
1.通过Executors创建线程池的弊端
在创建线程池的时候,大部分人还是会选择使用Executors去创建。
下面是创建定长线程池(FixedThreadPool)的一个例子,严格来说,当使用如下代码创建线程池时,是不符合编程规范的。
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(5);
原因在于:(摘自阿里编码规约)
线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors各个方法的弊端:
1)newFixedThreadPool和newSingleThreadExecutor:
主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至OOM。
2)newCachedThreadPool和newScheduledThreadPool:
主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM。
2.通过ThreadPoolExecutor创建线程池
所以,针对上面的不规范代码,重构为通过ThreadPoolExecutor创建线程池的方式。
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters and default thread factory.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
* @throws IllegalArgumentException if one of the following holds:<br>
* {@code corePoolSize < 0}<br>
* {@code keepAliveTime < 0}<br>
* {@code maximumPoolSize <= 0}<br>
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue}
* or {@code handler} is null
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
ThreadPoolExecutor 是线程池的核心实现。线程的创建和终止需要很大的开销,线程池中预先提供了指定数量的可重用线程,所以使用线程池会节省系统资源,并且每个线程池都维护了一些基础的数据统计,方便线程的管理和监控。
3.ThreadPoolExecutor参数解释
下面是对其参数的解释,在创建线程池时需根据自己的情况来合理设置线程池。
corePoolSize & maximumPoolSize
核心线程数(corePoolSize)和最大线程数(maximumPoolSize)是线程池中非常重要的两个概念,希望同学们能够掌握。
当一个新任务被提交到池中,如果当前运行线程小于核心线程数(corePoolSize),即使当前有空闲线程,也会新建一个线程来处理新提交的任务;如果当前运行线程数大于核心线程数(corePoolSize)并小于最大线程数(maximumPoolSize),只有当等待队列已满的情况下才会新建线程。
keepAliveTime & unit
keepAliveTime 为超过 corePoolSize 线程数量的线程最大空闲时间,unit 为时间单位。
等待队列
任何阻塞队列(BlockingQueue)都可以用来转移或保存提交的任务,线程池大小和阻塞队列相互约束线程池:
1.如果运行线程数小于corePoolSize,提交新任务时就会新建一个线程来运行;
2.如果运行线程数大于或等于corePoolSize,新提交的任务就会入列等待;如果队列已满,并且运行线程数小于maximumPoolSize,也将会新建一个线程来运行;
3.如果线程数大于maximumPoolSize,新提交的任务将会根据拒绝策略来处理。
下面来看一下三种通用的入队策略:
1.直接传递:
通过 SynchronousQueue 直接把任务传递给线程。如果当前没可用线程,尝试入队操作会失败,然后再创建一个新的线程。当处理可能具有内部依赖性的请求时,该策略会避免请求被锁定。直接传递通常需要无界的最大线程数(maximumPoolSize),避免拒绝新提交的任务。当任务持续到达的平均速度超过可处理的速度时,可能导致线程的无限增长。
2.无界队列:
使用无界队列(如 LinkedBlockingQueue)作为等待队列,当所有的核心线程都在处理任务时, 新提交的任务都会进入队列等待。因此,不会有大于 corePoolSize 的线程会被创建(maximumPoolSize 也将失去作用)。这种策略适合每个任务都完全独立于其他任务的情况;例如网站服务器。这种类型的等待队列可以使瞬间爆发的高频请求变得平滑。当任务持续到达的平均速度超过可处理速度时,可能导致等待队列无限增长。
3.有界队列:
当使用有限的最大线程数时,有界队列(如 ArrayBlockingQueue)可以防止资源耗尽,但是难以调整和控制。队列大小和线程池大小可以相互作用:使用大的队列和小的线程数可以减少CPU使用率、系统资源和上下文切换的开销,但是会导致吞吐量变低,如果任务频繁地阻塞(例如被I/O限制),系统就能为更多的线程调度执行时间。使用小的队列通常需要更多的线程数,这样可以最大化CPU使用率,但可能会需要更大的调度开销,从而降低吞吐量。
拒绝策略
当线程池已经关闭或达到饱和(最大线程和队列都已满)状态时,新提交的任务将会被拒绝。ThreadPoolExecutor 定义了四种拒绝策略:
1.AbortPolicy:
默认策略,在需要拒绝任务时抛出RejectedExecutionException;
2.CallerRunsPolicy:
直接在 execute 方法的调用线程中运行被拒绝的任务,如果线程池已经关闭,任务将被丢弃;
3.DiscardPolicy:
直接丢弃任务;
4.DiscardOldestPolicy:
丢弃队列中等待时间最长的任务,并执行当前提交的任务,如果线程池已经关闭,任务将被丢弃。
我们也可以自定义拒绝策略,只需要实现 RejectedExecutionHandler;需要注意的是,拒绝策略的运行需要指定线程池和队列的容量。
4.ThreadPoolExecutor创建线程方式
通过下面的demo来了解ThreadPoolExecutor创建线程的过程。
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* 测试ThreadPoolExecutor对线程的执行顺序
**/
public class ThreadPoolSerialTest {
public static void main(String[] args) {
//核心线程数
int corePoolSize = 3;
//最大线程数
int maximumPoolSize = 6;
//超过 corePoolSize 线程数量的线程最大空闲时间
long keepAliveTime = 2;
//以秒为时间单位
TimeUnit unit = TimeUnit.SECONDS;
//创建工作队列,用于存放提交的等待执行任务
BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<Runnable>(2);
ThreadPoolExecutor threadPoolExecutor = null;
try {
//创建线程池
threadPoolExecutor = new ThreadPoolExecutor(corePoolSize,
maximumPoolSize,
keepAliveTime,
unit,
workQueue,
new ThreadPoolExecutor.AbortPolicy());
//循环提交任务
for (int i = 0; i < 8; i++) {
//提交任务的索引
final int index = (i + 1);
threadPoolExecutor.submit(() -> {
//线程打印输出
System.out.println("大家好,我是线程:" + index);
try {
//模拟线程执行时间,10s
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
//每个任务提交后休眠500ms再提交下一个任务,用于保证提交顺序
Thread.sleep(500);
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
threadPoolExecutor.shutdown();
}
}
}
执行结果:
这里描述一下执行的流程:
-
首先通过 ThreadPoolExecutor 构造函数创建线程池;
-
执行 for 循环,提交 8 个任务(恰好等于maximumPoolSize[最大线程数] + capacity[队列大小]);
-
通过 threadPoolExecutor.submit 提交 Runnable 接口实现的执行任务;
-
提交第1个任务时,由于当前线程池中正在执行的任务为 0 ,小于 3(corePoolSize 指定),所以会创建一个线程用来执行提交的任务1;
-
提交第 2, 3 个任务的时候,由于当前线程池中正在执行的任务数量小于等于 3 (corePoolSize 指定),所以会为每一个提交的任务创建一个线程来执行任务;
-
当提交第4个任务的时候,由于当前正在执行的任务数量为 3 (因为每个线程任务执行时间为10s,所以提交第4个任务的时候,前面3个线程都还在执行中),此时会将第4个任务存放到 workQueue 队列中等待执行;
-
由于 workQueue 队列的大小为 2 ,所以该队列中也就只能保存 2 个等待执行的任务,所以第5个任务也会保存到任务队列中;
-
当提交第6个任务的时候,因为当前线程池正在执行的任务数量为3,workQueue 队列中存储的任务数量也满了,这时会判断当前线程池中正在执行的任务的数量是否小于6(maximumPoolSize指定);
-
如果小于 6 ,那么就会新创建一个线程来执行提交的任务 6;
-
执行第7,8个任务的时候,也要判断当前线程池中正在执行的任务数是否小于6(maximumPoolSize指定),如果小于6,那么也会立即新建线程来执行这些提交的任务;
-
此时,6个任务都已经提交完毕,那 workQueue 队列中的等待 任务4 和 任务5 什么时候执行呢?
-
当任务1执行完毕后(10s后),执行任务1的线程并没有被销毁掉,而是获取 workQueue 中的任务4来执行;
-
当任务2执行完毕后,执行任务2的线程也没有被销毁,而是获取 workQueue 中的任务5来执行;
通过上面流程的分析,也就知道了之前案例的输出结果的原因。其实,线程池中会线程执行完毕后,并不会被立刻销毁,线程池中会保留 corePoolSize 数量的线程,当 workQueue 队列中存在任务或者有新提交任务时,那么会通过线程池中已有的线程来执行任务,避免了频繁的线程创建与销毁,而大于 corePoolSize 小于等于 maximumPoolSize 创建的线程,则会在空闲指定时间(keepAliveTime)后进行回收。
5.ThreadPoolExecutor拒绝策略
在上面的测试中,我设置的执行线程总数恰好等于maximumPoolSize[最大线程数] + capacity[队列大小],因此没有出现需要执行拒绝策略的情况,因此在这里,我再增加一个线程,提交9个任务,来演示不同的拒绝策略。
AbortPolicy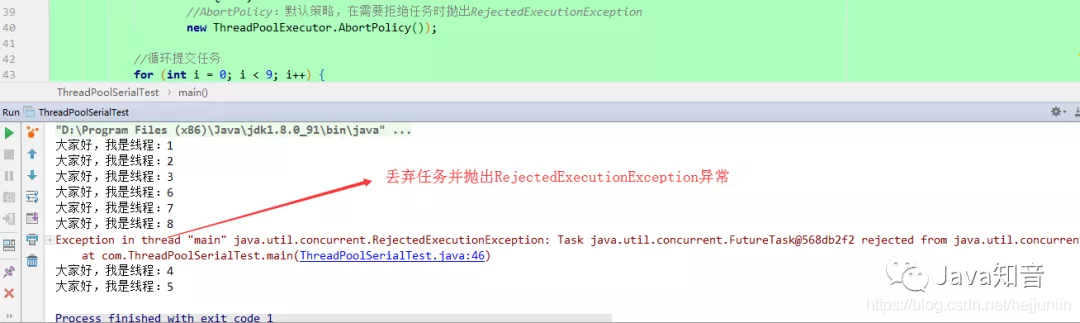
CallerRunsPolicy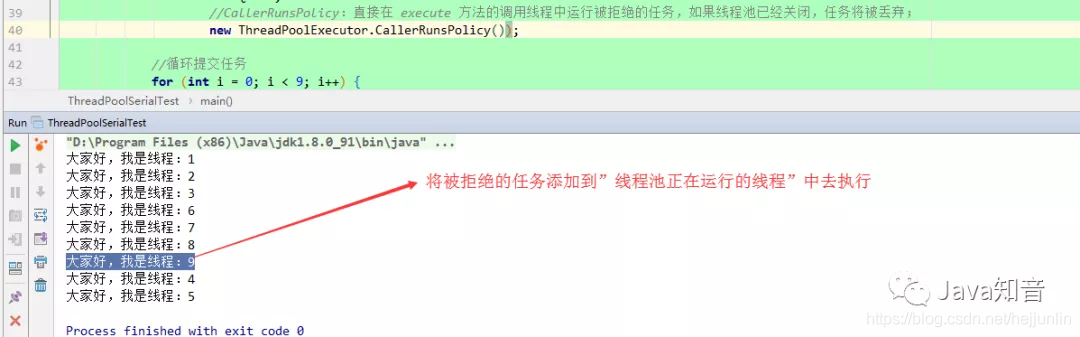
DiscardPolicy
DiscardOldestPolicy
作者:雪山上的蒲公英
共同学习,写下你的评论
评论加载中...
作者其他优质文章


