
摘要:在这个算力还可以的时代,我们的研究人员一方面致力于不断地去研究各中不同的场景中的的通用网络,一方面致力于优化神经网络的学习方式,这些都是在试图化减少AI需要的算力资源。
本文分享自华为云社区《OCR性能优化系列(二):从神经网络到橡皮泥》,原文作者:HW007 。
OCR是指对图片中的印刷体文字进行识别,最近在做OCR模型的性能优化,用 CudaC 将基于TensorFlow 编写的OCR网络重写了一遍,最终做到了5倍的性能提升。通过这次优化工作对OCR网络的通用网络结构和相关的优化方法有较深的认识,计划在此通过系列博文记录下来,也作为对自己最近工作的一个总结和学习笔记。在第一篇《OCR性能优化系列(一):BiLSTM网络结构概览》中,从动机的角度来推演下基于Seq2Seq结构的OCR网络是如何一步步搭建起来的。接下来我们讲从神经网络到橡皮泥。
1. 深扒CNN:也谈机器学习的本质
现在,从OCR性能优化系列(一)中的图1左下角的输入开始,串一遍图一的流程。首先是输入27张待识别的文字片段图片,每张图片的大小为32132。这些图片会经过一个CNN网络进行编码,输出32个27384的初步编码矩阵。如下图所示:
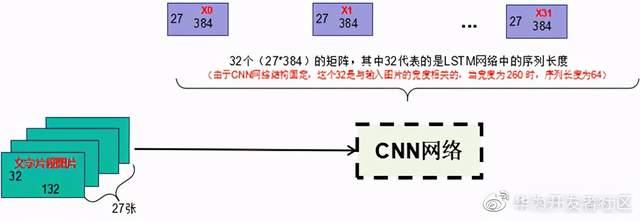
值得注意的是,在这步操作中出现了维度次序的调整,即输入由27*(32132)变成了 27(384),你可以理解为把尺寸为32132的图片拉长拍扁成一行(14224),然后再进行降维为 1384了,类似于上文优化策略一中做计算量优化时把1024降到128的例子。怎么做这个从 274224到27384的降维呢?最简单粗暴的方法就是上面的Y=AX+B模型,直接给274224乘以一个4224*384的矩阵A,矩阵A是通过喂数据训练得到的。很明显,对同样的X,不同的A得到的Y也不一样,而从4224到384这个维度降得又有点狠。于是,学者们便祭出了群殴大法,一个A不行,那就上多个A吧。于是在这里便祭出了32个A,这个32便是后面的LSTM网络的序列长度,与输入图片的宽度132成比例。当输入图片的宽度变成260时,就需要64个A了。
也许有人会问在CNN中看不到你说的32个A啊?的确,那只是我对CNN网络功能的抽象,重点在于让大家对CNN编码过程中维度的变化及其下一层LSTM网络的序列长度有个形象的认识,知道LSTM的序列长度其实是“降维器”的数量。如果你比较机智的话,你应该发现我连“降维”都说错了,因为如果把32个“降维器”输出的结果拼一起的话是32*384=12288,远大于4224,数据经过CNN网络后,维度不但没有减少,反而增加了!其实这个东西比较正式的叫法是“编码器”或“解码器”,“降维器”是我本文中为了形象点自创的,不管叫猫还是叫咪,我希望你能记住,他的本质就是那个系数矩阵A而已。
现在我们还是沿着32个A这个思路走下去,经过CNN网络后,从表面上看,对于每个文字图片来说,数据维度从32132变成了32384,表面上看这个数据量增多了,但信息量并没有增加。就像我在这长篇累牍地介绍OCR,文字是增多了,信息量还是OCR的原理,或许能提升点可读性或趣味性。CNN网络是怎么做到废话连篇(只增加数据量不增加信息量)的呢?这里隐含着一个机器学习模型中的一个顶级套路,学名叫“参数共享”。一个简单的例子,如果有一天你的朋友很高兴地告诉你他有一个新发现,“买1个苹果要给5块钱,买2个苹果要给10块钱,买3个苹果要给15块钱…”,相信你一定会怀疑他的智商,直接说“买n个苹果要5*n块钱”不就好了么?废话的本质在于,不做抽象总结,直接疯狂的举例子,给一大堆冗余数据。不废话的本质就是总结出规律和经验,所谓的机器学习就是如这个买苹果的例子,你期望简单粗暴的给机器举出大量的例子,机器便能总结出其中的规律和经验。这个规律和经验对应到上述的OCR例子中,便是整个模型的网络结构和模型参数。在模型网络上,目前主流还是靠人类智能,如对图片场景就上CNN网络,对序列场景就上RNN网络等等。网络结构选不对的话,学习出来的模型的效果会不好。
如上面的分析中,其实在结构上,我用32个4224384的A矩阵是完全能满足上述的CNN在数据的输入和输出的维度尺寸上的要求的,但这样的话训练出来的模型效果会不好。因为从理论上,用32个4224384的A矩阵的参数量是324224384=51904512。这便意味着在学习过程中,模型太自由了,很容易学坏。在上面买苹果的例子中,用越少的字就能陈述清楚这个事实的人的总结能力就越强,因为越多的文字除了引入冗余外,还有可能会引入一些毫不相关的信息对以后在使用这个规律的时候进行干扰,假设这个苹果的价格是用10个字就能说清楚,你用了20个字,那很有可能你其他的10个字是在描述比如下雨啊、时间点啊之类的无关信息。这就是大名鼎鼎的“奥坎姆剃刀法则”,不要把简单的东西复杂化!在机器学习领域主要应用于模型结构的设计和选择中,“参数共享”的是其常用的套路之一,简单说就是,如果32个4224384的A矩阵参数量太大了,导致模型在学习中太自由了,那我们就加限制让模型不那么自由,一定要逼它在10个字内把买苹果的事情说清楚。方法很简单,比如说如果这32个A长得完全一模一样,那这里的参数个数就只有4224384个而已,一下子就减少32倍,如果觉得减少32倍太狠了,那我稍微放松一点,不要求这32个A一模一样,只要求他们长得很像就好。
在此我称这个剃刀大法为“不逼模型一把就不知道模型有多优秀大法”。可能有人会提出异议,虽然我允许你用20个字来说清楚苹果的价格,并没有抹杀你主动性很强,追求极致,用10个字就说清楚了的可能性。如果上文中的只用一个A矩阵就能Cover住的话,那么我不管我给32个A还是64个A,模型都应该学出的是一模一样的A才对。这种说法在理论上是对的,但对于目前来说却是不现实的。
讨论这个问题还得回到机器学习的本质上,所有模型都可以抽象表示为 Y=AX,其中X是模型输入,Y是模型输出,A是模型,注意在此段中的A不同于上文中的A,其既包含了模型的结构和又包含了参数。模型的训练过程便是已知X和Y,求解A。上面的问题其实就是解出来的A是不是唯一的?首先我退一步,假设我们认为在现实世界中这个问题是存在规律的,也就是说这个A在现实世界中是存在且唯一的,就像物理定律一样,那我们的模型是否能在大量的训练数据中捕获到这个规律呢?
以物理上的质能方程 E=MC2为例,在这个模型中,模型的结构是E=M*C2,模型的参数是光速C。这个模型爱因斯坦提出的,可以说是人类智能的结晶。如果用现在AI大法来解决这个问题呢,分两种情况,一种是强AI,一种是弱AI,首先说最极端的弱AI的方法,也就是目前的主流的AI方法,大部分人工小部分机器智能,具体说就是人类根据自己的智慧发现E和M之间的关系满足E=MC2这样的模式,然后喂很多的E和M数据进去给机器,让机器把这个模型中的参数C学习出来,在这个例子中C的解是唯一的,而且只要喂给机器少量的M和C,就能把C解出来了。显然智能部分的工作量主要在于爱因斯坦大神是如何去排除如时间、温度、湿度等等各种乱七八糟的因素,确定E就只和M有关,且满足E=M*C2。这部分工作在目前机器学习领域被叫模型的“特征选择”,所以很多机器学习的工程师会戏称自己为“特征工程师”。
与之相反,强AI的预期就应该是我们喂给机器一大堆的数据,如能量、质量、温度、体积、时间、速度等等,由机器来告诉我这里面的能量就只和质量相关,他们的关系是E=M*C2,并且这个常数C的值就是3.0*108(m/s)。在这里,机器不但要把模型的结构学出来,还要把模型的参数学出来。要达到这个效果,首先要完成的第一步是,找到一种泛化的模型,经过加工后能描述世界上存在的所有模型结构,就像橡皮泥能被捏成各种各样的形状一样。这个橡皮泥在AI领域就是神经网络了,所以很多偏理论的AI书或者课程都喜欢在一开始给你科普下神经网络的描述能力,证明它就是AI领域的那块橡皮泥。既然橡皮泥有了,接下来就是怎么捏了,难点就在这里了,并不是生活中每个问题每个场景都能用一个个数学模型来完美表示的,就算这层成立,在这个模型结构被发现之前,没人知道这个模型是什么样子,那你让机器怎么帮你捏出这个你本身都不知道是什么形状的东西?唯一的办法就是,给机器喂很多的例子,说捏出来的东西要满足能走路、会飞等等。其实这个问题是没有唯一解的,机器可以给你捏出一只小鸟、也可以给你捏出一只小强。原因有二,其一在于你无法把所有可能的例子都喂给机器,总会有“黑天鹅”事件;其二在于喂的例子太多的话,对机器的算力要求也高,这也是为啥神经网络很早就提出来了,这几年才火起来的原因。
经过上面一段的探讨,希望你在此时能对机器学习的模型结构和模型参数能有一个比较直观的理解。知道如果靠人类智能设计出模型结构,再靠机器学习出参数的话,在模型结构准确的前提下,如上面的E=M*C^2,我们只需要喂给机器很少的数据就好,甚至模型都能有很好的解析解!但毕竟爱因斯坦只有一个,所以更多的是我们这种平凡的人把大量的例子喂给机器,期望他能捏出我们自己都不知道的那个形状,更别提有解析解这么漂亮的性质了。对机器学习训练过程熟悉的同学应该知道,机器学习捏橡皮泥用的“随机梯度下降法”,通俗点说,就是先捏一小下,看捏出来的东西是否能满足你提的要求(即喂的训练数据),如果不满足再捏一小下,如此循环直至满足你的要求才停下来。由此可见,机器捏橡皮泥的动力在于捏出来的东西不满足你的要求。这就证明了机器是个很“懒”的东西,当他用20个字描述出苹果的价格规律后,就没动力去做用10个字来描述苹果价格的规律了。所以,当你自己都不知道你想让机器捏出什么东西时,最好就是不要给机器太大的自由,这样机器会给你捏出一个很复杂的东西,尽管能满足你的要求,也不会很好用,因为违反了剃刀法则。而在机器学习的模型中,参数的数量越多,往往意味着更大的自由度和更复杂的结构,出现“过拟合”现象。因此很多经典的网络结果中都会使用一些技巧来做“参数共享”,达到减少参数的目的,如CNN网络中使用的卷积的方式来做参数共享,LSTM中引入了一个变化不那么剧烈的产量C矩阵来实现参数共享。
2. 牛刀小试:LSTM等你扒
经过上面小节的探讨,相信你已经get到分析机器学习的一些套路了,最后以双向LSTM来练下手吧。
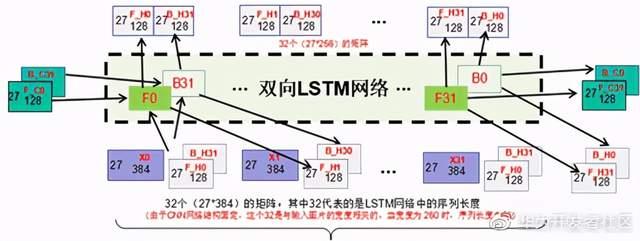
如上图,首先看LSTM网络的输入和输出,最明显能看到的输入有32个27384的紫色矩阵,输出是32个27256的矩阵,其中27256是由两个27128拼凑而成,分别由前向LSTM和反向LSTM网络输出。为了简单,我们暂时只看前向LSTM,这样的话其实输入就是32个27384的矩阵,输出是32个27128 的矩阵。根据上文中分析的“降维器”套路,这里需要32个384*128的矩阵。在根据“参数共享”套路,真正的单个LSTM单元的结构如下图所示:
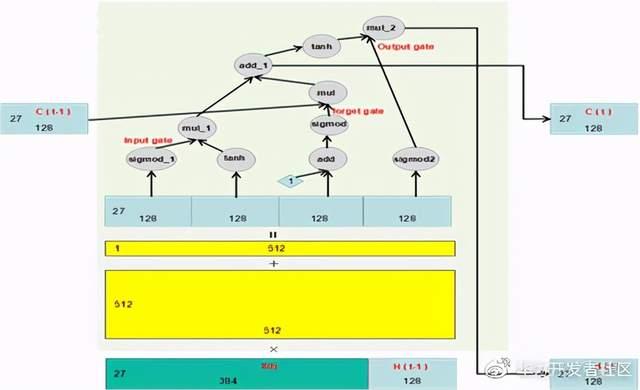
由图可知,真正的LSTM单元中并不是一个简单的384128的矩阵A,而是把LSTM单元序列中的上一个单元的输出节点H拉下来和输入X拼在一起,形成一个27512的输入,在乘以一个512512的参数矩阵,再联合上一个序列输出的控制节点C对得到的数据进行加工,把512维降到128维,最后得到两个输出,一个是27128的新输出节点H,一个是27*128的新控制节点C。这个新输出的H和C会被引入到下一个LSTM单元,对下一个LSTM单元的输出进行影响。
在这里,可以看到由于矩阵C和矩阵H的存在,即使LSTM序列32个单元中的那个512512的参数矩阵是一模一样的,即便每个单元的输入H和X之间的关系都是不大一样的,但由于都是乘以一样的512512矩阵得到的,所以尽管不一样,相互间应该还是比较像,因为他们遵循了一套规律(那个一模一样的512*512矩阵)。在这里我们可以看到LSTM是通过把上一个单元的输出H和输入X拼起来作为输入,同时引入控制矩阵C来实现剃刀大法,达到参数共享,简化模型的目的。这种网络结构的构造也使得当前序列单元的输出和上个序列单元的输出产生联系,适用于序列场景的建模,如OCR、NLP、机器翻译和语音识别等等。
在这里我们还能看到,虽然神经网络是那块橡皮泥,但由于喂不了所有的情况的数据、机器算力不支持、或者我们想提高机器的学习速度,在目前的AI应用场景中,我们都是给根据实际应用场景精和自己的先验知识对网络结构进行精心地设计,再把这块由人类捏得差不多的橡皮泥交由机器来捏。因此我更喜欢称现在是个弱AI的时代,在这个算力还可以的时代,我们的研究人员一方面致力于不断地去研究各中不同的场景中的的通用网络,如用于图像的CNN、用于序列RNN、LSTM、GRU等等,一方面致力于优化神经网络的学习方式,如基于SDG的各种优化变种算法和强化学习的训练方式等等,这些都是在试图化减少AI需要的算力资源。
相信在人类的努力下,强AI的时代会到来。
作者:华为云开发者社区
链接:https://juejin.cn/post/6966803886757642270
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



