
欢迎访问我的GitHub
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
本篇概览
本文是《disruptor笔记》的第七篇,咱们一起阅读源码,学习一个重要的知识点:等待策略,由于Disruptor的源码短小精干、简单易懂,因此本篇是个轻松愉快的源码学习之旅;
提前小结
如果您时间不充裕,可以通过以下提前小结的内容,对等待策略有个大体的认识:
- BlockingWaitStrategy:用了ReentrantLock的等待&&唤醒机制实现等待逻辑,是默认策略,比较节省CPU
- BusySpinWaitStrategy:持续自旋,JDK9之下慎用(最好别用)
- DummyWaitStrategy:返回的Sequence值为0,正常环境是用不上的
- LiteBlockingWaitStrategy:基于BlockingWaitStrategy,在没有锁竞争的时候会省去唤醒操作,但是作者说测试不充分,不建议使用
- TimeoutBlockingWaitStrategy:带超时的等待,超时后会执行业务指定的处理逻辑
- LiteTimeoutBlockingWaitStrategy:基于TimeoutBlockingWaitStrategy,在没有锁竞争的时候会省去唤醒操作
- SleepingWaitStrategy:三段式,第一阶段自旋,第二阶段执行Thread.yield交出CPU,第三阶段睡眠执行时间,反复的的睡眠
- YieldingWaitStrategy:二段式,第一阶段自旋,第二阶段执行Thread.yield交出CPU
- PhasedBackoffWaitStrategy:四段式,第一阶段自旋指定次数,第二阶段自旋指定时间,第三阶段执行Thread.yield交出CPU,第四阶段调用成员变量的waitFor方法,这个成员变量可以被设置为BlockingWaitStrategy、LiteBlockingWaitStrategy、SleepingWaitStrategy这三个中的一个
关于等待策略
- 回顾一下前面的文章中实例化Disruptor的代码:
disruptor = new Disruptor<>(new OrderEventFactory(),
BUFFER_SIZE,
new CustomizableThreadFactory("event-handler-"));
- 展开上述构造方法,会见到创建RingBuffer的代码,默认使用了BlockingWaitStrategy作为等待策略:
public static <E> RingBuffer<E> createMultiProducer(EventFactory<E> factory, int bufferSize)
{
return createMultiProducer(factory, bufferSize, new BlockingWaitStrategy());
}
- 继续展开上面的createMultiProducer方法,可见每个Sequencer(注意不是Sequence)都有自己的watStrategy成员变量:
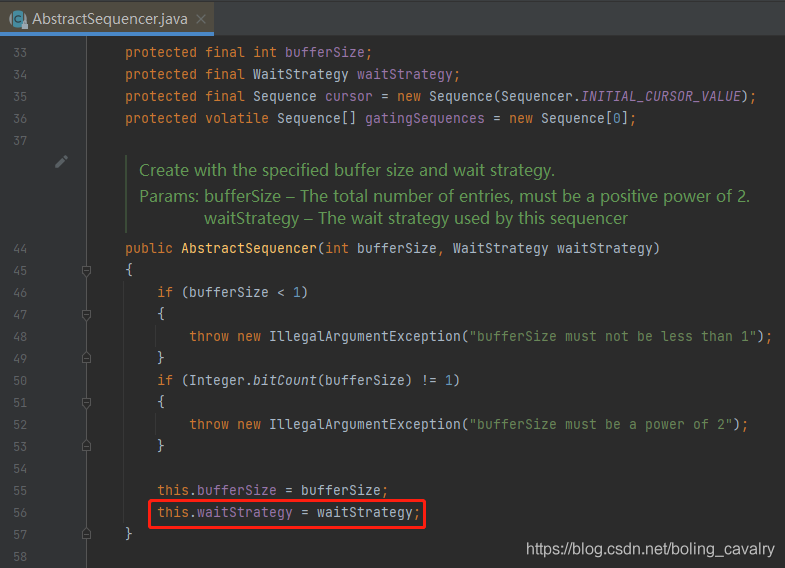
- 这个waitStrategy的最终用途是创建SequenceBarrier的时候,传给SequenceBarrier做成员变量:

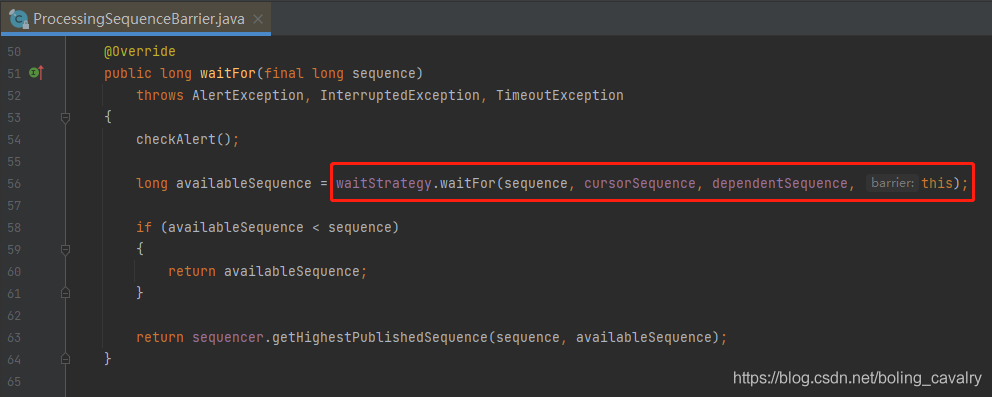
- 在看看SequenceBarrier是如何使用waitStrategy的,一共两处用到,第一处如下图红框,原来是waitFor方法内部会用到,这个waitFor咱们前面已经了解过,对消费者来说,等待环形队列的指定位置有可用数据时,就是调用SequenceBarrier的waitFor完成的:
- SequenceBarrier第二处用到waitStrategy是唤醒的时候:
@Override
public void alert()
{
alerted = true;
waitStrategy.signalAllWhenBlocking();
}
- 现在咱们知道了WaitStrategy的使用场景,接下来看看这个接口有哪些具体实现吧,这样咱们在编程中就知道如何选择才最适合自己
BlockingWaitStrategy
- 作为默认的等待策略,BlockingWaitStrategy还有个特点就是代码量小(不到百行),很容易理解,其实就是用ReentrantLock+Condition来实现等待和唤醒操作的,如下图红框:
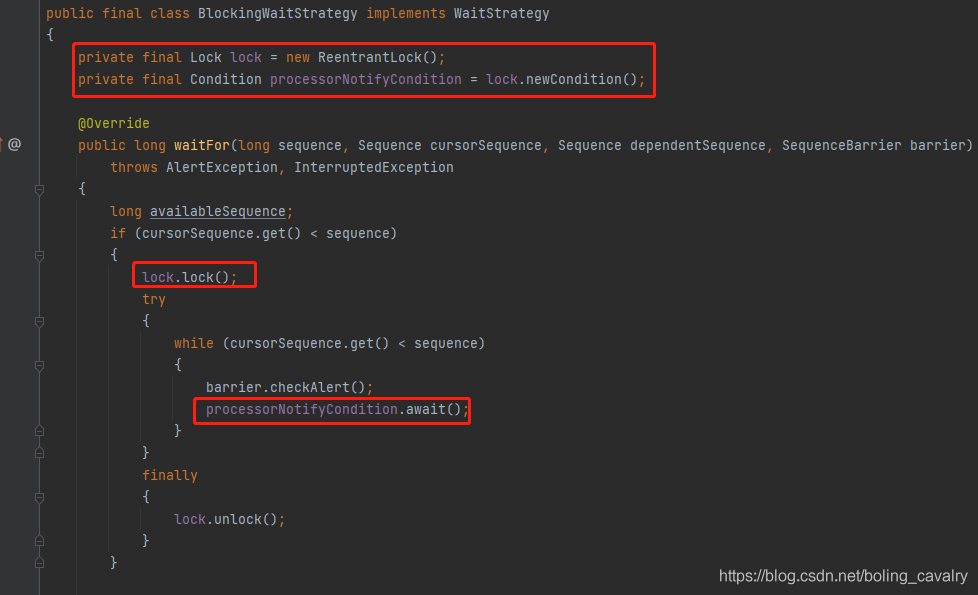
- 如果您更倾向于节省CPU资源,对高吞吐量和低延时的要求相对低一些,那么BlockingWaitStrategy就适合您了;
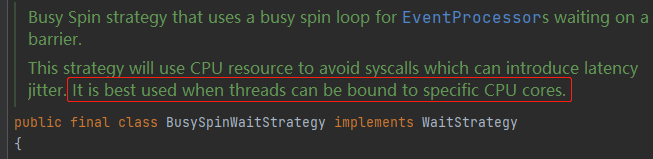
BusySpinWaitStrategy(慎用)
- 前面的BlockingWaitStrategy有个特点,就是一旦环形队列指定位置来了数据,由于线程是等待状态(底层调用了native的UNSAFE.park方法),因此还要唤醒后才能执行业务逻辑,在一些场景中希望数据一到就尽快消费,此时BusySpinWaitStrategy就很合适了,代码太简单,全部贴出:
public final class BusySpinWaitStrategy implements WaitStrategy
{
@Override
public long waitFor(
final long sequence, Sequence cursor, final Sequence dependentSequence, final SequenceBarrier barrier)
throws AlertException, InterruptedException
{
long availableSequence;
while ((availableSequence = dependentSequence.get()) < sequence)
{
barrier.checkAlert();
ThreadHints.onSpinWait();
}
return availableSequence;
}
@Override
public void signalAllWhenBlocking()
{
}
}
- 上述代码显示,整个while循环的关键就是ThreadHints.onSpinWait做了什么,源码如下,这里要格外注意,如果ON_SPIN_WAIT_METHOD_HANDLE为空,意味着外面的while循环是个非常消耗CPU的自旋:
public static void onSpinWait()
{
if (null != ON_SPIN_WAIT_METHOD_HANDLE)
{
try
{
ON_SPIN_WAIT_METHOD_HANDLE.invokeExact();
}
catch (final Throwable ignore)
{
}
}
}
- ON_SPIN_WAIT_METHOD_HANDLE为空是很可怕的事情,咱们来看看它是何方神圣?代码还是在ThreadHints.java中,如下所示,真相一目了然,它就是Thread类的onSpinWait方法,如果Thread类没有onSpinWait方法,那么使用BusySpinWaitStrategy作为等待策略就有很高的代价了,环形队列里没有数据时消费线程会执行自旋,很耗费CPU:
static
{
final MethodHandles.Lookup lookup = MethodHandles.lookup();
MethodHandle methodHandle = null;
try
{
methodHandle = lookup.findStatic(Thread.class, "onSpinWait", methodType(void.class));
}
catch (final Exception ignore)
{
}
ON_SPIN_WAIT_METHOD_HANDLE = methodHandle;
}
-
好吧,还剩两个问题:Thread类有没有onSpinWait方法还不能确定吗?这个onSpinWait方法是何方神圣?
-
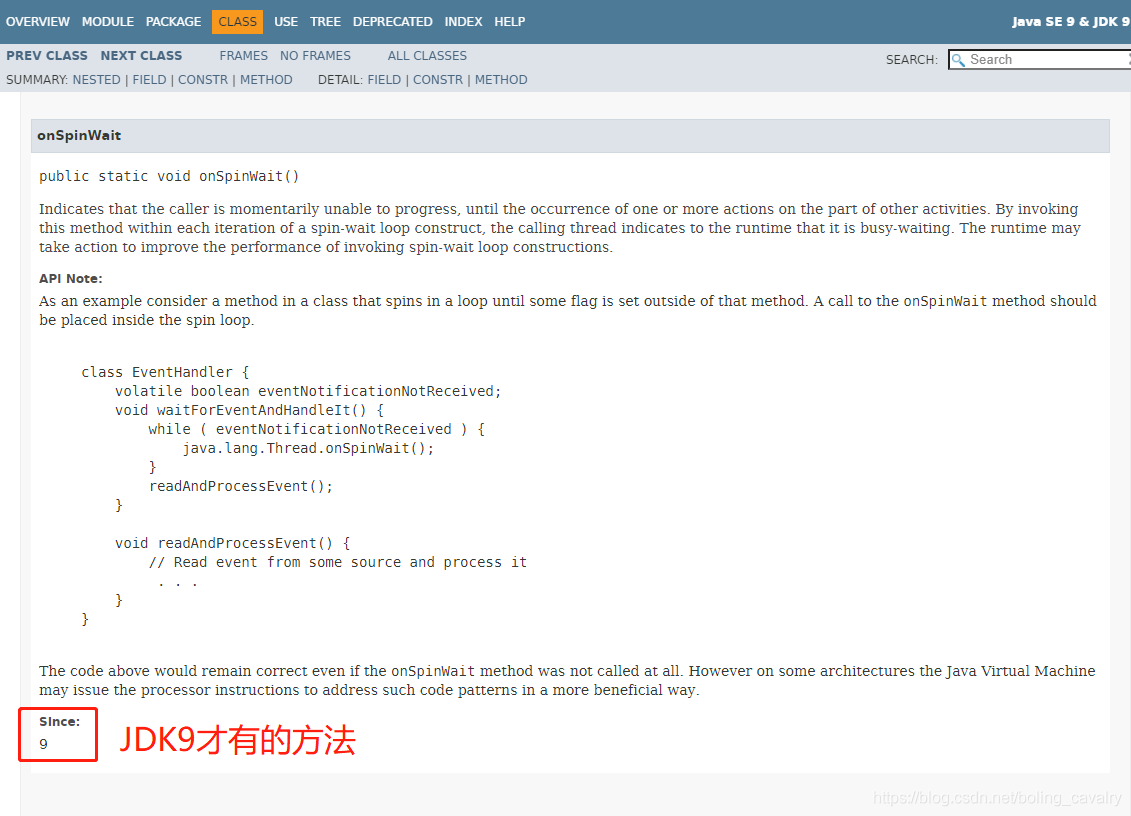
去看JDK官方文档,如下图,原来这方法是从JDK9才有的,所以对于JDK8使用者来说来说,选用BusySpinWaitStrategy就意味着要面对没做啥事儿的while循环了:
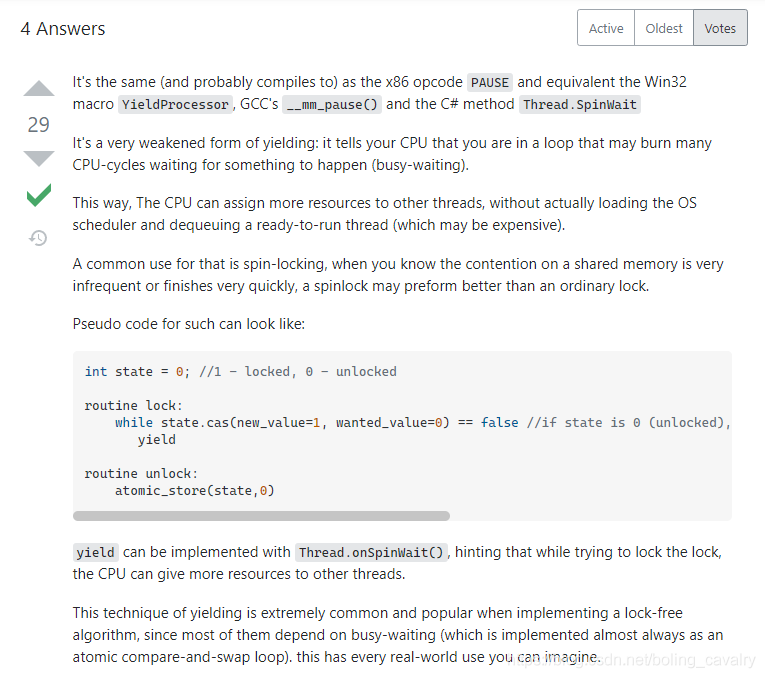
- 第二个问题,onSpinWait方法干了些啥?前面的官方文档,以欣宸的英语水平显然是无法理解的,去看stackoverflow吧,如下图,简单的说,就是告诉CPU当前线程处于循环查询的状态,CPU得知后就会调度更多CPU资源给其他线程:
-
至此真像大白:环形队列的条件就绪后,BusySpinWaitStrategy策略是通过whlie死循环来做到快速响应的,如果JDK是9或者更高版本,这个死循环带来的CPU损耗由Thread.onSpinWait帮助缓解,如果JDK版本低于9,这里就是个简单的while死循环,至于这种死循环有多消耗CPU,您可以写段简单代码感受一下…
-
难怪Disruptor源码中会提醒最好是将使用此实例的线程绑定到指定CPU核:
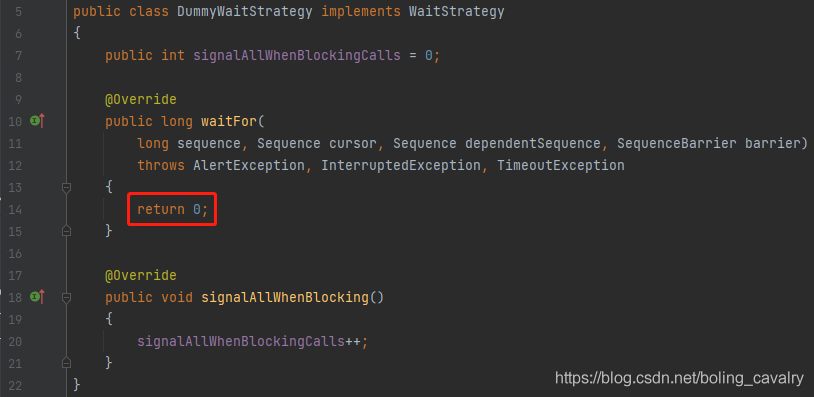
DummyWaitStrategy
固定返回0,个人觉得这个策略在正常开发中用不上,因为环形队列可用位置始终是0的话,不论是生产还是消费都难以实现:
LiteBlockingWaitStrategy
- 看名字,LiteBlockingWaitStrategy是BlockingWaitStrategy策略的轻量级实现,在锁没有竞争的时候(例如独立消费的场景),会省略掉唤醒操作,不过如下图红框所示,作者说他没有充分验证过正确性,因此建议只用于体验,太好了,这个策略我不学了!!!

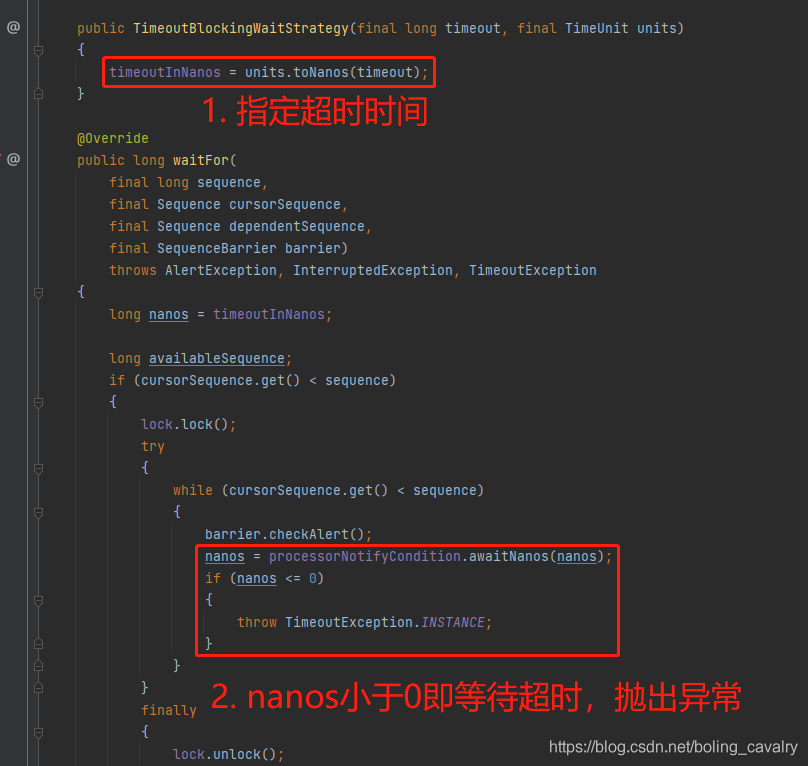
TimeoutBlockingWaitStrategy
- 顾名思义,TimeoutBlockingWaitStrategy表示只等待某段时长,超过了就算超时,其代码和BlockingWaitStrategy类似,只是等待的时候有个时长限制,如下图,一目了然:
- 其实我对抛出异常后的处理很感兴趣,去看看吧,外面是熟悉的BatchEventProcessor类,熟悉的processEvents方法,如下图,每次超时异常都交给notifyTimeout处理,而外部的主流程不受影响,依旧不断的从环形队列中等待和获取数据:
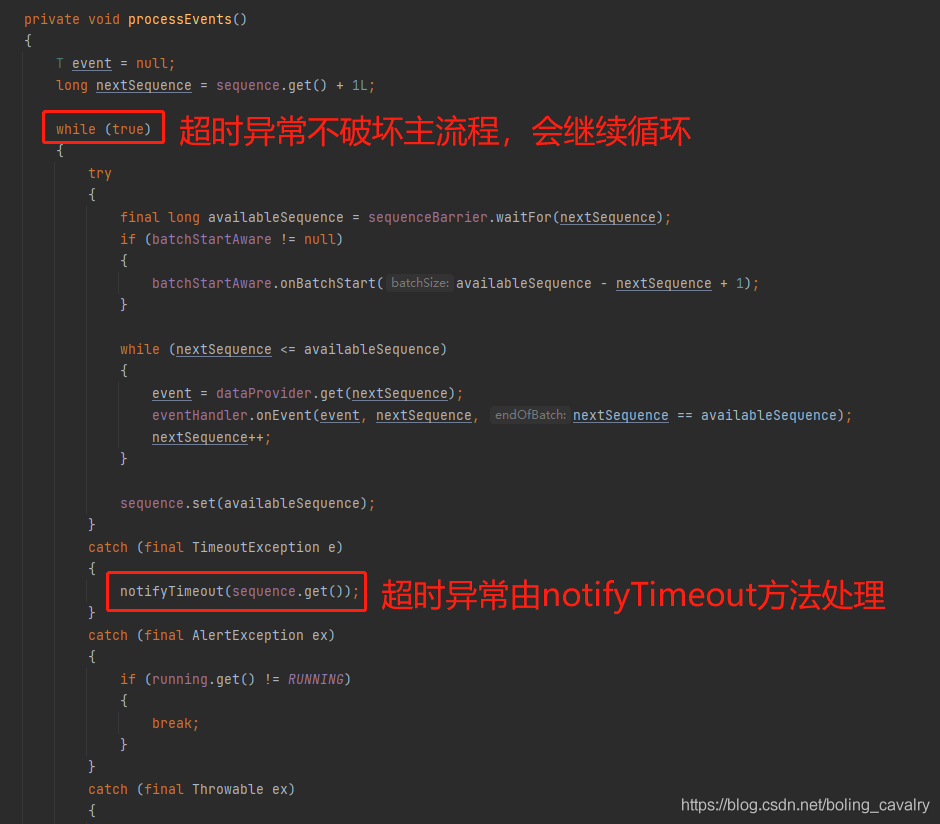
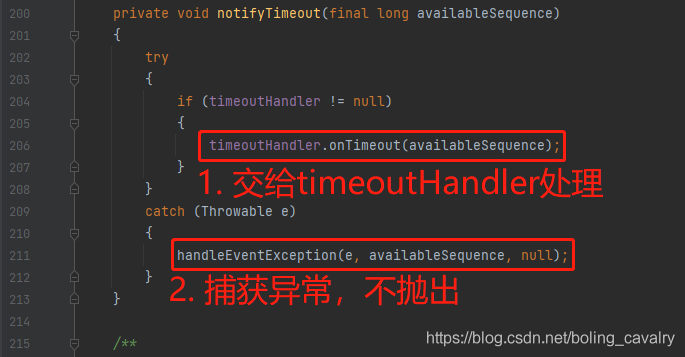
- 进入notifyTImeout方法,可见实际上是交给成员变量timeoutHandler去处理的,而且处理过程中发生的任何异常都会被捕获,不会抛出去影响外部调用:
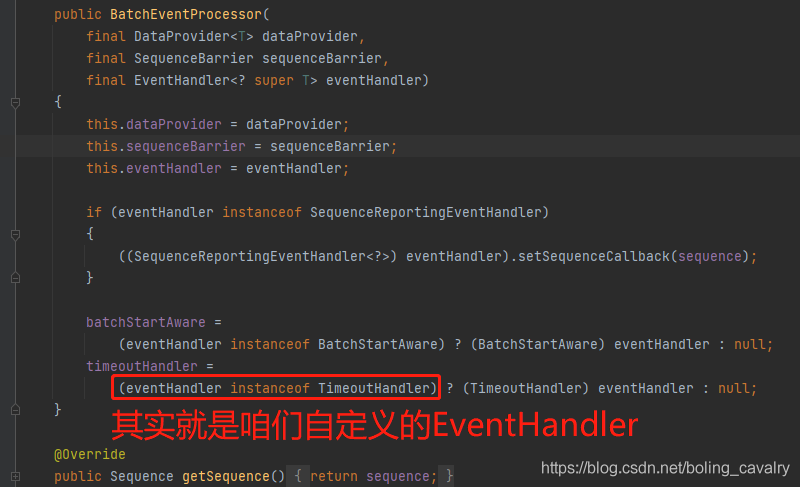
- 再来看看成员变量是哪来的,如下图,真相大白,咱们开发的EventHandler实现类,如果也实现了Timeouthandler,就被当做成员变量timeoutHandler了:
- 至此TimeoutBlockingWaitStrategy也搞清楚了:用于有时间限制的场景,每次等待超时后都会调用业务定制的超时处理逻辑,这个逻辑写到EventHandler实现类中,这个实现类要实现Timeouthandler接口
LiteTimeoutBlockingWaitStrategy
- LiteTimeoutBlockingWaitStrategy与TimeoutBlockingWaitStrategy的关系,就像BlockingWaitStrategy与LiteBlockingWaitStrategy的关系:作为TimeoutBlockingWaitStrategy的变体,有TimeoutBlockingWaitStrategy的超时处理特性,而且没有锁竞争的时候,省略掉唤醒操作;
- 作者说LiteBlockingWaitStrategy可用于体验,但正确性并未经过充分验证,但是在LiteTimeoutBlockingWaitStrategy的注释中没有看到这种说法,看样子这是个靠谱的等待策略,可以用,用在有超时处理的需求,而且没有锁竞争的场景(例如独立消费)
SleepingWaitStrategy
- 和前面几个不同的是,SleepingWaitStrategy没有用到锁,这意味这无需调用signalAllWhenBlocking方法做唤醒处理,相当于省去了生产线程的通知操作,官方源码注释有这么句话引起了我的兴趣,如下图红框,大意是该策略在性能和CPU资源消耗之间取得了平衡,接下来去看看关键代码,来了解这个特性:

- 如下图,等到可用数据的过程是个死循环:
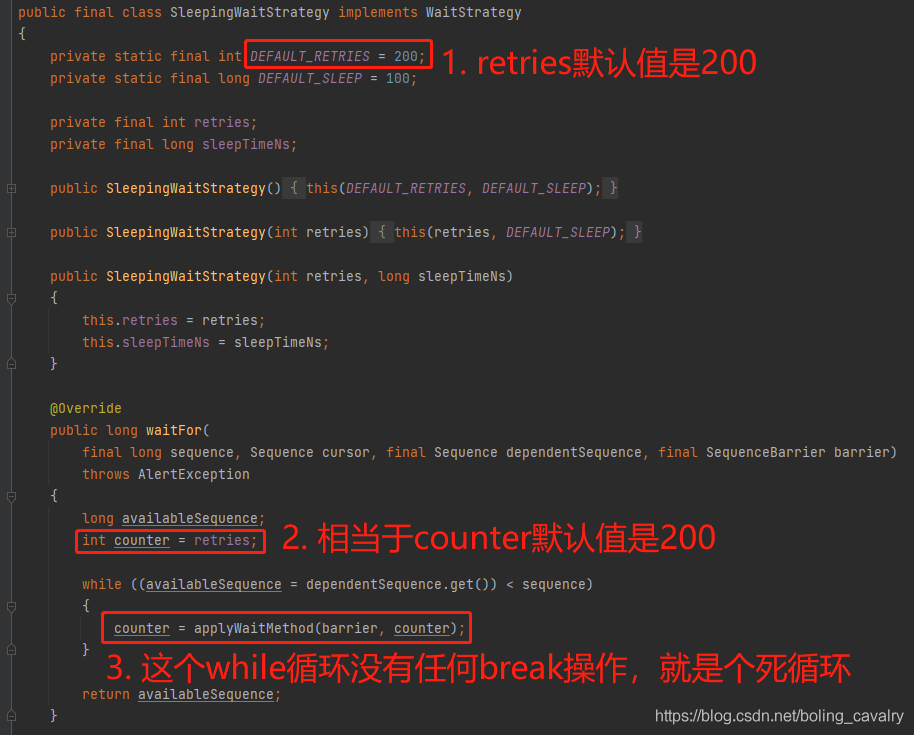
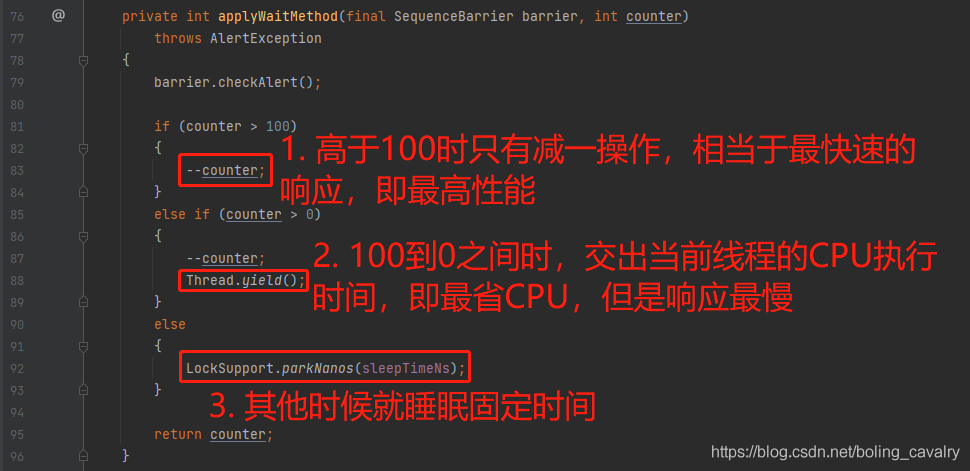
- 接下来是关键代码了,如下图,可见整个等待过程分为三段:计数器高于100时就只有一个减一的操作(最快响应),计数器在100到0之间时每次都交出CPU执行时间(最省资源),其他时候就睡眠固定时间:
YieldingWaitStrategy
- 看过SleepingWaitStrategy之后,再看YieldingWaitStrategy就很容易理解了,和SleepingWaitStrategy相比,YieldingWaitStrategy先做指定次数的自旋,然后不断的交出CPU时间:
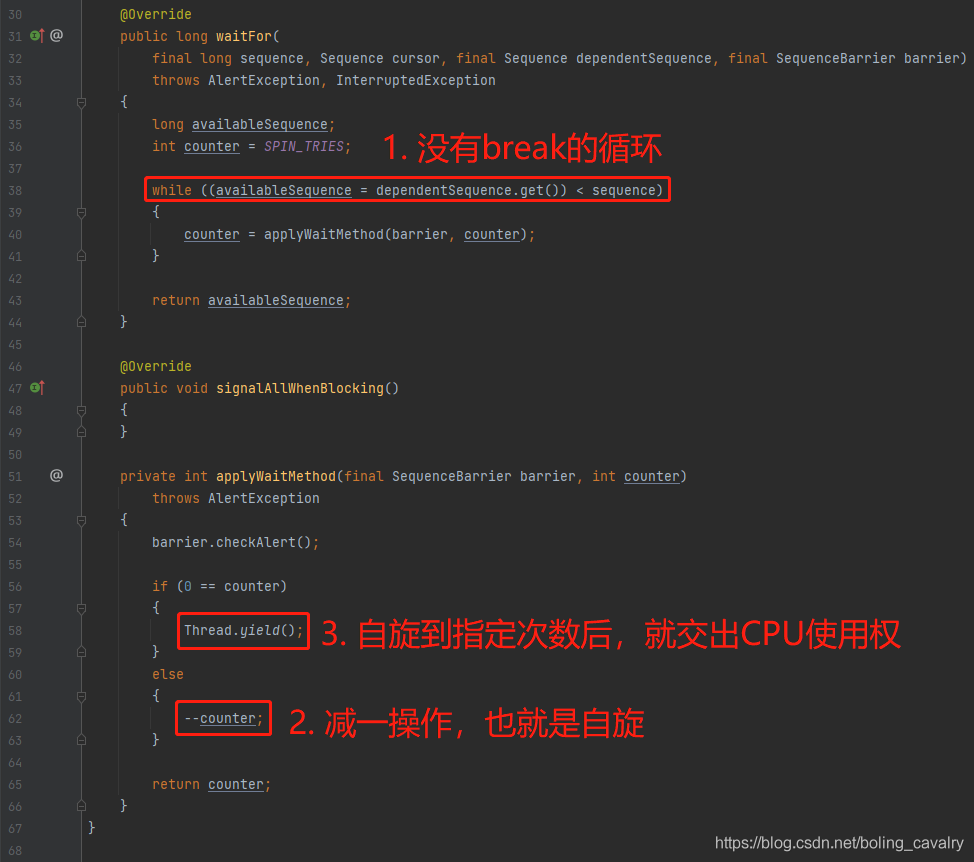
- 由于在不断的执行Thread.yield()方法,因此该策略虽然很消耗CPU,不过一旦其他线程有CPU需求,很容易从这个线程得到;
PhasedBackoffWaitStrategy
- 最后是PhasedBackoffWaitStrategy,该策略的特点是将整个等待过程分成下图的四段,四个方块代表一个时间线上的四个阶段:

- 这里说明一下上图的四个阶段:
- 首先是自旋指定的次数,默认10000次;
- 自旋过后,开始带计时的自旋,执行的时长是spinTimeoutNanos的值;
- 执行时长达到spinTimeoutNanos的值后,开始执行Thread.yield()交出CPU资源,这个逻辑的执行时长是yieldTimeoutNanos-spinTimeoutNanos;
- 执行时长达到yieldTimeoutNanos-spinTimeoutNanos的值后,开始调用fallbackStrategy.waitFor,这个调用没有时间或者次数限制;
- 现在问题来了fallbackStrategy是何方神圣?PhasedBackoffWaitStrategy类准备了三个静态方法,咱们可以按需选用,让fallbackStrategy是BlockingWaitStrategy、LiteBlockingWaitStrategy、SleepingWaitStrategy这三个中的一个:
public static PhasedBackoffWaitStrategy withLock(
long spinTimeout,
long yieldTimeout,
TimeUnit units)
{
return new PhasedBackoffWaitStrategy(
spinTimeout, yieldTimeout,
units, new BlockingWaitStrategy());
}
public static PhasedBackoffWaitStrategy withLiteLock(
long spinTimeout,
long yieldTimeout,
TimeUnit units)
{
return new PhasedBackoffWaitStrategy(
spinTimeout, yieldTimeout,
units, new LiteBlockingWaitStrategy());
}
public static PhasedBackoffWaitStrategy withSleep(
long spinTimeout,
long yieldTimeout,
TimeUnit units)
{
return new PhasedBackoffWaitStrategy(
spinTimeout, yieldTimeout,
units, new SleepingWaitStrategy(0));
}
- 至此,Disruptor的九种等待策略就全部分析完毕了,除了选用等待策略的时候更加得心应手,还有个收获就是积攒了阅读优秀源码的经验,在读源码的路上更加有信心了;
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界…
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中



感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦