
自我介绍(仅供参考)
注意点(克服紧张,语速放慢,目光直视面试官)
面试官下午好,我叫**,今天来应聘贵公司的前端工程师岗位。我从事前端开发两年多,有X年多的Vue开发经验,一年React开发经验,在上家公司主要从事H5页面,后台管理系统,混合App等项目开发。平常喜欢逛一些技术社区丰富自己的技术,像思否,掘金之类,并且自己也独立开发了个人博客网站,记录自己的工作总结和学习心得。 我的性格比较温和,跟同事朋友相处时比较外向,在工作中代码开发时我喜欢全心全意的投入,对于工作我总抱着认真负责的态度。面试官,以上是我的介绍,谢谢。
项目具体介绍
这部分大概率会问,注意语言措辞,做好充足的准备没你就不会慌张,安全感是自己给自己的。 示例:
XXAPP
项目简介:XXAPP是一款多功能的民营银行软件,主要有账户交易、转账汇款、存单产品买入卖出、充值提现等功能,使用原生内嵌webview的方式,通信方面iOS采用messageHandlers[fn].postMessage(data)方法。Android采用window.AndroidWebView[fn] (data)
项目亮点及难点:登录超时重新登录后继续返回原先操作的页面。
xxx银行项目
xxx商城
xxx后台管理系统
xxx
HTML、CSS相关
html5新特性、语义化
语义化标签 : header nav main article section aside footer
语义化意味着顾名思义,HTML5的语义化指的是合理正确的使用语义化的标签来创建页面结构,如 header,footer,nav,从标签上即可以直观的知道这个标签的作用,而不是滥用div。 语义化的优点有: 代码结构清晰,易于阅读,利于开发和维护 方便其他设备解析(如屏幕阅读器)根据语义渲染网页。 有利于搜索引擎优化(SEO),搜索引擎爬虫会根据不同的标签来赋予不同的权重 复制代码
浏览器渲染机制、重绘、重排
网页生成过程:
HTML被HTML解析器解析成DOM树css则被css解析器解析成CSSOM树结合
DOM树和CSSOM树,生成一棵渲染树(Render Tree)生成布局(
flow),即将所有渲染树的所有节点进行平面合成将布局绘制(
paint)在屏幕上
重排(也称回流): 当DOM的变化影响了元素的几何信息(DOM对象的位置和尺寸大小),浏览器需要重新计算元素的几何属性,将其安放在界面中的正确位置,这个过程叫做重排。 触发:
添加或者删除可见的DOM元素
元素尺寸改变——边距、填充、边框、宽度和高度
重绘: 当一个元素的外观发生改变,但没有改变布局,重新把元素外观绘制出来的过程,叫做重绘。 触发:
改变元素的
color、background、box-shadow等属性
重排优化建议:
分离读写操作
样式集中修改
缓存需要修改的
DOM元素尽量只修改
position:absolute或fixed元素,对其他元素影响不大动画开始
GPU加速,translate使用3D变化
transform 不重绘,不回流 是因为transform属于合成属性,对合成属性进行transition/animate动画时,将会创建一个合成层。这使得动画元素在一个独立的层中进行渲染。当元素的内容没有发生改变,就没有必要进行重绘。浏览器会通过重新复合来创建动画帧。
css盒子模型
所有HTML元素可以看作盒子,在CSS中,"box model"这一术语是用来设计和布局时使用。 CSS盒模型本质上是一个盒子,封装周围的HTML元素,它包括:边距,边框,填充,和实际内容。 盒模型允许我们在其它元素和周围元素边框之间的空间放置元素。
css样式优先级
!important>style>id>class
什么是BFC?BFC的布局规则是什么?如何创建BFC?BFC应用?
BFC 是 Block Formatting Context 的缩写,即块格式化上下文。BFC是CSS布局的一个概念,是一个环境,里面的元素不会影响外面的元素。 布局规则:Box是CSS布局的对象和基本单位,页面是由若干个Box组成的。元素的类型和display属性,决定了这个Box的类型。不同类型的Box会参与不同的Formatting Context。 创建:浮动元素 display:inline-block position:absolute 应用: 1.分属于不同的BFC时,可以防止margin重叠 2.清除内部浮动 3.自适应多栏布局
DOM、BOM对象
BOM(Browser Object Model)是指浏览器对象模型,可以对浏览器窗口进行访问和操作。使用 BOM,开发者可以移动窗口、改变状态栏中的文本以及执行其他与页面内容不直接相关的动作。 使 JavaScript 有能力与浏览器"对话"。 DOM (Document Object Model)是指文档对象模型,通过它,可以访问HTML文档的所有元素。 DOM 是 W3C(万维网联盟)的标准。DOM 定义了访问 HTML 和 XML 文档的标准: "W3C 文档对象模型(DOM)是中立于平台和语言的接口,它允许程序和脚本动态地访问和更新文档的内容、结构和样式。" W3C DOM 标准被分为 3 个不同的部分:
核心
DOM- 针对任何结构化文档的标准模型XML DOM- 针对 XML 文档的标准模型HTML DOM- 针对 HTML 文档的标准模型
什么是 XML DOM? XML DOM 定义了所有 XML 元素的对象和属性,以及访问它们的方法。 什么是 HTML DOM? HTML DOM 定义了所有 HTML 元素的对象和属性,以及访问它们的方法。
JS相关
js数据类型、typeof、instanceof、类型转换
string、number、boolean、null、undefined、object(function、array)、symbol(ES10 BigInt)typeof主要用来判断数据类型 返回值有string、boolean、number、function、object、undefined。instanceof判断该对象是谁的实例。null表示空对象undefined表示已在作用域中声明但未赋值的变量
闭包(高频)
闭包是指有权访问另一个函数作用域中的变量的函数 ——《JavaScript高级程序设计》
当函数可以记住并访问所在的词法作用域时,就产生了闭包,
即使函数是在当前词法作用域之外执行 ——《你不知道的JavaScript》
闭包用途:
能够访问函数定义时所在的词法作用域(阻止其被回收)
私有化变量
模拟块级作用域
创建模块
闭包缺点:会导致函数的变量一直保存在内存中,过多的闭包可能会导致内存泄漏
原型、原型链(高频)
原型: 对象中固有的__proto__属性,该属性指向对象的prototype原型属性。
原型链: 当我们访问一个对象的属性时,如果这个对象内部不存在这个属性,那么它就会去它的原型对象里找这个属性,这个原型对象又会有自己的原型,于是就这样一直找下去,也就是原型链的概念。原型链的尽头一般来说都是Object.prototype所以这就是我们新建的对象为什么能够使用toString()等方法的原因。
特点: JavaScript对象是通过引用来传递的,我们创建的每个新对象实体中并没有一份属于自己的原型副本。当我们修改原型时,与之相关的对象也会继承这一改变。
this指向、new关键字
this对象是是执行上下文中的一个属性,它指向最后一次调用这个方法的对象,在全局函数中,this等于window,而当函数被作为某个对象调用时,this等于那个对象。 在实际开发中,this 的指向可以通过四种调用模式来判断。
函数调用,当一个函数不是一个对象的属性时,直接作为函数来调用时,
this指向全局对象。方法调用,如果一个函数作为一个对象的方法来调用时,
this指向这个对象。构造函数调用,
this指向这个用new新创建的对象。第四种是
apply 、 call 和 bind调用模式,这三个方法都可以显示的指定调用函数的 this 指向。apply接收参数的是数组,call接受参数列表,`` bind方法通过传入一个对象,返回一个this绑定了传入对象的新函数。这个函数的this指向除了使用new `时会被改变,其他情况下都不会改变。
new
首先创建了一个新的空对象
设置原型,将对象的原型设置为函数的
prototype对象。让函数的
this指向这个对象,执行构造函数的代码(为这个新对象添加属性)判断函数的返回值类型,如果是值类型,返回创建的对象。如果是引用类型,就返回这个引用类型的对象。
作用域、作用域链、变量提升
作用域负责收集和维护由所有声明的标识符(变量)组成的一系列查询,并实施一套非常严格的规则,确定当前执行的代码对这些标识符的访问权限。(全局作用域、函数作用域、块级作用域)。 作用域链就是从当前作用域开始一层一层向上寻找某个变量,直到找到全局作用域还是没找到,就宣布放弃。这种一层一层的关系,就是作用域链。
继承(含es6)、多种继承方式
(1)第一种是以原型链的方式来实现继承,但是这种实现方式存在的缺点是,在包含有引用类型的数据时,会被所有的实例对象所共享,容易造成修改的混乱。还有就是在创建子类型的时候不能向超类型传递参数。
(2)第二种方式是使用借用构造函数的方式,这种方式是通过在子类型的函数中调用超类型的构造函数来实现的,这一种方法解决了不能向超类型传递参数的缺点,但是它存在的一个问题就是无法实现函数方法的复用,并且超类型原型定义的方法子类型也没有办法访问到。
(3)第三种方式是组合继承,组合继承是将原型链和借用构造函数组合起来使用的一种方式。通过借用构造函数的方式来实现类型的属性的继承,通过将子类型的原型设置为超类型的实例来实现方法的继承。这种方式解决了上面的两种模式单独使用时的问题,但是由于我们是以超类型的实例来作为子类型的原型,所以调用了两次超类的构造函数,造成了子类型的原型中多了很多不必要的属性。
(4)第四种方式是原型式继承,原型式继承的主要思路就是基于已有的对象来创建新的对象,实现的原理是,向函数中传入一个对象,然后返回一个以这个对象为原型的对象。这种继承的思路主要不是为了实现创造一种新的类型,只是对某个对象实现一种简单继承,ES5 中定义的 Object.create() 方法就是原型式继承的实现。缺点与原型链方式相同。
(5)第五种方式是寄生式继承,寄生式继承的思路是创建一个用于封装继承过程的函数,通过传入一个对象,然后复制一个对象的副本,然后对象进行扩展,最后返回这个对象。这个扩展的过程就可以理解是一种继承。这种继承的优点就是对一个简单对象实现继承,如果这个对象不是我们的自定义类型时。缺点是没有办法实现函数的复用。
(6)第六种方式是寄生式组合继承,组合继承的缺点就是使用超类型的实例做为子类型的原型,导致添加了不必要的原型属性。寄生式组合继承的方式是使用超类型的原型的副本来作为子类型的原型,这样就避免了创建不必要的属性。
EventLoop
JS是单线程的,为了防止一个函数执行时间过长阻塞后面的代码,所以会先将同步代码压入执行栈中,依次执行,将异步代码推入异步队列,异步队列又分为宏任务队列和微任务队列,因为宏任务队列的执行时间较长,所以微任务队列要优先于宏任务队列。微任务队列的代表就是,Promise.then,MutationObserver,宏任务的话就是setImmediate setTimeout setInterval
原生ajax
ajax是一种异步通信的方法,从服务端获取数据,达到局部刷新页面的效果。 过程:
创建
XMLHttpRequest对象;调用
open方法传入三个参数 请求方式(GET/POST)、url、同步异步(true/false);监听
onreadystatechange事件,当readystate等于4时返回responseText;调用send方法传递参数。
事件冒泡、捕获(委托)
事件冒泡指在在一个对象上触发某类事件,如果此对象绑定了事件,就会触发事件,如果没有,就会向这个对象的父级对象传播,最终父级对象触发了事件。
事件委托本质上是利用了浏览器事件冒泡的机制。因为事件在冒泡过程中会上传到父节点,并且父节点可以通过事件对象获取到目标节点,因此可以把子节点的监听函数定义在父节点上,由父节点的监听函数统一处理多个子元素的事件,这种方式称为事件代理。
event.stopPropagation() 或者 ie下的方法 event.cancelBubble = true; //阻止事件冒泡
ES6
新增symbol类型 表示独一无二的值,用来定义独一无二的对象属性名;
const/let 都是用来声明变量,不可重复声明,具有块级作用域。存在暂时性死区,也就是不存在变量提升。(const一般用于声明常量);
变量的解构赋值(包含数组、对象、字符串、数字及布尔值,函数参数),剩余运算符(...rest);
模板字符串(
${data});扩展运算符(数组、对象);;
箭头函数;
Set和Map数据结构;
Proxy/Reflect;
Promise;
async函数;
Class;
Module语法(import/export)。
Vue
简述MVVM
MVVM是Model-View-ViewModel缩写,也就是把MVC中的Controller演变成ViewModel。Model层代表数据模型,View代表UI组件,ViewModel是View和Model层的桥梁,数据会绑定到viewModel层并自动将数据渲染到页面中,视图变化的时候会通知viewModel层更新数据。
谈谈对vue生命周期的理解?
每个Vue实例在创建时都会经过一系列的初始化过程,vue的生命周期钩子,就是说在达到某一阶段或条件时去触发的函数,目的就是为了完成一些动作或者事件
create阶段:vue实例被创建beforeCreate: 创建前,此时data和methods中的数据都还没有初始化created: 创建完毕,data中有值,未挂载mount阶段: vue实例被挂载到真实DOM节点beforeMount:可以发起服务端请求,去数据mounted: 此时可以操作Domupdate阶段:当vue实例里面的data数据变化时,触发组件的重新渲染beforeUpdateupdateddestroy阶段:vue实例被销毁beforeDestroy:实例被销毁前,此时可以手动销毁一些方法destroyed
computed与watch
watch 属性监听 是一个对象,键是需要观察的属性,值是对应回调函数,主要用来监听某些特定数据的变化,从而进行某些具体的业务逻辑操作,监听属性的变化,需要在数据变化时执行异步或开销较大的操作时使用
computed 计算属性 属性的结果会被缓存,当computed中的函数所依赖的属性没有发生改变的时候,那么调用当前函数的时候结果会从缓存中读取。除非依赖的响应式属性变化时才会重新计算,主要当做属性来使用 computed中的函数必须用return返回最终的结果 computed更高效,优先使用
使用场景 computed:当一个属性受多个属性影响的时候使用,例:购物车商品结算功能 watch:当一条数据影响多条数据的时候使用,例:搜索数据
v-for中key的作用
key的作用主要是为了更高效的对比虚拟DOM中每个节点是否是相同节点;Vue在patch过程中判断两个节点是否是相同节点,key是一个必要条件,渲染一组列表时,key往往是唯一标识,所以如果不定义key的话,Vue只能认为比较的两个节点是同一个,哪怕它们实际上不是,这导致了频繁更新元素,使得整个patch过程比较低效,影响性能;从源码中可以知道,Vue判断两个节点是否相同时主要判断两者的key和元素类型等,因此如果不设置key,它的值就是
undefined,则可能永 远认为这是两个相同的节点,只能去做更新操作,这造成了大量的dom更新操作,明显是不可取的。
vue组件的通信方式
父子组件通信
父->子props,子->父 $on、$emit` 获取父子组件实例 parent、parent、parent、children Ref 获取实例的方式调用组件的属性或者方法 Provide、inject` 官方不推荐使用,但是写组件库时很常用
兄弟组件通信
Event Bus 实现跨组件通信 Vue.prototype.$bus = new Vue() Vuex
跨级组件通信
$attrs、$listeners Provide、inject
常用指令
v-if:判断是否隐藏;
v-for:数据循环出来;
v-bind:class:绑定一个属性;
v-model:实现双向绑定
双向绑定实现原理
当一个Vue实例创建时,Vue会遍历data选项的属性,用 Object.defineProperty 将它们转为 getter/setter并且在内部追踪相关依赖,在属性被访问和修改时通知变化。每个组件实例都有相应的 watcher 程序实例,它会在组件渲染的过程中把属性记录为依赖,之后当依赖项的 setter 被调用时,会通知 watcher重新计算,从而致使它关联的组件得以更新。
v-model的实现以及它的实现原理吗?
vue中双向绑定是一个指令v-model,可以绑定一个动态值到视图,同时视图中变化能改变该值。v-model是语法糖,默认情况下相于:value和@input。使用
v-model可以减少大量繁琐的事件处理代码,提高开发效率,代码可读性也更好通常在表单项上使用
v-model原生的表单项可以直接使用
v-model,自定义组件上如果要使用它需要在组件内绑定value并处理输入事件我做过测试,输出包含
v-model模板的组件渲染函数,发现它会被转换为value属性的绑定以及一个事件监听,事件回调函数中会做相应变量更新操作,这说明神奇魔法实际上是vue的编译器完成的。
nextTick的实现
nextTick是Vue提供的一个全局API,是在下次DOM更新循环结束之后执行延迟回调,在修改数据之后使用$nextTick,则可以在回调中获取更新后的DOM;Vue在更新DOM时是异步执行的。只要侦听到数据变化,
Vue将开启1个队列,并缓冲在同一事件循环中发生的所有数据变更。如果同一个watcher被多次触发,只会被推入到队列中-次。这种在缓冲时去除重复数据对于避免不必要的计算和DOM操作是非常重要的。nextTick方法会在队列中加入一个回调函数,确保该函数在前面的dom操作完成后才调用;比如,我在干什么的时候就会使用nextTick,传一个回调函数进去,在里面执行dom操作即可;
我也有简单了解
nextTick实现,它会在callbacks里面加入我们传入的函数,然后用timerFunc异步方式调用它们,首选的异步方式会是Promise。这让我明白了为什么可以在nextTick中看到dom操作结果。
vnode的理解,compiler和patch的过程
vnode 虚拟DOM节点 创建:
export function Vnode (){
return {
tag:'div',
children: 'span',
attr:'',
text:'你好!'
}
}
new Vue后整个的流程
initProxy:作用域代理,拦截组件内访问其它组件的数据。initLifecycle:建立父子组件关系,在当前组件实例上添加一些属性和生命周期标识。如[Math Processing Error]parent,parent,refs,$children,_isMounted等。initEvents:对父组件传入的事件添加监听,事件是谁创建谁监听,子组件创建事件子组件监听initRender:声明[Math Processing Error]slots和slots和createElement()等。initInjections:注入数据,初始化inject,一般用于组件更深层次之间的通信。initState:重要)数据响应式:初始化状态。很多选项初始化的汇总:data,methods,props,computed和watch。initProvide:提供数据注入。
思考:为什么先注入再提供呢??
答:1、首先来自祖辈的数据要和当前实例的data,等判重,相结合,所以注入数据的initInjections一定要在InitState的上面。2. 从上面注入进来的东西在当前组件中转了一下又提供给后代了,所以注入数据也一定要在上面。
vm.[Math Processing Error]mount(vm.mount(vm.options.el):挂载实例。
keep-alive的实现
作用:实现组件缓存
钩子函数:
`activated `组件渲染后调用 `deactivated `组件销毁后调用
原理:Vue.js内部将DOM节点抽象成了一个个的VNode节点,keep-alive组件的缓存也是基于VNode节点的而不是直接存储DOM结构。它将满足条件(pruneCache与pruneCache)的组件在cache对象中缓存起来,在需要重新渲染的时候再将vnode节点从cache对象中取出并渲染。
配置属性:
include 字符串或正则表达式。只有名称匹配的组件会被缓存
exclude 字符串或正则表达式。任何名称匹配的组件都不会被缓存
max 数字、最多可以缓存多少组件实例
vuex、vue-router实现原理
vuex是一个专门为vue.js应用程序开发的状态管理库。
核心概念:
state(单一状态树)getter/Mutation显示提交更改stateAction类似Mutation,提交Mutation,可以包含任意异步操作。module(当应用变得庞大复杂,拆分store为具体的module模块)
你怎么理解Vue中的diff算法?
在js中,渲染真实DOM的开销是非常大的, 比如我们修改了某个数据,如果直接渲染到真实DOM, 会引起整个dom树的重绘和重排。那么有没有可能实现只更新我们修改的那一小块dom而不要更新整个dom呢?此时我们就需要先根据真实dom生成虚拟dom, 当虚拟dom某个节点的数据改变后会生成有一个新的Vnode, 然后新的Vnode和旧的Vnode作比较,发现有不一样的地方就直接修改在真实DOM上,然后使旧的Vnode的值为新的Vnode。
diff的过程就是调用patch函数,比较新旧节点,一边比较一边给真实的DOM打补丁。在采取diff算法比较新旧节点的时候,比较只会在同层级进行。
在patch方法中,首先进行树级别的比较new Vnode不存在就删除 old Vnodeold Vnode 不存在就增加新的Vnode都存在就执行diff更新
当确定需要执行diff算法时,比较两个Vnode,包括三种类型操作:属性更新,文本更新,子节点更新
新老节点均有子节点,则对子节点进行diff操作,调用updatechidren如果老节点没有子节点而新节点有子节点,先清空老节点的文本内容,然后为其新增子节点
如果新节点没有子节点,而老节点有子节点的时候,则移除该节点的所有子节点
老新老节点都没有子节点的时候,进行文本的替换
updateChildren将Vnode的子节点Vch和oldVnode的子节点oldCh提取出来。oldCh和vCh各有两个头尾的变量StartIdx和EndIdx,它们的2个变量相互比较,一共有4种比较方式。如果4种比较都没匹配,如果设置了key,就会用key进行比较,在比较的过程中,变量会往中间靠,一旦StartIdx>EndIdx表明oldCh和vCh至少有一个已经遍历完了,就会结束比较。
你都做过哪些Vue的性能优化?
编码阶段
尽量减少data中的数据,data中的数据都会增加getter和setter,会收集对应的watcher
v-if和v-for不能连用
如果需要使用v-for给每项元素绑定事件时使用事件代理
SPA 页面采用keep-alive缓存组件
在更多的情况下,使用v-if替代v-show
key保证唯一
使用路由懒加载、异步组件
防抖、节流
第三方模块按需导入
长列表滚动到可视区域动态加载
图片懒加载
SEO优化
预渲染
服务端渲染SSR
打包优化
压缩代码
Tree Shaking/Scope Hoisting
使用cdn加载第三方模块
多线程打包happypack
splitChunks抽离公共文件
sourceMap优化
用户体验
骨架屏
PWA
还可以使用缓存(客户端缓存、服务端缓存)优化、服务端开启gzip压缩等。
你知道Vue3有哪些新特性吗?它们会带来什么影响?
性能提升
更小巧、更快速 支持自定义渲染器 支持摇树优化:一种在打包时去除无用代码的优化手段 支持Fragments和跨组件渲染
API变动
模板语法99%保持不变 原生支持基于class的组件,并且无需借助任何编译及各种stage阶段的特性 在设计时也考虑TypeScript的类型推断特性 重写虚拟DOM可以期待更多的编译时提示来减少运行时的开销 优化插槽生成可以单独渲染父组件和子组件 静态树提升降低渲染成本 基于Proxy的观察者机制节省内存开销
不兼容IE11
检测机制更加全面、精准、高效,更具可调试式的响应跟踪
实现双向绑定 Proxy 与 Object.defineProperty 相比优劣如何?
Object.definedProperty的作用是劫持一个对象的属性,劫持属性的getter和setter方法,在对象的属性发生变化时进行特定的操作。而 Proxy劫持的是整个对象。
Proxy会返回一个代理对象,我们只需要操作新对象即可,而Object.defineProperty只能遍历对象属性直接修改。
Object.definedProperty不支持数组,更准确的说是不支持数组的各种API,因为如果仅仅考虑arry[i] = value 这种情况,是可以劫持 的,但是这种劫持意义不大。而Proxy可以支持数组的各种API。
尽管Object.defineProperty有诸多缺陷,但是其兼容性要好于Proxy。
React
1、react中key的作用,有key没key有什么区别,比较同一层级节点什么意思?
Keys是React用于追踪哪些列表中元素被修改、被添加或者被移除的辅助标识。 复制代码
2、你对虚拟dom和diff算法的理解,实现render函数
虚拟DOM本质上是JavaScript对象,是对真实DOM的抽象表现。 状态变更时,记录新树和旧树的差异 最后把差异更新到真正的dom中 render函数:
根据
tagName生成父标签,读取props,设置属性,如果有content,设置innerHtml或innerText,如果存在子元素,遍历子元素递归调用
render方法,将生成的子元素依次添加到父元素中,并返回根元素。
3、React组件之间通信方式?
父子组件,父->子直接用
Props,子->父用callback回调非父子组件,用发布订阅模式的
Event模块项目复杂的话用
Redux、Mobx等全局状态管理管库Context Api context会使组件复用性变差
Context 提供了一个无需为每层组件手动添加 props,就能在组件树间进行数据传递的方法.如果你只是想避免层层传递一些属性,组件组合(component composition)有时候是一个比 context 更好的解决方案。 5. 组件组合缺点:会使高层组件变得复杂
4、如何解析jsx
调用React.createElement函数创建对象 复制代码
5、生命周期都有哪几种,分别是在什么阶段做哪些事情?为什么要废弃一些生命周期?
componentWillMount、componentWillReceiveProps、componentWillUpdate在16版本被废弃,在17版本将被删除,需要使用UNSAVE_前缀使用,目的是向下兼容。
6、关于react的优化方法
代码层面:
使用return null而不是CSS的display:none来控制节点的显示隐藏。保证同一时间页面的DOM节点尽可能的少。
props和state的数据尽可能简单明了,扁平化。
不要使用数组下标作为key 利用 shouldComponentUpdate 和 PureComponent 避免过多 render function; render里面尽量减少新建变量和bind函数,传递参数是尽量减少传递参数的数量。 尽量将 props 和 state 扁平化,只传递 component 需要的 props(传得太多,或者层次传得太深,都会加重shouldComponentUpdate里面的数据比较负担),慎将 component 当作 props 传入
代码体积:
使用 babel-plugin-import 优化业务组件的引入,实现按需加载 使用 SplitChunksPlugin 拆分公共代码 使用动态 import,懒加载 React 组件
7、绑定this的几种方式
bind/箭头函数 复制代码
8、对fiber的理解
React Fiber 是一种基于浏览器的单线程调度算法. 复制代码
9、setState是同步还是异步的
setState只在合成事件和钩子函数中是“异步”的,在原生事件和 setTimeout 中都是同步的。setState的“异步”并不是说内部由异步代码实现,其实本身执行的过程和代码都是同步的,只是合成事件和钩子函数的调用顺序在更新之前,导致在合成事件和钩子函数中没法立马拿到更新后的值,形式了所谓的“异步”,当然可以通过第二个参数 setState(partialState, callback) 中的callback拿到更新后的结果。setState的批量更新优化也是建立在“异步”(合成事件、钩子函数)之上的,在原生事件和setTimeout 中不会批量更新,在“异步”中如果对同一个值进行多次 setState , setState 的批量更新策略会对其进行覆盖,取最后一次的执行,如果是同时 setState 多个不同的值,在更新时会对其进行合并批量更新。
10、Redux、React-Redux
Redux的实现流程
用户页面行为触发一个Action,然后Store调用Reducer,并且传入两个参数:当前State和收到的Action。Reducer会返回新的State。每当state更新之后,view会根据state触发重新渲染。
React-Redux:
Provider:从最外部封装了整个应用,并向connect模块传递store。 Connect:
包装原组件,将
state和action通过props的方式传入到原组件内部。监听
store tree变化,使其包装的原组件可以响应state变化
11、对高阶组件的理解
高阶组件是参数为组件,返回值为新组件的函数。HOC是纯函数,没有副作用。HOC在React的第三方库中很常见,例如Redux的connect组件。
高阶组件的作用:
代码复用,逻辑抽象,抽离底层准备(
bootstrap)代码渲染劫持
State抽象和更改Props更改
12、可以用哪些方式创建React组件?
React.createClass()、ES6 class和无状态函数
13、React元素与组件的区别?
组件是由元素构成的。元素数据结构是普通对象,而组件数据结构是类或纯函数。
Vue与React对比?
数据流:
react主张函数式编程,所以推崇纯组件,数据不可变,单向数据流,
vue的思想是响应式的,也就是基于是数据可变的,通过对每一个属性建立Watcher来监听,当属性变化的时候,响应式的更新对应的虚拟dom。
监听数据变化实现原理:
Vue通过getter/setter以及一些函数的劫持,能精确知道数据变化,不需要特别的优化就能达到很好的性能React默认是通过比较引用的方式进行的,如果不优化(PureComponent/shouldComponentUpdate)可能导致大量不必要的VDOM的重新渲染。
组件通信的区别:jsx和.vue模板。
HoC和Mixins(在Vue中我们组合不同功能的方式是通过Mixin,而在React中我们通过HoC(高阶组件))。
性能优化
React: shouldComponentUpdateVue:内部实现shouldComponentUpdate的优化,由于依赖追踪系统存在,通过watcher判断是否需要重新渲染(当一个页面数据量较大时,Vue的性能较差,造成页面卡顿,所以一般数据比较大的项目倾向使用React)。
vuex 和 redux 之间的区别?
从实现原理上来说,最大的区别是两点:
Redux使用的是不可变数据,而Vuex的数据是可变的。Redux每次都是用新的state替换旧的state,而Vuex是直接修改
Redux在检测数据变化的时候,是通过diff的方式比较差异的,而Vuex其实和Vue的原理一样,是通过 getter/setter来比较的(如果看Vuex源码会知道,其实他内部直接创建一个Vue实例用来跟踪数据变化)
浏览器从输入url到渲染页面,发生了什么?
三个方面:
网络篇:
构建请求
查找强缓存
DNS解析
建立TCP连接(三次握手)
发送HTTP请求(网络请求后网络响应)
浏览器解析篇:
解析html构建DOM树
解析css构建CSS树、样式计算
生成布局树(Layout Tree)
浏览器渲染篇:
建立图层树(Layer Tree)
生成绘制列表
生成图块并栅格化
显示器显示内容
最后断开连接:TCP 四次挥手
(浏览器会将各层的信息发送给GPU,GPU会将各层合成,显示在屏幕上)
网络安全、HTTP协议
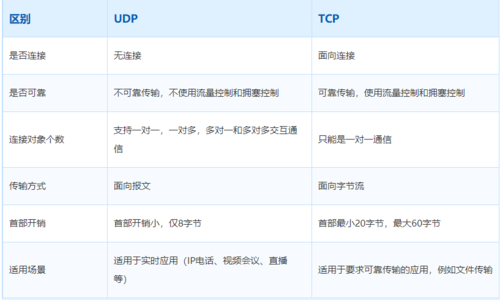
TCP UDP 区别
1.`TCP`向上层提供面向连接的可靠服务 ,`UDP`向上层提供无连接不可靠服务。 2.虽然 `UDP` 并没有 `TCP` 传输来的准确,但是也能在很多实时性要求高的地方有所作为 3.对数据准确性要求高,速度可以相对较慢的,可以选用`TCP`
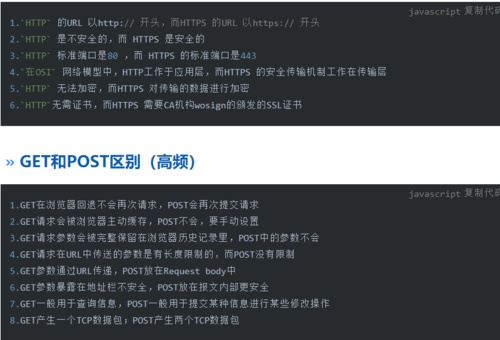
Http和Https区别(高频)
理解xss,csrf,ddos攻击原理以及避免方式
XSS(Cross-Site Scripting,跨站脚本攻击)是一种代码注入攻击。攻击者在目标网站上注入恶意代码,当被攻击者登陆网站时就会执行这些恶意代码,这些脚本可以读取 cookie,session tokens,或者其它敏感的网站信息,对用户进行钓鱼欺诈,甚至发起蠕虫攻击等。
CSRF(Cross-site request forgery)跨站请求伪造:攻击者诱导受害者进入第三方网站,在第三方网站中,向被攻击网站发送跨站请求。利用受害者在被攻击网站已经获取的注册凭证,绕过后台的用户验证,达到冒充用户对被攻击的网站执行某项操作的目的。
XSS避免方式:
url参数使用encodeURIComponent方法转义尽量不是有
InnerHtml插入HTML内容使用特殊符号、标签转义符。
CSRF避免方式:
添加验证码
使用token
服务端给用户生成一个token,加密后传递给用户
用户在提交请求时,需要携带这个token
服务端验证token是否正确
DDoS又叫分布式拒绝服务,全称 Distributed Denial of Service,其原理就是利用大量的请求造成资源过载,导致服务不可用。
DDos避免方式:
限制单IP请求频率。
防火墙等防护设置禁止
ICMP包等检查特权端口的开放
http特性以及状态码

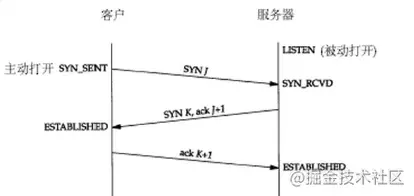
http三次握手
第一步:客户端发送SYN报文到服务端发起握手,发送完之后客户端处于SYN_Send状态
第二步:服务端收到SYN报文之后回复SYN和ACK报文给客户端
第三步:客户端收到SYN和ACK,向服务端发送一个ACK报文,客户端转为established状态,此时服务端收到ACK报文后也处于established状态,此时双方已建立了连接
http四次挥手
刚开始双方都处于 establised 状态,假如是客户端先发起关闭请求,则:
第一次挥手:客户端发送一个 FIN 报文,报文中会指定一个序列号。此时客户端处于FIN_WAIT1状态。
第二次挥手:服务端收到 FIN 之后,会发送 ACK 报文,且把客户端的序列号值 + 1 作为 ACK 报文的序列号值,表明已经收到客户端的报文了,此时服务端处于 CLOSE_WAIT状态。
第三次挥手:如果服务端也想断开连接了,和客户端的第一次挥手一样,发给 FIN 报文,且指定一个序列号。此时服务端处于 LAST_ACK 的状态。
第四次挥手:客户端收到 FIN 之后,一样发送一个 ACK 报文作为应答,且把服务端的序列号值 + 1 作为自己 ACK 报文的序列号值,此时客户端处于 TIME_WAIT 状态。需要过一阵子以确保服务端收到自己的 ACK 报文之后才会进入 CLOSED 状态
服务端收到 ACK 报文之后,就处于关闭连接了,处于 CLOSED 状态。
http1.0、http1.1、http2.0的区别
1和1.0相比,1.1可以一次传输多个文件
http1.x解析基于文本,http2.0采用二进制格式,新增特性 多路复用、header压缩、服务端推送(静态html资源)
http如何实现缓存
强缓存==>Expires(过期时间)/Cache-Control(no-cache)(优先级高) 协商缓存 ==>Last-Modified/Etag(优先级高)Etag适用于经常改变的小文件 Last-Modefied适用于不怎么经常改变的大文件
强缓存策略和协商缓存策略在缓存命中时都会直接使用本地的缓存副本,区别只在于协商缓存会向服务器发送一次请求。它们缓存不命中时,都会向服务器发送请求来获取资源。在实际的缓存机制中,强缓存策略和协商缓存策略是一起合作使用的。浏览器首先会根据请求的信息判断,强缓存是否命中,如果命中则直接使用资源。如果不命中则根据头信息向服务器发起请求,使用协商缓存,如果协商缓存命中的话,则服务器不返回资源,浏览器直接使用本地资源的副本,如果协商缓存不命中,则浏览器返回最新的资源给浏览器。
输入url后http请求的完整过程
建立TCP连接->发送请求行->发送请求头->(到达服务器)发送状态行->发送响应头->发送响应数据->断TCP连接
前端性能优化
前端性能优化的几种方式

什么是同源策略
一个域下的js脚本未经允许的情况下,不能访问另一个域下的内容。通常判断跨域的依据是协议、域名、端口号是否相同,不同则跨域。同源策略是对js脚本的一种限制,并不是对浏览器的限制,像img,script脚本请求不会有跨域限制。
前后端如何通信
Ajax : 短连接 Websocket : 长连接,双向的。 Form表单(最原始的)
跨域通信的几种方式
解决方案:
jsonp(利用script标签没有跨域限制的漏洞实现。缺点:只支持GET请求)CORS(设置Access-Control-Allow-Origin:指定可访问资源的域名)postMessage(message, targetOrigin, [transfer])(HTML5新增API 用于多窗口消息、页面内嵌iframe消息传递),通过onmessage监听 传递过来的数据Websocket是HTML5的一个持久化的协议,它实现了浏览器与服务器的全双工通信,同时也是跨域的一种解决方案。Node中间件代理Nginx反向代理各种嵌套
iframe的方式,不常用。日常工作中用的最对的跨域方案是CORS和Nginx反向代理
能不能说一说浏览器的本地存储?各自优劣如何?
浏览器的本地存储主要分为Cookie、WebStorage和IndexDB, 其中WebStorage又可以分为localStorage和sessionStorage。
共同点: 都是保存在浏览器端、且同源的
不同点:
cookie数据始终在同源的http请求中携带(即使不需要),即cookie在浏览器和服务器间来回传递。cookie数据还有路径(path)的概念,可以限制cookie只属于某个路径下sessionStorage和localStorage不会自动把数据发送给服务器,仅在本地保存。存储大小限制也不同,
cookie数据不能超过4K,sessionStorage和localStorage可以达到5MsessionStorage:仅在当前浏览器窗口关闭之前有效;localStorage:始终有效,窗口或浏览器关闭也一直保存,本地存储,因此用作持久数据;cookie:只在设置的cookie过期时间之前有效,即使窗口关闭或浏览器关闭
作用域不同
sessionStorage:不在不同的浏览器窗口中共享,即使是同一个页面;localstorage:在所有同源窗口中都是共享的;也就是说只要浏览器不关闭,数据仍然存在cookie: 也是在所有同源窗口中都是共享的.也就是说只要浏览器不关闭,数据仍然存在
前端工程化
webpack配置,webpack4.0有哪些优化点
module.exports={
entry: {},
output: {},
plugins: [],
module: [rules:[{}]]
}
webpack如何实现代码分离
入口起点:使用entry配置手动地分离代码。防止重复:使用CommonsChunkPlugin去重和分离chunk。动态导入:通过模块的内联函数调用来分离代码。
常见的Webpack Loader? 如何实现一个Webpack Loader(NO)
loader: 是一个导出为函数的javascript模块,根据rule匹配文件扩展名,处理文件的转换器。
file-loader:把文件输出到一个文件夹中,在代码中通过相对 URL 去引用输出的文件 (处理图片和字体)
url-loader: 与file-loader类似,区别是用户可以设置一个阈值,大于阈值会交给file-loader处理,小于阈值时返回文件base64 形式编码 (处理图片和字体)
image-loader:加载并且压缩图片文件
babel-loader:把 ES6 转换成 ES5
sass-loader:将SCSS/SASS代码转换成CSS
css-loader:加载 CSS,支持模块化、压缩、文件导入等特性
style-loader:把 CSS 代码注入到 JavaScript 中,通过 DOM 操作去加载 CSS
postcss-loader:扩展 CSS 语法,使用下一代 CSS,可以配合 autoprefixer 插件自动补齐 CSS3 前缀eslint-loader:通过 ESLint 检查 JavaScript 代码
常见的Webpack Plugin? 如何实现一个Webpack Plugin(NO)
plugin:本质是插件,基于事件流框架 Tapable,插件可以扩展 Webpack 的功能,在 Webpack 运行的生命周期中会广播出许多事件,Plugin 可以监听这些事件,在合适的时机通过 Webpack 提供的 API 改变输出结果。
html-webpack-plugin:简化 HTML 文件创建 (依赖于 html-loader)
uglifyjs-webpack-plugin:压缩js文件
clean-webpack-plugin:目录清除
mini-css-extract-plugin:分离样式文件,CSS 提取为独立文件,支持按需加载 (替代extract-text-webpack-plugin)
loader和plugin对比?
Loader在module.rules中配置,作为模块的解析规则,类型为数组。每一项都是一个 Object,内部包含了test(类型文件)、loader、options(参数)等属性。Plugin在plugins中单独配置,类型为数组,每一项是一个Plugin的实例,参数都通过构造函数传入。
前端模块化,CMD、AMD、CommonJS
CommonJS
CommonJS是服务器端模块的规范,由Node推广使用,webpack也采用这种规范编写
commonJs规范:
CommonJS模块规范主要分为三部分:模块定义、模块标识、模块引用。
模块定义:
module对象:在每一个模块中,module对象代表该模块自身。export属性:module对象的一个属性,它向外提供接口。输出模块变量的最好方法是使用module.exports对象。一个单独的文件就是一个模块。每一个模块都是一个单独的作用域,也就是说,在该模块内部定义的变量,无法被其他模块读取,除非定义为global对象的属性。模块标识:传递给
require方法的参数,必须是符合小驼峰命名的字符串,或者以 . 、.. 、开头的相对路径,或者绝对路径。模块引用:加载模块使用
require(同步加载),该方法读取一个文件并执行,返回文件内部的module.exports对象。
优势:
在后端,JavaScript的规范远远落后并且有很多缺陷,这使得难以使用JavaScript开发大型应用。比如:没有模块系统、标准库较少、没有标准接口、缺乏包管理系统、列表内容
CommonJS模块规范很好地解决变量污染问题,每个模块具有独立空间,互不干扰,命名空间相比之下就不太好。
CommonJS规范定义模块十分简单,接口十分简洁。
CommonJS模块规范支持引入和导出功能,这样可以顺畅地连接各个模块,实现彼此间的依赖关系
CommonJS规范的提出,主要是为了弥补JavaScript没有标准的缺陷,已达到像Python、Ruby和Java那样具备开发大型应用的基础能力,而不是停留在开发浏览器端小脚本程序的阶段
缺点:
没有并行加载机制
由于CommonJS是同步加载模块,这对于服务器端是很不好的,因为所有的模块都放在本地硬盘。等待模块时间就是硬盘读取文件时间,很小。但是,对于浏览器而言,它需要从服务器加载模块,涉及到网速,代理等原因,一旦等待时间过长,浏览器处于”假死”状态。
所以浏览器端不是很适合Common.Js,出现另一种规范AMD
AMD
AMD 是运行在浏览器环境的一个异步模块定义规范 ,是RequireJS 在推广过程中对模块定义的规范化产出。
AMD规范
AMD推崇依赖前置,在定义模块的时候就要声明其依赖的模块
优点
用户体验好,因为没有延迟,依赖模块提前执行了。
CMD
CMD是一个通用模块定义规范;是SeaJs推广过程中对模块定义的规范化产出
CMD规范
CMD推崇依赖就近,只有在用到某个模块的时候才会去require
优点
性能好,因为只有用户需要的时候才执行。
面试手写代码系列
防抖节流
函数防抖关注一定时间连续触发,只在最后执行一次,而函数节流侧重于一段时间内只执行一次。
防抖
//定义:触发事件后在n秒内函数只能执行一次,如果在n秒内又触发了事件,则会重新计算函数执行时间。
//搜索框搜索输入。只需用户最后一次输入完,再发送请求
//手机号、邮箱验证输入检测 onchange oninput事件
//窗口大小Resize。只需窗口调整完成后,计算窗口大小。防止重复渲染。
const debounce = (fn, wait, immediate) => {
let timer = null;
return function (...args) {
if (timer) clearTimeout(timer);
if (immediate && !timer) {
fn.call(this, args);
}
timer = setTimeout(() => {
fn.call(this, args);
}, wait);
};
};
const betterFn = debounce(() => console.log("fn 防抖执行了"), 1000, true);
document.addEventListener("scroll", betterFn);
节流
//定义:当持续触发事件时,保证隔间时间触发一次事件。
//1. 懒加载、滚动加载、加载更多或监听滚动条位置;
//2. 百度搜索框,搜索联想功能;
//3. 防止高频点击提交,防止表单重复提交;
function throttle(fn,wait){
let pre = 0;
return function(...args){
let now = Date.now();
if( now - pre >= wait){
fn.apply(this,args);
pre = now;
}
}
}
function handle(){
console.log(Math.random());
}
window.addEventListener("mousemove",throttle(handle,1000));
对象深浅拷贝
//浅拷贝
1. Object.assign(target,source)
2. es6对象扩展运算符。
//深拷贝
function deepClone(obj) {
if (!obj || typeof obj !== "object") return;
let newObj = Array.isArray(obj) ? [] : {};
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
newObj[key] = typeof obj[key] === "object" ? deepClone(obj[key]) : obj[key];
}
}
return newObj;
}
数组去重,数组对象去重
//数组
const arr = [2,7,5,7,2,8,9];
console.log([...new Set(arr)]); // [2,7,5,8,9];
//对象
const list = [{age:18,name:'张三'},{age:18,name:'李四'},{age:18,name:'王五'}]
let hash = {};
const newArr = arr.reduce((item, next) => {
hash[next.age] ? '' : hash[next.age] = true && item.push(next);
return item;
}, []);
console.log(list);
数组扁平化
function flatten(arr) {
return arr.reduce((result, item) => {
return result.concat(Array.isArray(item) ? flatten(item) : item);
}, []);
}
职业技能规划、人事面试
未来准备往哪方面发展?精通/全干
对于职业规划的个人见解
自身价值的体现
离职原因
个人职业规划原因
公司原因
其他
你未来一到三年的一个职业规划是什么?
你都是怎么去学习和关注新技术的?
你近几年工作中有哪些心得或总结?
你觉得你在工作中的优缺点是什么?
你过来我们公司,你的优势是什么?
有些过开源项目吗?
写过 npm 包吗,写过 webpack 插件吗?
看过哪些框架或者类库的源码,有什么收获?
补充
ES6里的symble
它的功能类似于一种标识唯一性的ID,每个Symbol实例都是唯一的。Symbol类型的key是不能通过Object.keys()或者for...in来枚举的,
它未被包含在对象自身的属性名集合(property names)之中。
所以,利用该特性,我们可以把一些不需要对外操作和访问的属性使用Symbol来定义。
// 使用Object的APIObject.getOwnPropertySymbols(obj) // [Symbol(name)]
// 使用新增的反射APIReflect.ownKeys(obj) // [Symbol(name), 'age', 'title']
ES6里的set和map
Map对象保存键值对。任何值(对象或者原始值) 都可以作为一个键或一个值。构造函数Map可以接受一个数组作为参数。Set对象允许你存储任何类型的值,无论是原始值或者是对象引用。它类似于数组,但是成员的值都是唯一的,没有重复的值。
vue的key
key的作用主要是为了高效的更新虚拟DOM,其原理是vue在patch过程中通过key可以精准判断两个节点是否是同一个,
从而避免频繁更新不同元素,使得整个patch过程更加高效,减少DOM操作量,提高性能。
2. 另外,若不设置key还可能在列表更新时引发一些隐蔽的bug
3. vue中在使用相同标签名元素的过渡切换时,也会使用到key属性,其目的也是为了让vue可以区分它们,
否则vue只会替换其内部属性而不会触发过渡效果。
普通函数和箭头函数的区别
箭头函数是匿名函数,不能作为构造函数,不能使用new
箭头函数不绑定
arguments,取而代之用rest参数...解决箭头函数不绑定
this,会捕获其所在的上下文的this值,作为自己的this值箭头函数通过
call() 或 apply()方法调用一个函数时,只传入了一个参数,对 this 并没有影响。箭头函数没有原型属性
箭头函数不能当做
Generator函数,不能使用yield关键字
总结:
箭头函数的
this永远指向其上下文的this,任何方法都改变不了其指向,如call() , bind() , apply()普通函数的this指向调用它的那个对象
JS函数柯里化
参数复用
提前确认
延迟运行
// 普通的add函数
function add(x, y) {
return x + y
}
// Currying后
function curryingAdd(x) {
return function (y) {
return x + y
}
}
add(1, 2) // 3
curryingAdd(1)(2) // 3
实现继承口述
原型链继承写个父类、子类 子类的原型为父类的实例 子类.prootype = new 父类 修正子类原型为子类本身 子类.prototype.constructor=子类 new 子类即可调用父类方法 构造函数继承 写个父类、子类 在子类中父类.call(this) 即可实现
mapState, mapGetters, mapActions, mapMutations
当一个组件需要获取多个状态时候,将这些状态都声明为计算属性会有些重复和冗余。为了解决这个问题,我们可以使用 mapState 辅助函数帮助我们生成计算属性 mapMutations 其实跟mapState 的作用是类似的,将组件中的 methods 映射为 store.commit 调用
计算一个函数的难易程度公式
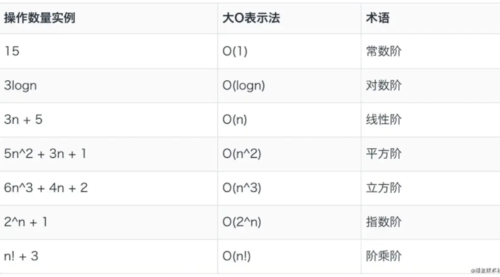
如上图可以粗略的分为两类,多项式量级和非多项式量级。其中,非多项式量级只有两个:O(2n) 和 O(n!) 对应的增长率如下图所示

vue源码理解
xxxxx...
osi7层模型,tcp5层模型
osi7层模型:物理层-数据链路层-传输层-网络层-应用层-会话层-表示层
tcp5层模型:物理层-数据链路层-传输层-网络层-应用层
写在最后
我是伊人a,与你相逢,我很开心。
文中如有错误,欢迎在评论区指正,如果这篇文章帮到了你,欢迎点赞👍和关注😊
本文首发于掘金,未经许可禁止转载💌
面试思维导图(图片太大建议下载查看)
作者:伊人a
共同学习,写下你的评论
评论加载中...
作者其他优质文章


