);
}
}
Lambda风格
- disruptor的重要API也支持Lambda表达式作为入参,这里将几处常用的API整理如下:
- Disruptor类实例化(LambdaServiceImpl.java):
// lambda类型的实例化
disruptor = new Disruptor<OrderEvent>(OrderEvent::new, BUFFER_SIZE, DaemonThreadFactory.INSTANCE);
- 设置事件消费者的时候,可以用Lambda取代之前的对象(LambdaServiceImpl.java):
// lambda表达式指定具体消费逻辑
disruptor.handleEventsWith((event, sequence, endOfBatch) -> {
log.info("lambda操作, sequence [{}], endOfBatch [{}], event : {}", sequence, endOfBatch, event);
// 这里延时100ms,模拟消费事件的逻辑的耗时
Thread.sleep(100);
// 计数
eventCountPrinter.accept(null);
});
- 发布事件的操作,也支持Lambda表达式,如下所示,我在父类ConsumeModeService.java中新增publistEvent方法,里面调用的disruptor.getRingBuffer().publishEvent的入参就是Lambda表达式和事件所需的业务数据,这样就省区了以前发布事件的类OrderEventProducer.java:
public void publistEvent(EventTranslatorOneArg<OrderEvent, String> translator, String value) {
disruptor.getRingBuffer().publishEvent(translator, value);
}
- 如下所示,现在拿到业务数据后发布事件的操作变得非常轻了,Lambda表达式中做好业务数据转事件的逻辑即可,最终,不再需要OrderEventProducer.java,一行代码完成事件发布(ConsumeModeServiceTest.java):
for(int i=0;i<EVENT_COUNT;i++) {
log.info("publich {}", i);
final String content = String.valueOf(i);
lambdaService.publistEvent((event, sequence, value) -> event.setValue(value), content);
}
清理数据
- 由于存储的数据结构是环形队列,对于每个事件的实例,会一直保存在队列中,直到再次在这个位置写入时才会被新的事件实例覆盖,考虑到可能有的场景要求数据被消费后就立即被清除,disruptor官方提供了以下建议:
- 事件定义的类中,增加一个清理业务数据的方法(假设是ObjectEvent类的clear方法);
- 新增一个事件处理类(假设是ClearingEventHandler),在里面主动调用事件定义类的清理业务数据的方法;
- 在编写事件消费逻辑时,最后添加上述事件处理类ClearingEventHandler,这样就会调用ObjectEvent实例的clear方法,将业务数据清理掉;
- 官方给出的代码如下:

- 至此,整个《disruptor笔记》就完成了,感谢您的关注,希望这个系列的内容能给您带来帮助,在开发中多一些选择和参考;
我是欣宸,期待与您一同畅游Java世界…
https://github.com/zq2599/blog_demos
共同学习,写下你的评论
评论加载中...
作者其他优质文章


