
1. ShardingJDBC的集成配置
-
POM依赖配置
org.projectlomboklombokprovidedorg.springframework.bootspring-boot-starter-weborg.apache.shardingspheresharding-jdbc-core${sharding.jdbc.version}org.apache.shardingspheresharding-jdbc-orchestration${sharding.jdbc.version}mysqlmysql-connector-java${mysql.version}com.alibabadruid-spring-boot-starter${druid.version}org.springframework.bootspring-boot-starter-data-jpa -
数据源配置
server: port: 10692 spring: application: name: dynamic-database # 第一个数据源配置, 采用Druid datasource: tradesystem: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver username: root password: 654321 url: jdbc:mysql://10.10.20.130:3306/smooth?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC druid: # 连接池的配置信息 # 初始化大小,最小,最大 initial-size: 5 min-idle: 5 maxActive: 20 # 配置获取连接等待超时的时间 maxWait: 60000 # 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 timeBetweenEvictionRunsMillis: 60000 # 配置一个连接在池中最小生存的时间,单位是毫秒 minEvictableIdleTimeMillis: 300000 validationQuery: SELECT 1 testWhileIdle: true testOnBorrow: false testOnReturn: false # 打开PSCache,并且指定每个连接上PSCache的大小 poolPreparedStatements: true maxPoolPreparedStatementPerConnectionSize: 20 # 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙 filters: stat,wall,log4j # 通过connectProperties属性来打开mergeSql功能;慢SQL记录 #connectionProperties: druid.stat.mergeSql\=true;druid.stat.slowSqlMillis\=5000 -
ShardingJDBC代码配置
分库配置规则:
/** * 分库配置规则 */ public class ShardingDataSourceRule implements PreciseShardingAlgorithm { /** * 分片规则, 取模运算 */ public static int MOD = 1; /** * 根据账户ID做分库处理 * @param names * @param value * @return */ @Override public String doSharding(Collection names, PreciseShardingValue preciseShardingValue) { Long accountNo = preciseShardingValue.getValue(); String dataSource = DatasourceEnum.DATASOURCE_PREFIX.getValue() + accountNo % MOD; return dataSource; } }这里假设根据账户ID来做分库处理, 根据账户ID取模计算分库信息。
分表配置规则:/** * 表分片规则 */ public class ShardingTableRule implements PreciseShardingAlgorithm { @Override public String doSharding(Collection collection, PreciseShardingValue preciseShardingValue) { // 不做分表处理, 直接返回表名 return preciseShardingValue.getLogicTableName(); } }如有需要, 可以在这里设置分表配置规则,因为是做数据库的平滑扩容, 只要实现分库即可, 这里就不做分表的配置, 采用默认表名即可。
分片规则的集成配置:
/** * 分片规则的集成配置 */ private TableRuleConfiguration orderRuleConfig(){ //订单表, 多个分片示例: "DB_${1..3}.t_order_${1..3}" ds_0.t_trade_order DynamicShardingService.SHARDING_RULE_DATASOURCE = DatasourceEnum.DATASOURCE_1.getValue(); String actualDataNodes = DatasourceEnum.DATASOURCE_1.getValue() + "." + DatasourceEnum.TABLE_ORDER.getValue() ; TableRuleConfiguration tableRuleConfig = new TableRuleConfiguration(DatasourceEnum.TABLE_ORDER.getValue(), actualDataNodes); //设置分表策略 tableRuleConfig.setDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("accountNo", new ShardingDataSourceRule())); tableRuleConfig.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("accountNo",new ShardingTableRule())); // 记录订单表的分片规则, 便于后续编排管理 DynamicShardingService.SHARDING_RULE_TABLE_ORDER = actualDataNodes; return tableRuleConfig; } /** * 数据源Sharding JDBC配置 * @return */ @Bean(name = "tradeSystemDataSource") @Primary @DependsOn("tradeDruidDataSource") public DataSource tradeSystemDataSource(@Autowired DruidDataSource tradeDruidDataSource) throws Exception{ ShardingRuleConfiguration shardJdbcConfig = new ShardingRuleConfiguration(); shardJdbcConfig.getTableRuleConfigs().add(orderRuleConfig()); ... }在orderRuleConfig方法里面配置分片规则,在tradeSystemDataSource方法里面加入分片规则配置。
2.服务编排功能(自定义注册中心)
2.0.0.M1版本开始,Sharding-JDBC提供了数据库治理编排功能,主要包括:
- 配置集中化与动态化,可支持数据源、表与分片及读写分离策略的动态切换
- 数据治理。提供熔断数据库访问程序对数据库的访问和禁用从库的访问的能力
- 支持Zookeeper和Etcd的注册中心
这里要实现动态数据源的切换, 需要加入编排功能。
本地注册中心的实现类,LocalRegistryCenter关键代码:
public class LocalRegistryCenter implements RegistryCenter {
/**
* 注册事件监听缓存记录
*/
public static Map listeners = new ConcurrentHashMap<>();
private RegistryCenterConfiguration config;
private Properties properties;
/**
* 记录Sharding节点配置信息
*/
public static Map values = new ConcurrentHashMap<>();
...
@Override
public void watch(String key, DataChangedEventListener dataChangedEventListener) {
if (null != dataChangedEventListener) {
// 将Sharding事件监听器缓存下来
listeners.put(key, dataChangedEventListener);
}
}
...
@Override
public String getType() {
// 标识本地注册中心的注入名称
return "localRegisterCenter";
}
...
}
通过SPI机制, 自动注入, 创建配置文件:
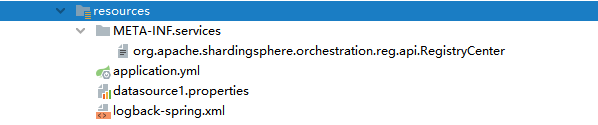
org.apache.shardingsphere.orchestration.reg.api.RegistryCenter内容指向刚才创建的配置类:
com.itcast.database.smooth.config.LocalRegistryCenter
最后在数据源配置里面加入配置类:
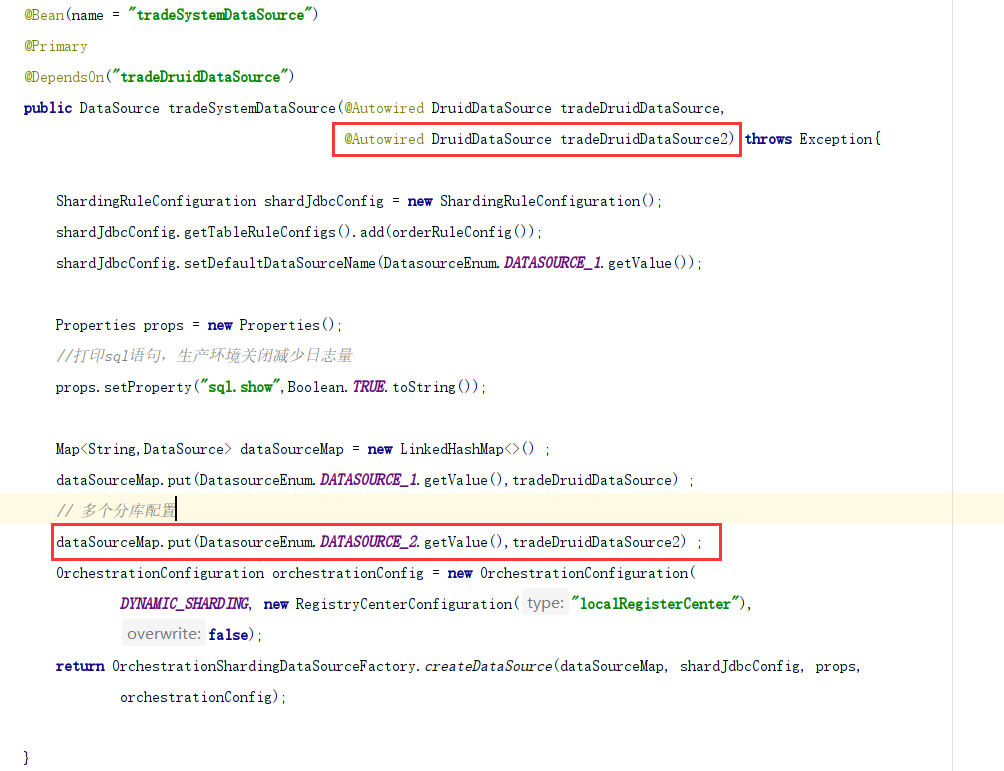
public DataSource tradeSystemDataSource(@Autowired DruidDataSource tradeDruidDataSource) throws Exception{
ShardingRuleConfiguration shardJdbcConfig = new ShardingRuleConfiguration();
shardJdbcConfig.getTableRuleConfigs().add(orderRuleConfig());
shardJdbcConfig.setDefaultDataSourceName(DatasourceEnum.DATASOURCE_1.getValue());
Properties props = new Properties();
//打印sql语句,生产环境关闭减少日志量
props.setProperty("sql.show",Boolean.TRUE.toString());
Map dataSourceMap = new LinkedHashMap<>() ;
dataSourceMap.put(DatasourceEnum.DATASOURCE_1.getValue(),tradeDruidDataSource) ;
// 服务编排配置, 加入本地注册中心配置类
OrchestrationConfiguration orchestrationConfig = new OrchestrationConfiguration(
DYNAMIC_SHARDING, new RegistryCenterConfiguration("localRegisterCenter"),
false);
return OrchestrationShardingDataSourceFactory.createDataSource(dataSourceMap, shardJdbcConfig, props,
orchestrationConfig);
}
3. 动态切换实现(预定义方式)
-
在配置文件增加第二个数据源:
... # 增加第二个数据源配置 tradesystem2: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver username: root password: 654321 url: jdbc:mysql://10.10.20.126:3306/smooth?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC druid: # 连接池的配置信息 # 初始化大小,最小,最大 initial-size: 5 min-idle: 5 maxActive: 20 # 配置获取连接等待超时的时间 maxWait: 60000 # 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 timeBetweenEvictionRunsMillis: 60000 # 配置一个连接在池中最小生存的时间,单位是毫秒 minEvictableIdleTimeMillis: 300000 validationQuery: SELECT 1 testWhileIdle: true testOnBorrow: false testOnReturn: false # 打开PSCache,并且指定每个连接上PSCache的大小 poolPreparedStatements: true maxPoolPreparedStatementPerConnectionSize: 20 # 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙 filters: stat,wall,log4j # 通过connectProperties属性来打开mergeSql功能;慢SQL记录 #connectionProperties: druid.stat.mergeSql\=true;druid.stat.slowSqlMillis\=5000 -
代码配置:
增加第二个数据源配置的配置, 加入MAP中:

-
sharding分片规则配置:
这里会通过接口来调用, 实现Sharding数据源的动态切换:
/** * 替换sharding里的分片规则 */ public void replaceActualDataNodes(String newRule){ // 获取已有的配置 String rules = LocalRegistryCenter.values .get("/" + DruidSystemDataSourceConfiguration.DYNAMIC_SHARDING + "/config/schema/logic_db/rule"); // 修改为新的分片规则 String rule = rules.replace(SHARDING_RULE_TABLE_ORDER, newRule); LocalRegistryCenter.listeners.get("/" + DruidSystemDataSourceConfiguration.DYNAMIC_SHARDING + "/config/schema") .onChange(new DataChangedEvent( "/" + DruidSystemDataSourceConfiguration.DYNAMIC_SHARDING + "/config/schema/logic_db/rule", rule, DataChangedEvent.ChangedType.UPDATED)); LocalRegistryCenter.values.put("/" + DruidSystemDataSourceConfiguration.DYNAMIC_SHARDING + "/config/schema/logic_db/rule",rule); SHARDING_RULE_TABLE_ORDER = newRule; }根据传递的取模参数进行调用修改,如果mod为2代表要分两个库:
-
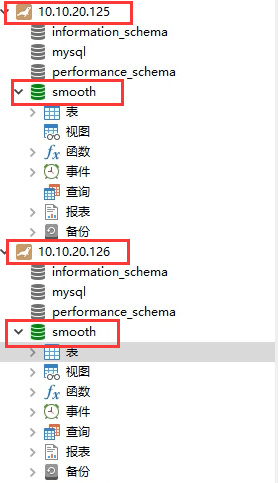
创建两个数据库及对应表结构
-
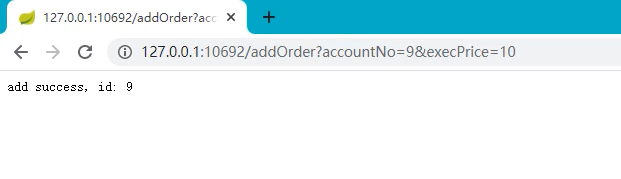
启动服务测试验证
访问接口地址, 服务启动默认只有一个数据源生效, 所有数据都会落在一台数据库节点。
动态调整让第二个数据源生效, 扩容为2个数据源:
从后台日志可以看到Sharding分片规则已生效:这样数据, 就会根据取模规则, 落至不同的数据源节点。


4. 动态切换实现(动态添加方式)
在实际应用当中,可能并不能预先知道所要扩容的机器节点信息, 这时候就需要实现动态添加的方式。
-
删除原来的预定义数据源配置, 只加载一个数据源即可。
-
修改动态分片的实现:
DynamicShardingService:public void dynamicSharding(int mod) { ShardingDataSourceRule.MOD = mod; String newRule = DatasourceEnum.DATASOURCE_PREFIX.getValue() + "${0.." + (mod - 1) + "}"; if(mod == 1) { ... }else { // 动态数据源配置实现扩容 Properties properties = loadPropertiesFile("dynamic_datasource.properties"); try { log.info("load datasource config url: " + properties.get("url")); DruidDataSource druidDataSource = (DruidDataSource) DruidDataSourceFactory.createDataSource(properties); druidDataSource.setRemoveAbandoned(true); druidDataSource.setRemoveAbandonedTimeout(600); druidDataSource.setLogAbandoned(true); // 设置数据源错误重连时间 druidDataSource.setTimeBetweenConnectErrorMillis(60000); druidDataSource.init(); OrchestrationShardingDataSource dataSource = SpringContextUtil.getBean("tradeSystemDataSource", OrchestrationShardingDataSource.class); Map dataSourceMap = dataSource.getDataSource().getDataSourceMap(); dataSourceMap.put(DatasourceEnum.DATASOURCE_2.getValue(), druidDataSource); Map dataSourceConfigMap = new HashMap(); for(String key : dataSourceMap.keySet()) { dataSourceConfigMap.put(key, DataSourceConfiguration.getDataSourceConfiguration(dataSourceMap.get(key))); } String result = SHARDING_RULE_TABLE_ORDER.replace(SHARDING_RULE_DATASOURCE, newRule); replaceActualDataNodes(result); SHARDING_RULE_DATASOURCE = newRule; // 重新数据源配置 dataSource.renew(new DataSourceChangedEvent( "/" + DruidSystemDataSourceConfiguration.DYNAMIC_SHARDING + "/config/schema/logic_db/datasource", dataSourceConfigMap)); return; } catch (Exception e) { log.error(e.getMessage(), e); } } String result = SHARDING_RULE_TABLE_ORDER.replace(SHARDING_RULE_DATASOURCE, newRule); replaceActualDataNodes(result); SHARDING_RULE_DATASOURCE = newRule; }如果取模分片大于1, 走扩容处理逻辑, 在这里可以将扩容数据源信息写至配置文件内(也可以从配置中心读取),然后动态创建数据源, 重写Sharding的编排配置OrchestrationShardingDataSource。
扩容的数据源配置文件放至资源目录下:
dynamic_datasource.properties
driverClassName=com.mysql.cj.jdbc.Driver username=root password=654321 url=jdbc:mysql://10.10.20.131:3306/smooth?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC initialSize=5 minIdle=5 maxActive=20 maxWait=60000 timeBetweenEvictionRunsMillis=60000 minEvictableIdleTimeMillis=300000 validationQuery=SELECT 1 testWhileIdle=true testOnBorrow=false testOnReturn=false -
测试验证
参照上面的方式进行测试验证,这样就可以在不需要重启服务的情况下, 任意添加数据源节点。
5. ShardingJDBC使用注意事项
Sharding JDBC, Mycat, Drds 等产品都是分布式数据库中间件, 相比直接的数据源操作, 会存在一些限制, Sharding JDBC在使用时, 需要注意以下问题, 避免采坑:
- 有限支持子查询
- 不支持HAVING
- 不支持OR,UNION 和 UNION ALL
- 不支持特殊INSERT
- 每条INSERT语句只能插入一条数据,不支持VALUES后有多行数据的语句
- 不支持DISTINCT聚合
- 不支持dual虚拟表查询
- 不支持SELECT LAST_INSERT_ID(), 不支持自增序列
- 不支持CASE WHEN
共同学习,写下你的评论
评论加载中...
作者其他优质文章


