
本文整理自 Ongaro 在 Youtube 上的视频。
目标
Raft 的目标(或者说是分布式共识算法的目标)是:保证 log 完全相同地复制到多台服务器上。
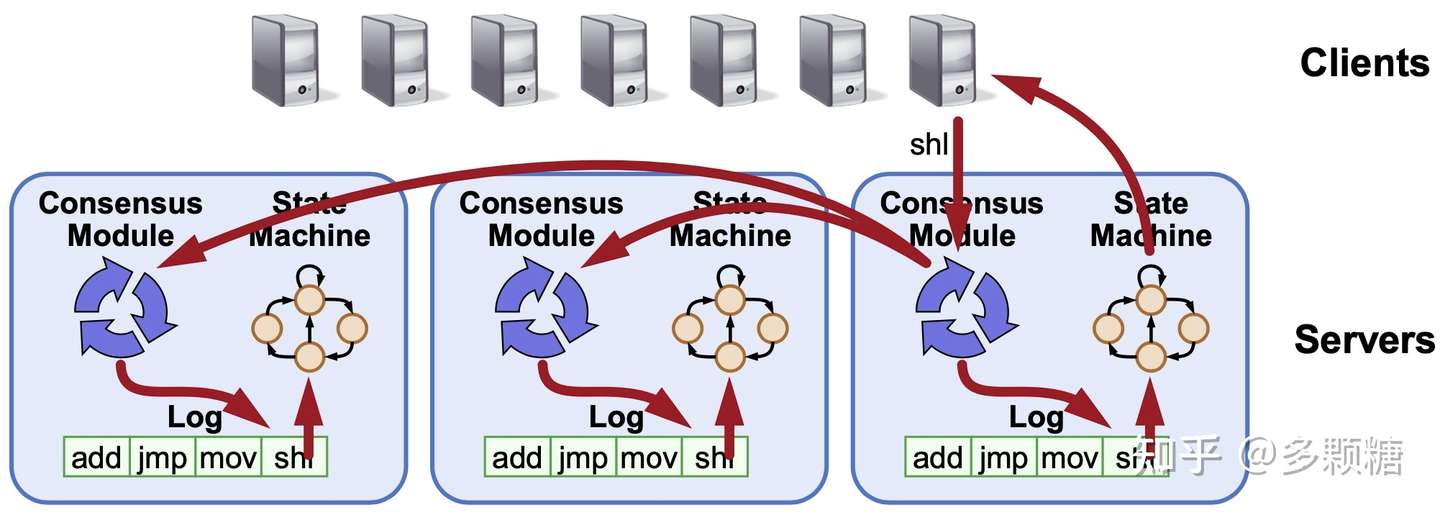
只要每台服务器的日志相同,那么,在不同服务器上的状态机以相同顺序从日志中执行相同的命令,将会产生相同的结果。
共识算法的工作就是管理这些日志。
系统模型
我们假设:
- 服务器可能会宕机、会停止运行过段时间再恢复,但是非拜占庭的(即它的行为是非恶意的,不会篡改数据等);
- 网络通信会中断,消息可能会丢失、延迟或乱序;可能会网络分区;
Raft 是基于 Leader 的共识算法,故主要考虑:
- Leader 正常运行
- Leader 故障,必须选出新的 Leader
优点:只有一个 Leader,简单。
难点:Leader 发生改变时,可能会使系统处于不一致的状态,因此,下一任 Leader 必须进行清理;
我们将从 6 个部分解释 Raft:
- Leader 选举;
- 正常运行:日志复制(最简单的部分);
- Leader 变更时的安全性和一致性(最棘手、最关键的部分);
- 处理旧 Leader:旧的 Leader 并没有真的下线怎么办?
- 客户端交互:实现线性化语义(linearizable semantics);
- 配置变更:如何在集群中增加或删除节点;
开始之前
开始之前需要了解 Raft 的一些术语。
服务器状态
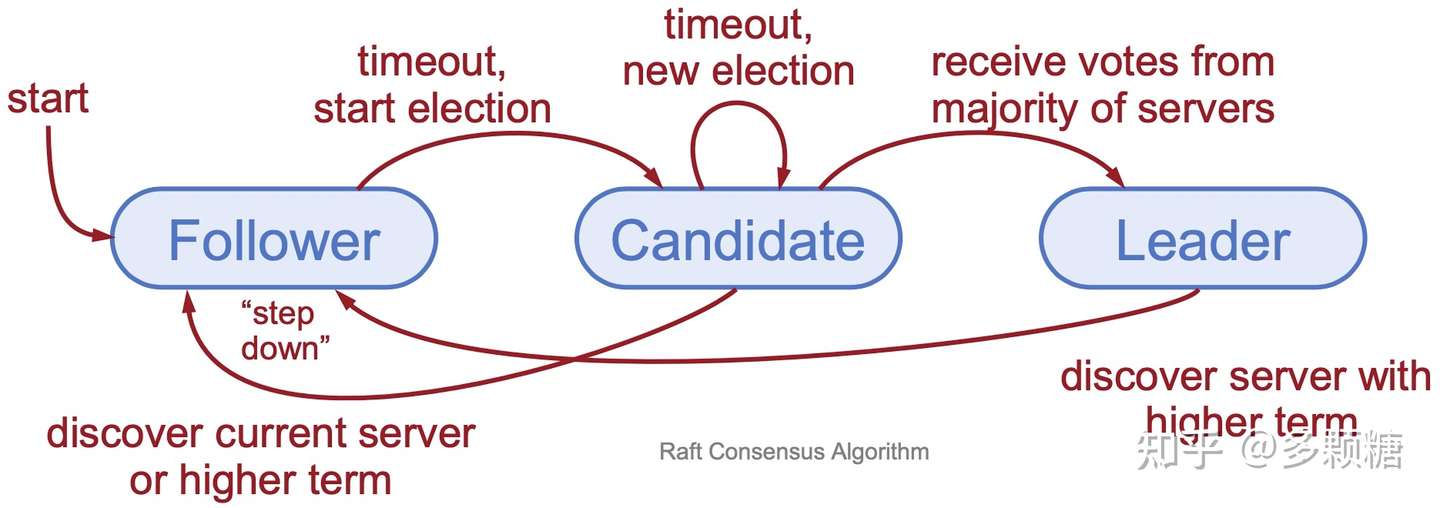
服务器在任意时间只能处于以下三种状态之一:
- Leader:处理所有客户端请求、日志复制。同一时刻最多只能有一个可行的 Leader;
- Follower:完全被动的(不发送 RPC,只响应收到的 RPC)——大多数服务器在大多数情况下处于此状态;
- Candidate:用来选举新的 Leader,处于 Leader 和 Follower 之间的暂时状态;
系统正常运行时,只有一个 Leader,其余都是 Followers.
状态转换图:
任期
时间被划分成一个个的任期(Term),每个任期都由一个数字来表示任期号,任期号单调递增并且永远不会重复。
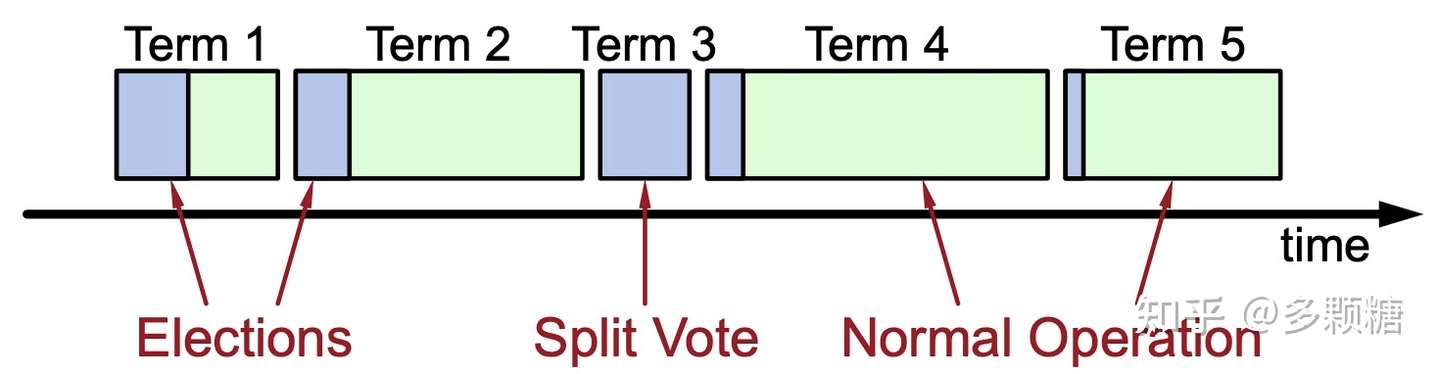
一个正常的任期至少有一个 Leader,通常分为两部分:
- 任期开始时的选举过程;
- 正常运行的部分;
有些任期可能没有选出 Leader(如图 Term 3),这时候会立即进入下一个任期,再次尝试选出一个 Leader。
每个节点维护一个currentTerm变量,表示系统中当前任期。currentTerm必须持久化存储,以便在服务器宕机重启时将其恢复。
**任期非常重要!任期能够帮助 Raft 识别过期的信息。**例如:如果currentTerm = 2的节点与currentTerm = 3的节点通信,我们可以知道第一个节点上的信息是过时的。
我们只使用最新任期的信息。后面我们会遇到各种情况,去检测和消除不是最新任期的信息。
两个 RPC
Raft 中服务器之间所有类型的通信通过两个 RPC 调用:
RequestVote:用于选举;AppendEntries:用于复制 log 和发送心跳;
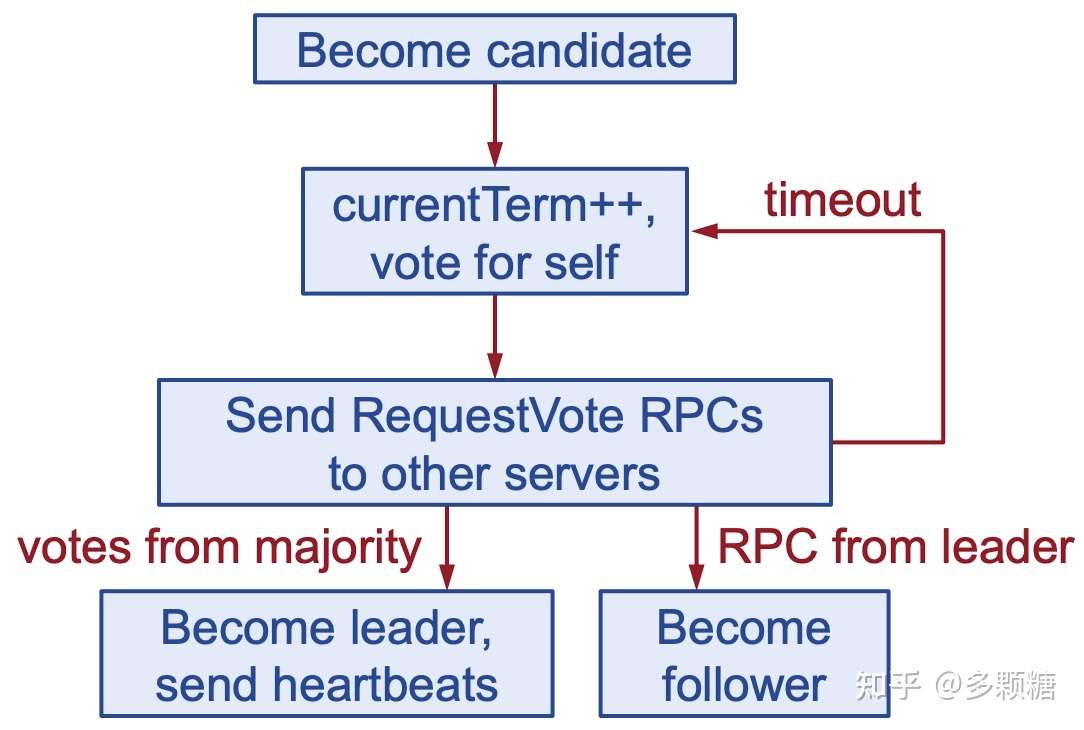
1. Leader 选举
启动
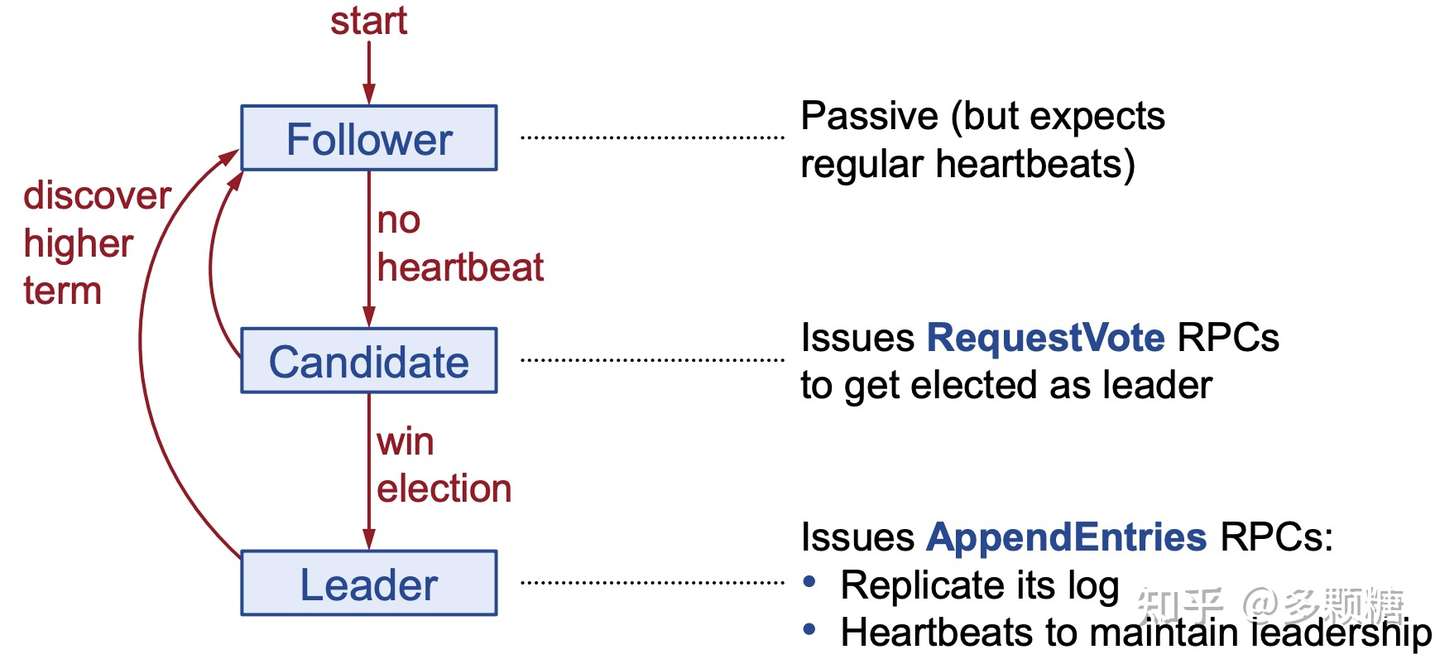
- 节点启动时,都是 Follower 状态;
- Follower 被动地接受 Leader 或 Candidate 的 RPC;
- 所以,如果 Leader 想要保持权威,必须向集群中的其它节点发送心跳包(空的
AppendEntries RPC); - 等待选举超时(
electionTimeout,一般在 100~500ms)后,Follower 没有收到任何 RPC:- Follower 认为集群中没有 Leader
- 开始新的一轮选举
选举
当一个节点开始竞选:
- 增加自己的
currentTerm - 转为 Candidate 状态,其目标是获取超过半数节点的选票,让自己成为 Leader
- 先给自己投一票
- 并行地向集群中其它节点发送
RequestVote RPC索要选票,如果没有收到指定节点的响应,它会反复尝试,直到发生以下三种情况之一:
- 获得超过半数的选票:成为 Leader,并向其它节点发送
AppendEntries心跳; - 收到来自 Leader 的 RPC:转为 Follower;
- 其它两种情况都没发生,没人能够获胜(
electionTimeout已过):增加currentTerm,开始新一轮选举;
流程图如下:
选举安全性
选举过程需要保证两个特性:安全性(safety)和活性(liveness)。
安全性(safety):一个任期内只会有一个 Leader 被选举出来。需要保证:
- 每个节点在同一任期内只能投一次票,它将投给第一个满足条件的投票请求,然后拒绝其它 Candidate 的请求。这需要持久化存储投票信息
votedFor,以便宕机重启后恢复,否则重启后votedFor丢失会导致投给别的节点; - 只有获得超过半数节点的选票才能成为 Leader,也就是说,两个不同的 Candidate 无法在同一任期内都获得超过半数的票;

活性(liveness):确保最终能选出一个 Leader。
问题是:原则上我们可以无限重复分割选票,假如选举同一时间开始,同一时间超时,同一时间再次选举,如此循环。
解决办法很简单:
- 节点随机选择超时时间,通常在 [T, 2T] 之间(T =
electionTimeout) - 这样,节点不太可能再同时开始竞选,先竞选的节点有足够的时间来索要其他节点的选票
- T >> broadcast time(T 远大于广播时间)时效果更佳
2. 日志复制
日志结构
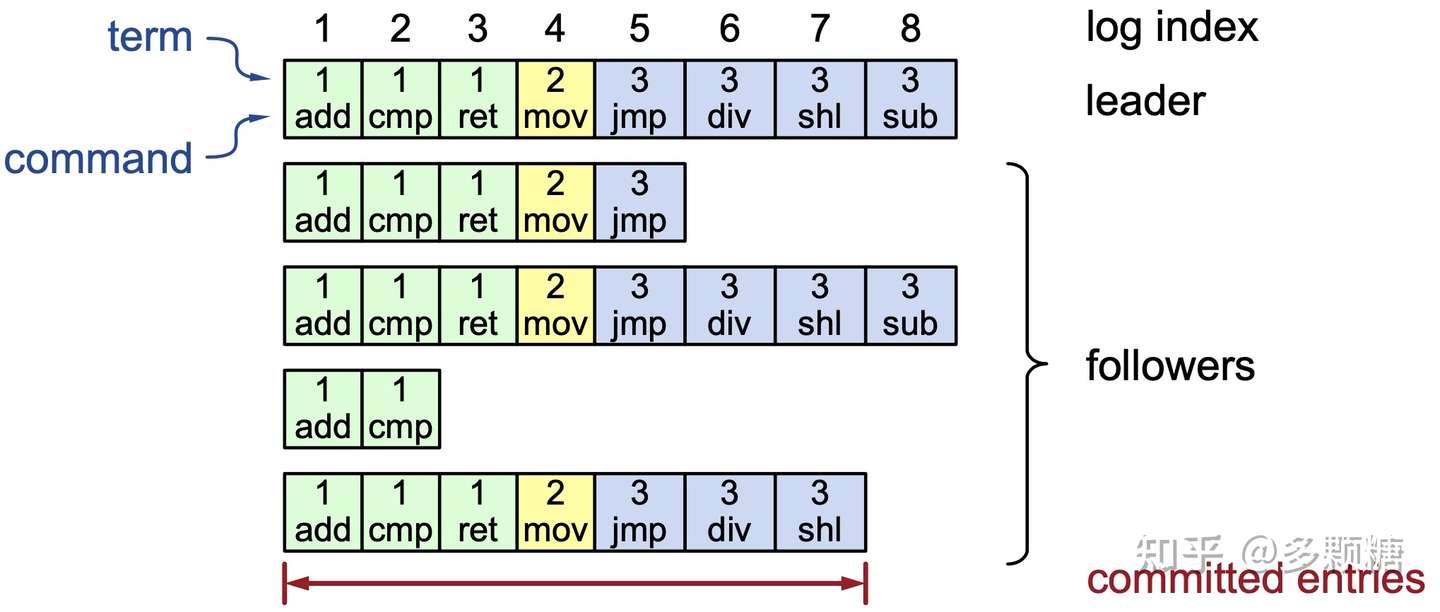
每个节点存储自己的日志副本(log[]),每条日志记录包含:
- 索引:该记录在日志中的位置
- 任期号:该记录首次被创建时的任期号
- 命令
**日志必须持久化存储。**一个节点必须先将记录安全写到磁盘,才能向系统中其他节点返回响应。
如果一条日志记录被存储在超过半数的节点上,我们认为该记录已提交(committed)——这是 Raft 非常重要的特性!如果一条记录已提交,意味着状态机可以安全地执行该记录。
在上图中,第 1-7 条记录被提交,第 8 条尚未提交。
提醒:多数派复制了日志即已提交,这个定义并不精确,我们会在后面稍作修改。
正常运行
- 客户端向 Leader 发送命令,希望该命令被所有状态机执行;
- Leader 先将该命令追加到自己的日志中;
- Leader 并行地向其它节点发送
AppendEntries RPC,等待响应; - 收到超过半数节点的响应,则认为新的日志记录是被提交的:
- Leader 将命令传给自己的状态机,然后向客户端返回响应
- 此外,一旦 Leader 知道一条记录被提交了,将在后续的
AppendEntries RPC中通知已经提交记录的 Followers - Follower 将已提交的命令传给自己的状态机
- 如果 Follower 宕机/超时:Leader 将反复尝试发送 RPC;
- 性能优化:Leader 不必等待每个 Follower 做出响应,只需要超过半数的成功响应(确保日志记录已经存储在超过半数的节点上)——一个很慢的节点不会使系统变慢,因为 Leader 不必等他;
日志一致性
Raft 尝试在集群中保持日志较高的一致性。
Raft 日志的 index 和 term 唯一标示一条日志记录。(这非常重要!!!)
- 如果两个节点的日志在相同的索引位置上的任期号相同,则认为他们具有一样的命令;从头到这个索引位置之间的日志完全相同;
- 如果给定的记录已提交,那么所有前面的记录也已提交。
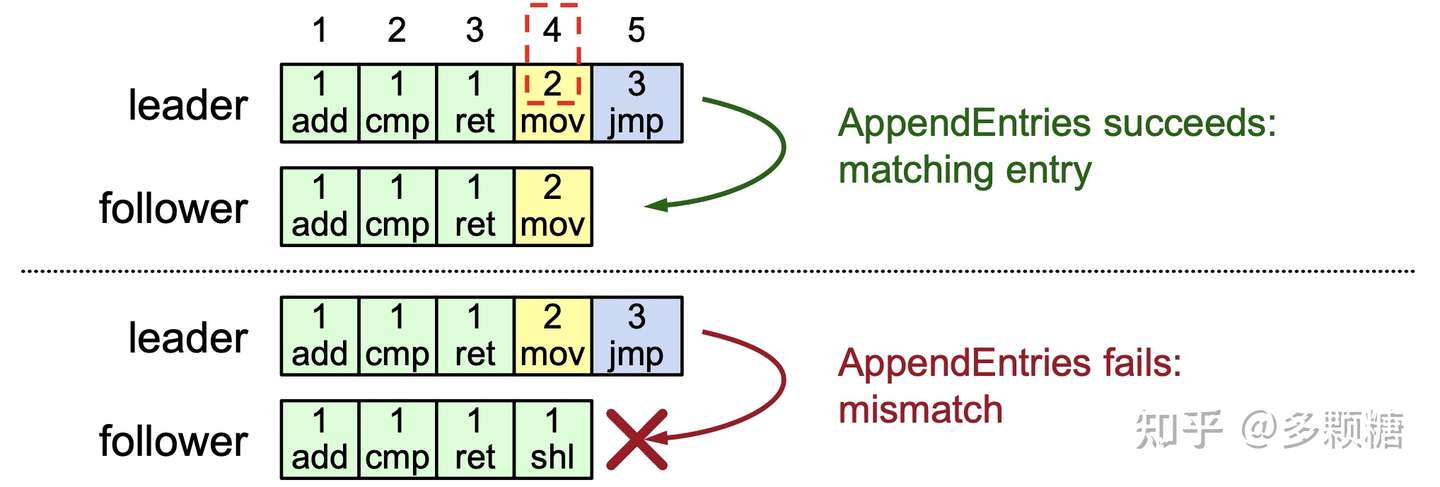
**AppendEntries**一致性检查
Raft 通过AppendEntries RPC来检测这两个属性。
- 对于每个
AppendEntries RPC包含新日志记录之前那条记录的索引(prevLogIndex)和任期(prevLogTerm); - Follower 检查自己的 index 和 term 是否与
prevLogIndex和prevLogTerm匹配,匹配则接收该记录;否则拒绝;
3. Leader 更替
当新的 Leader 上任后,日志可能不会非常干净,因为前一任领导可能在完成日志复制之前就宕机了。Raft 对此的处理方式是:无需采取任何特殊处理。
当新 Leader 上任后,他不会立即进行任何清理操作,他将会在正常运行期间进行清理。
原因是当一个新的 Leader 上任时,往往意味着有机器故障了,那些机器可能宕机或网络不通,所以没有办法立即清理他们的日志。在机器恢复运行之前,我们必须保证系统正常运行。
**大前提是 Raft 假设了 Leader 的日志始终是对的。**所以 Leader 要做的是,随着时间推移,让所有 Follower 的日志最终都与其匹配。
但与此同时,Leader 也可能在完成这项工作之前故障,日志会在一段时间内堆积起来,从而造成看起来相当混乱的情况,如下所示:

因为我们已经知道 index 和 term 是日志记录的唯一标识符,这里不再显示日志包含的命令,下同。
如图,这种情况可能出现在 S4 和 S5 是任期 2、3、4 的 Leader,但不知何故,他们没有复制自己的日志记录就崩溃了,系统分区了一段时间,S1、S2、S3 轮流成为了任期 5、6、7 的 Leader,但无法与 S4、S5 通信以进行日志清理——所以我们看到的日志非常混乱。
唯一重要的是,索引 1-3 之间的记录是已提交的(已存在多数派节点),因此我们必须确保留下它们。
其它日志都是未提交的,我们还没有将这些命令传递给状态机,也没有客户端会收到这些执行的结果,所以不管是保留还是丢弃它们都无关紧要。
安全性
一旦状态机执行了一条日志里的命令,必须确保其它状态机在同样索引的位置不会执行不同的命令。
Raft 安全性(Safety):如果某条日志记录在某个任期号已提交,那么这条记录必然出现在更大任期号的未来 Leader 的日志中。

这保证了安全性要求:
- Leader 不会覆盖日志中的记录;
- 只有 Leader 的日志中的记录才能被提交;
- 在应用到状态机之前,日志必须先被提交;
这决定我们要修改选举程序:
- 如果节点的日志中没有正确的内容,需要避免其成为 Leader;
- 稍微修改 committed 的定义(即前面提到的要稍作修改):前面说多数派存储即是已提交的,但在某些时候,我们必须延迟提交日志记录,直到我们知道这条记录是安全的,所谓安全的,就是我们认为后续 Leader 也会有这条日志。
延迟提交,选出最佳 Leader
问题来了:我们如何确保选出了一个很好地保存了所有已提交日志的 Leader ?
这有点棘手,举个例子:假设我们要在下面的集群中选出一个新 Leader,但此时第三台服务器不可用。
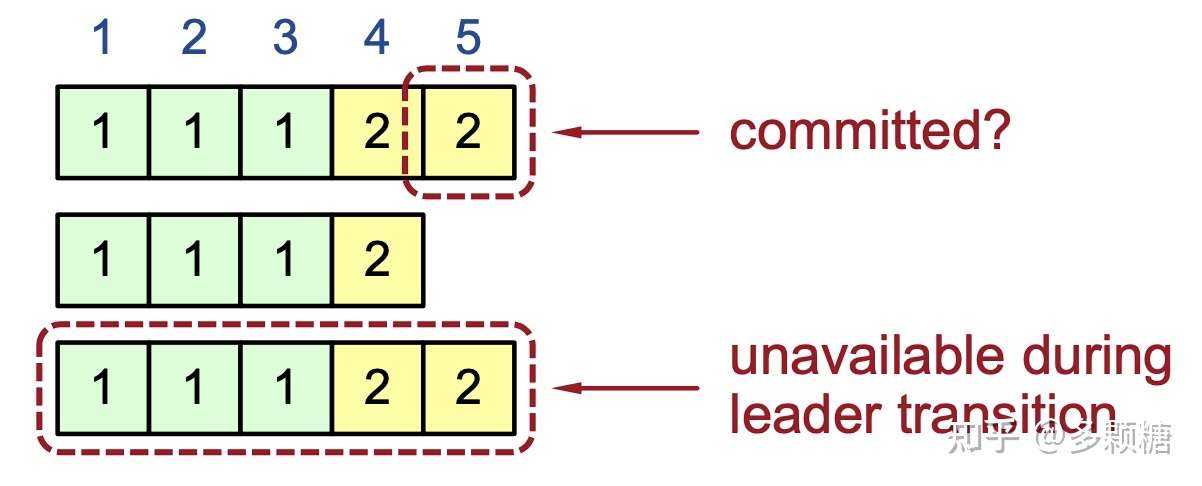
这种情况下,仅看前两个节点的日志我们无法确认是否达成多数派,故无法确认第五条日志是否已提交。
那怎么办呢?
通过比较日志,在选举期间,选择最有可能包含所有已提交的日志:
- Candidate 在
RequestVote RPCs中包含日志信息(最后一条记录的 index 和 term,记为lastIndex和lastTerm); - 收到此投票请求的服务器 V 将比较谁的日志更完整:
(lastTermV > lastTermC) ||(lastTermV == lastTermC) && (lastIndexV > lastIndexC)将拒绝投票;(即:V 的任期比 C 的任期新,或任期相同但 V 的日志比 C 的日志更完整); - 无论谁赢得选举,可以确保 Leader 和超过半数投票给它的节点中拥有最完整的日志——最完整的意思就是 index 和 term 这对唯一标识是最大的。
举个例子
Case 1: Leader 决定提交日志
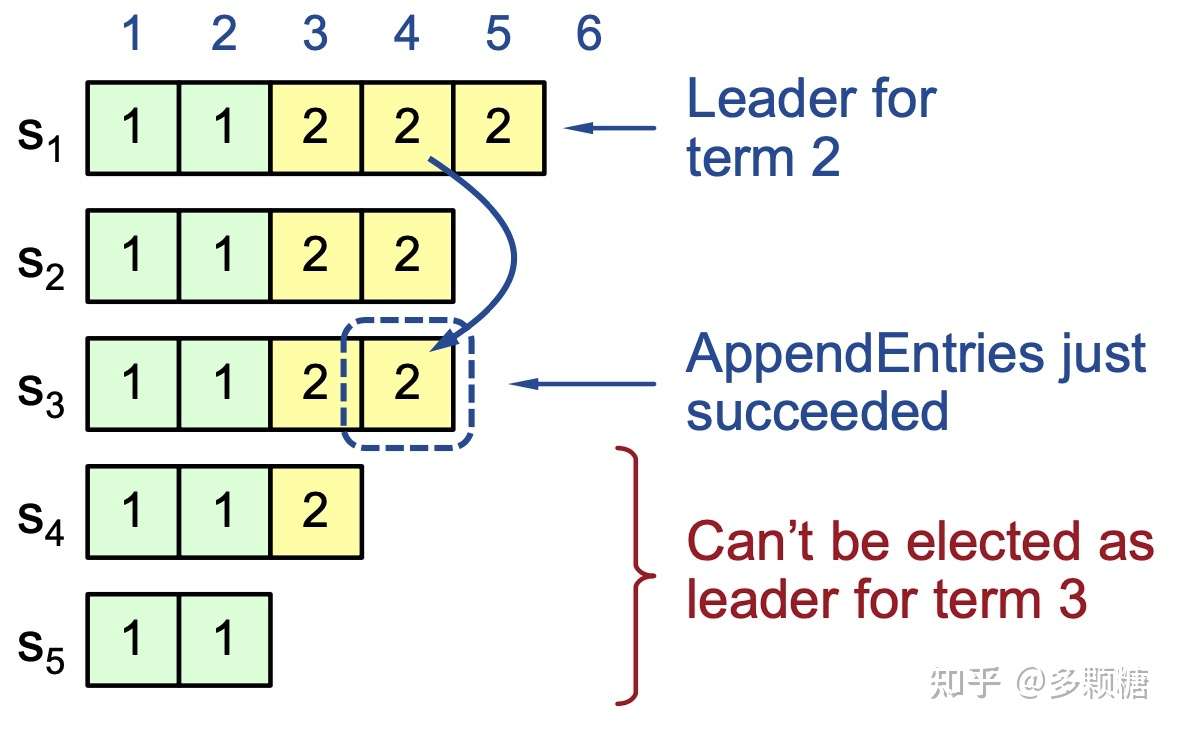
任期 2 的 Leader S1 的 index = 4 日志刚刚被复制到 S3,并且 Leader 可以看到 index = 4 已复制到超过半数的服务器,那么该日志可以提交,并且安全地应用到状态机。
现在,这条记录是安全的,下一任期的 Leader 必须包含此记录,因此 S4 和 S5 都不可能从其它节点那里获得选票:S5 任期太旧,S4 日志太短。
只有前三台中的一台可以成为新的 Leader——S1 当然可以,S2、S3 也可以通过获取 S4 和 S5 的选票成为 Leader。
Case 2: Leader 试图提交之前任期的日志
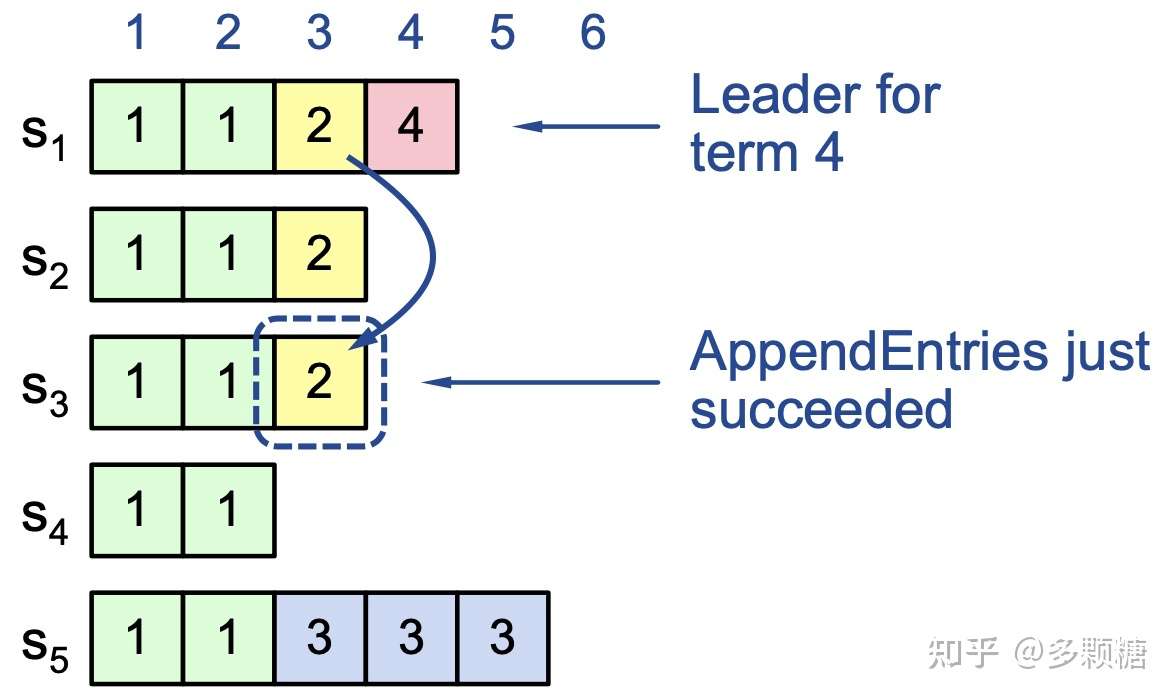
如图所示的情况,在任期 2 时记录仅写在 S1 和 S2 两个节点上,由于某种原因,任期 3 的 Leader S5 并不知道这些记录,S5 创建了自己的三条记录然后宕机了,然后任期 4 的 Leader S1 被选出,S1 试图与其它服务器的日志进行匹配。因此它复制了任期 2 的日志到 S3。
此时 index=3 的记录时是不安全的。
因为 S1 可能在此时宕机,然后 S5 可能从 S2、S3、S4 获得选票成为任期 5 的 Leader。一旦 S5 成为新 Leader,它将覆盖 index=3-5 的日志,S1-S3 的这些记录都将消失。
我们还要需要一条新的规则,来处理这种情况。
新的 Commit 规则
新的选举不足以保证日志安全,我们还需要继续修改 commit 规则。
Leader 要提交一条日志:
- 日志必须存储在超过半数的节点上;
- Leader 必须看到:超过半数的节点上还必须存储着至少一条自己任期内的日志;
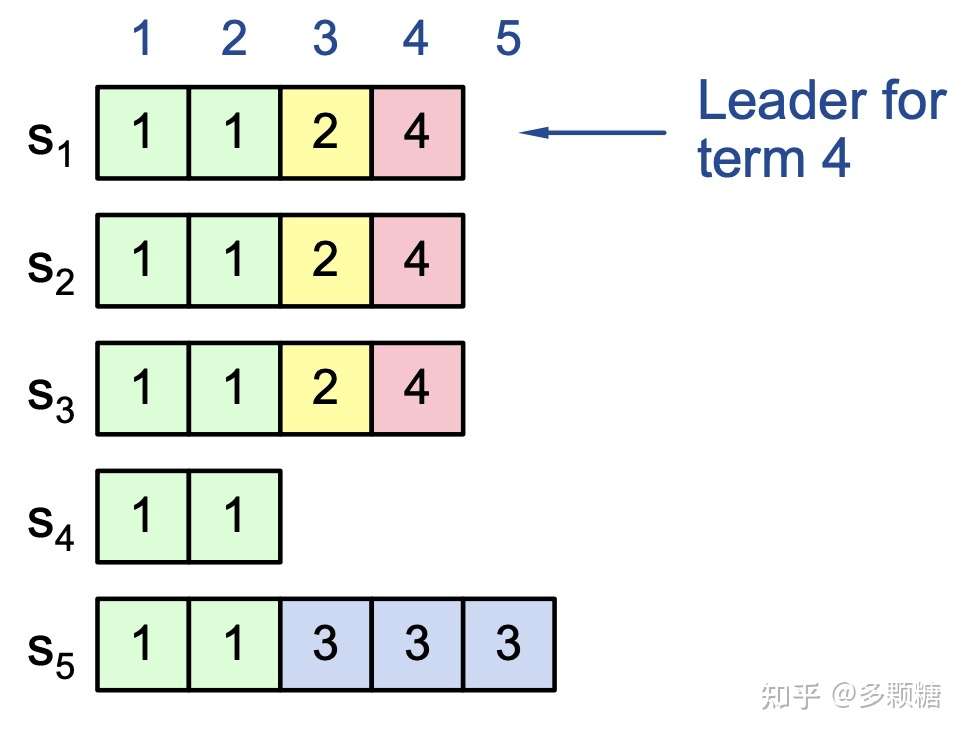
如图,回到上面的 Case 2: 当 index = 3 & term = 2 被复制到 S3 时,它还不能提交该记录,必须等到 term = 4 的记录存储在超过半数的节点上,此时 index = 3 和 index = 4 可以认为是已提交。
此时 S5 无法赢得选举了,它无法从 S1-S3 获得选票。
结合新的选举规则和 commit 规则,我们可以保证 Raft 的安全性。
日志不一致
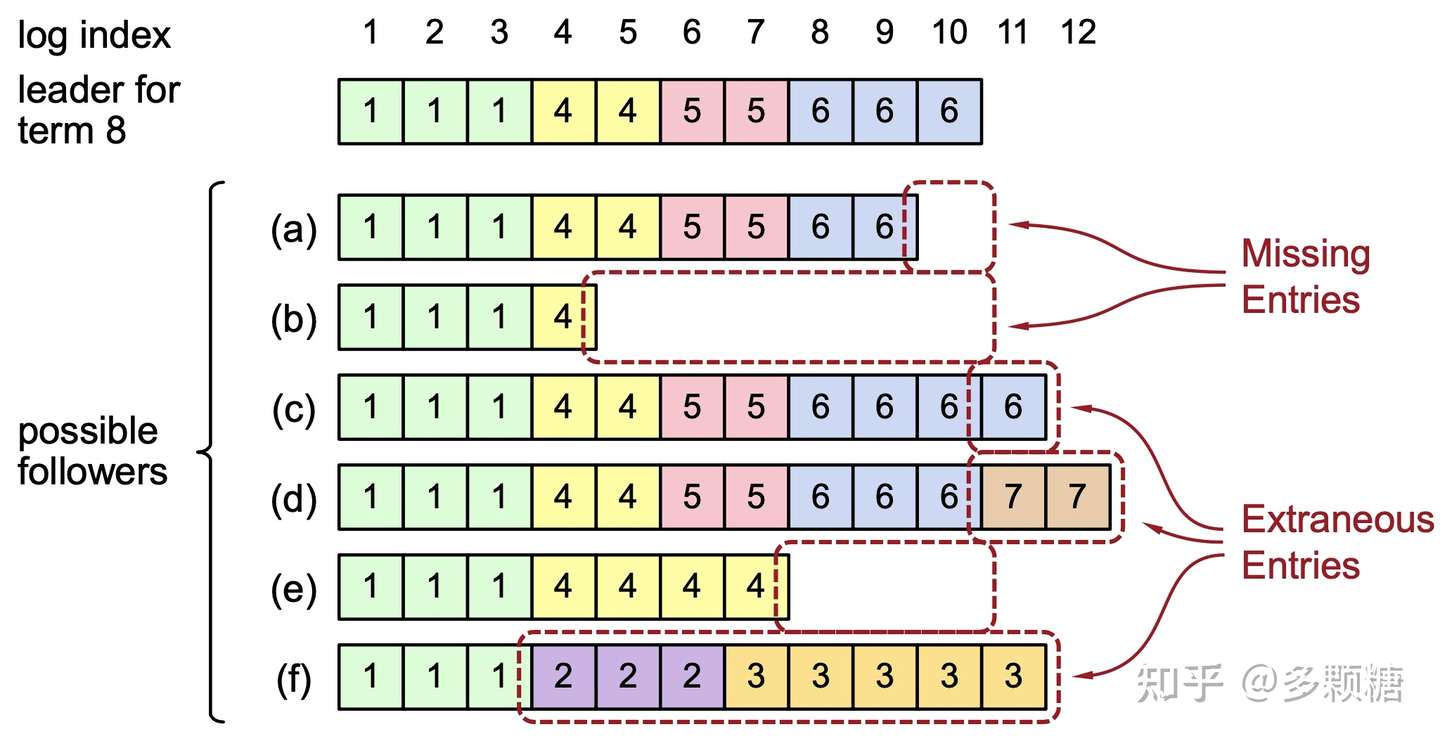
Leader 变更可能导致日志的不一致,这里展示一种可能的情况。
可以从图中看出,Raft 集群中通常有两种不一致的日志:
- 缺失的记录(Missing Entries);
- 多出来的记录(Extraneous Entries);
我们要做的就是清理这两种日志。
修复 Follower 日志
新的 Leader 必须使 Follower 的日志与自己的日志保持一致,通过:
- 删除 Extraneous Entries;
- 补齐 Missing Entries;
Leader 为每个 Follower 保存nextIndex:
- 下一个要发送给 Follower 的日志索引;
- 初始化为: 1 + Leader 最后一条日志的索引;
Leader 通过nextIndex来修复日志。当AppendEntries RPC一致性检查失败,递减nextIndex并重试。如下图所示:
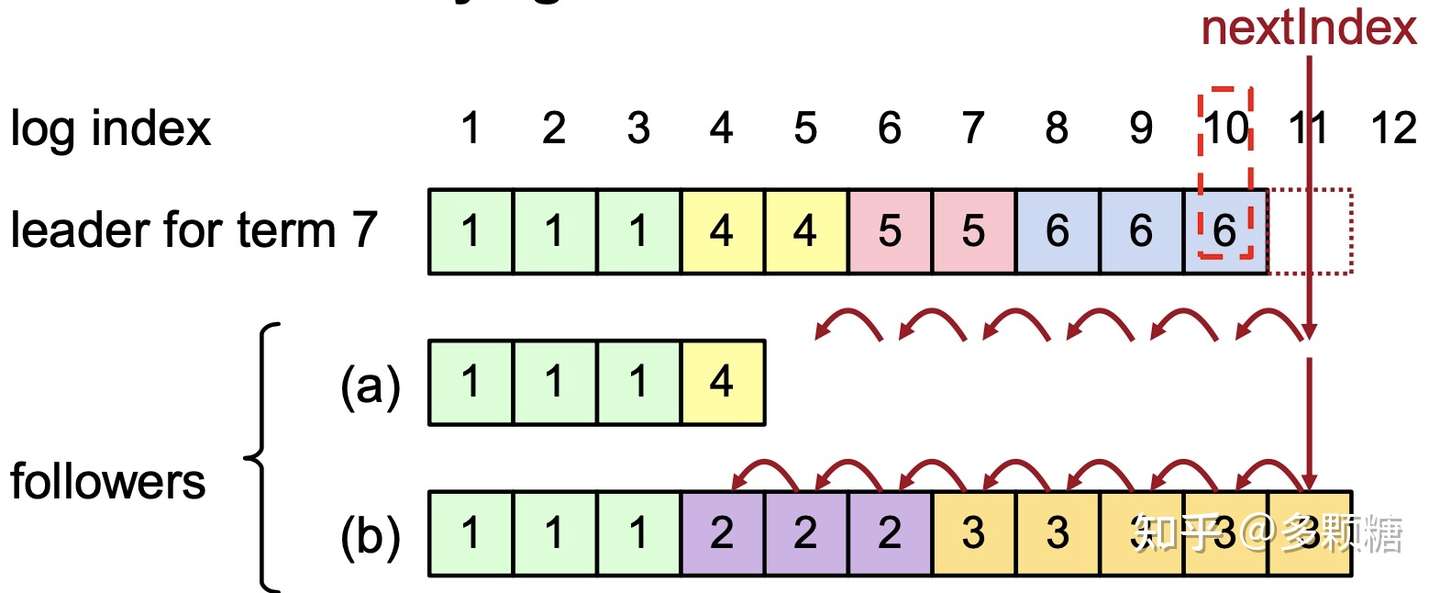
对于 a:
- 一开始
nextIndex= 11,带上日志 index = 10 & term = 6,检查失败; nextIndex= 10,带上日志 index = 9 & term = 6,检查失败;- 如此反复,直到
nextIndex= 5,带上日志 index = 4 & term = 4,该日志现在匹配,会在 a 中补齐 Leader 的日志。如此往下补齐。
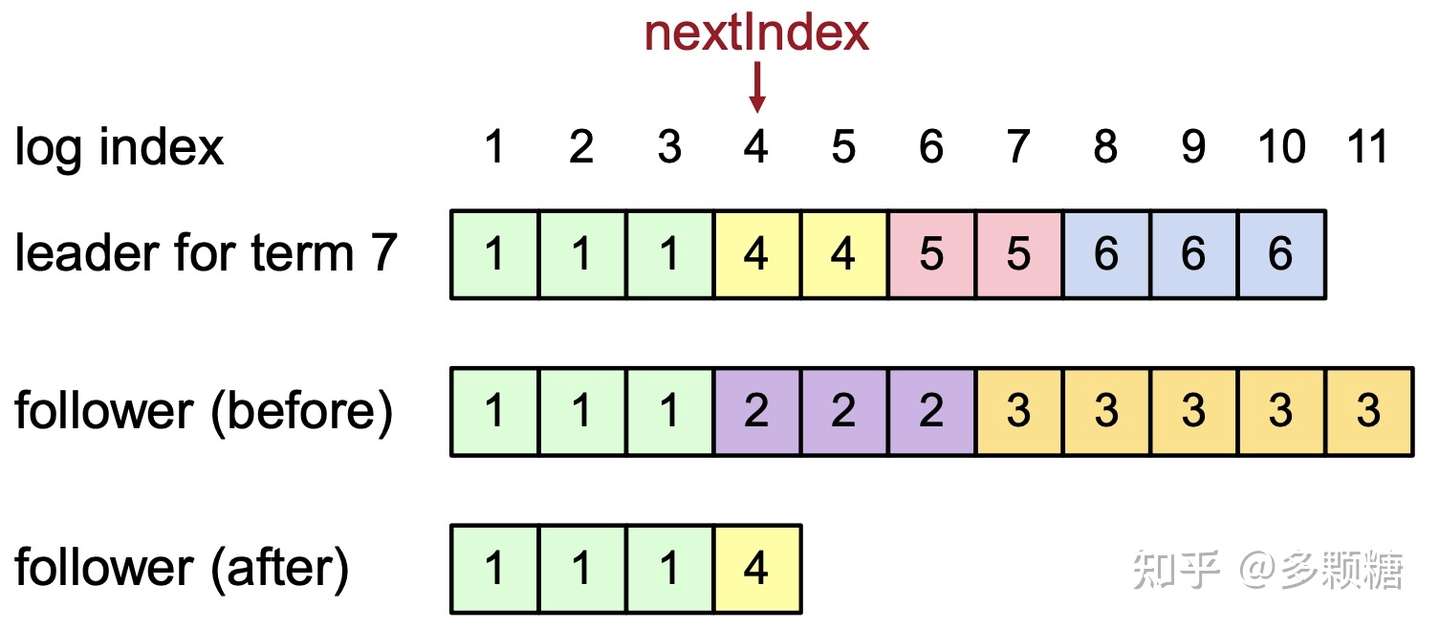
对于 b:
会一直检查到nextIndex= 4 才匹配。值得注意的是,对于 b 这种情况,当 Follower 覆盖不一致的日志时,它将删除所有后续的日志记录(任何无关紧要的记录之后的记录也都是无关紧要的)。如下图所示:
4. 处理旧 Leader
实际上,老的 Leader 可能不会马上消失,例如:网络分区将 Leader 与集群的其余部分分隔,其余部分选举出了一个新的 Leader。问题在于,如果老的 Leader 重新连接,也不知道新的 Leader 已经被选出来,它会尝试作为 Leader 继续提交日志。此时如果有客户端向老 Leader 发送请求,老的 Leader 会尝试存储该命令并向其它节点复制日志——我们必须阻止这种情况发生。
任期就是用来发现过时的 Leader(和 Candidates):
- 每个 RPC 都包含发送方的任期;
- 如果发送方的任期太老,无论哪个过程,RPC 都会被拒绝,发送方转变到 Follower 并更新其任期;
- 如果接收方的任期太老,接收方将转为 Follower,更新它的任期,然后正常的处理 RPC;
由于新 Leader 的选举会更新超过半数服务器的任期,旧的 Leader 不能提交新的日志,因为它会联系至少一台多数派集群的节点,然后发现自己任期太老,会转为 Follower 继续工作。
这里不打算继续讨论别的极端情况。
5. 客户端协议
客户端只将命令发送到 Leader:
- 如果客户端不知道 Leader 是谁,它会和任意一台服务器通信;
- 如果通信的节点不是 Leader,它会告诉客户端 Leader 是谁;
Leader 直到将命令记录、提交和执行到状态机之前,不会做出响应。
这里的问题是如果 Leader 宕机会导致请求超时:
- 客户端重新发出命令到其他服务器上,最终重定向到新的 Leader
- 用新的 Leader 重试请求,直到命令被执行
这留下了一个命令可能被执行两次的风险——Leader 可能在执行命令之后但响应客户端之前宕机,此时客户端再去寻找下一个 Leader,同一个命令就会被执行两次——这是不可接受的!
解决办法是:客户端发送给 Leader 的每个命令都带上一个唯一 id
- Leader 将唯一 id 写到日志记录中
- 在 Leader 接受命令之前,先检查其日志中是否已经具有该 id
- 如果 id 在日志中,说明是重复的请求,则忽略新的命令,返回旧命令的响应
每个命令只会被执行一次,这就是所谓的线性化的关键要素。
6. 配置变更
随着时间推移,会有机器故障需要我们去替换它,或者修改节点数量,需要有一些机制来变更系统配置,并且是安全、自动的方式,无需停止系统。
系统配置是指:
- 每台服务器的 id 和地址
- 系统配置信息是非常重要的,它决定了多数派的组成
首先要意识到,我们不能直接从旧配置切换到新配置,这可能会导致矛盾的多数派。
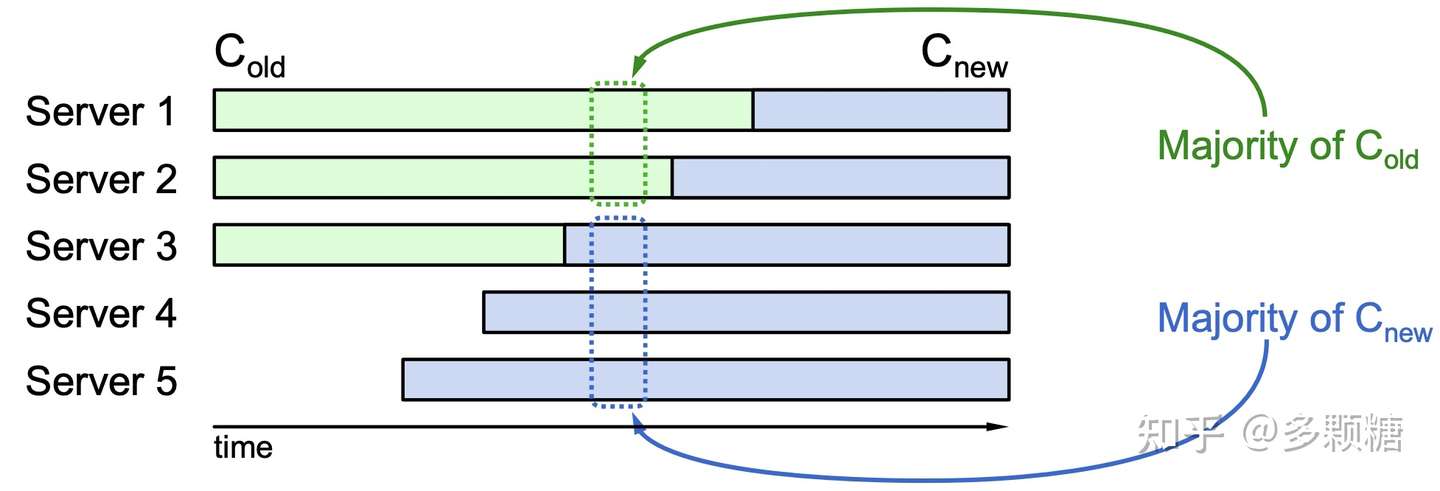
如图,系统以三台服务器的配置运行着,此时我们要添加两台服务器。如果我们直接修改配置,他们可能无法完全在同一时间做到配置切换,这会导致 S1 和 S2 形成旧集群的多数派,而同一时间 S3-S5 已经切换到新配置,这会产生两个集群。
这说明我们必须使用一个两阶段(two-phase)协议。
如果有人告诉你,他可以在分布式系统中一个阶段就做出决策,你应该非常认真地询问他,因为他要么错了,要么发现了世界上所有人都不知道的东西。
共同一致(Joint Consensus)
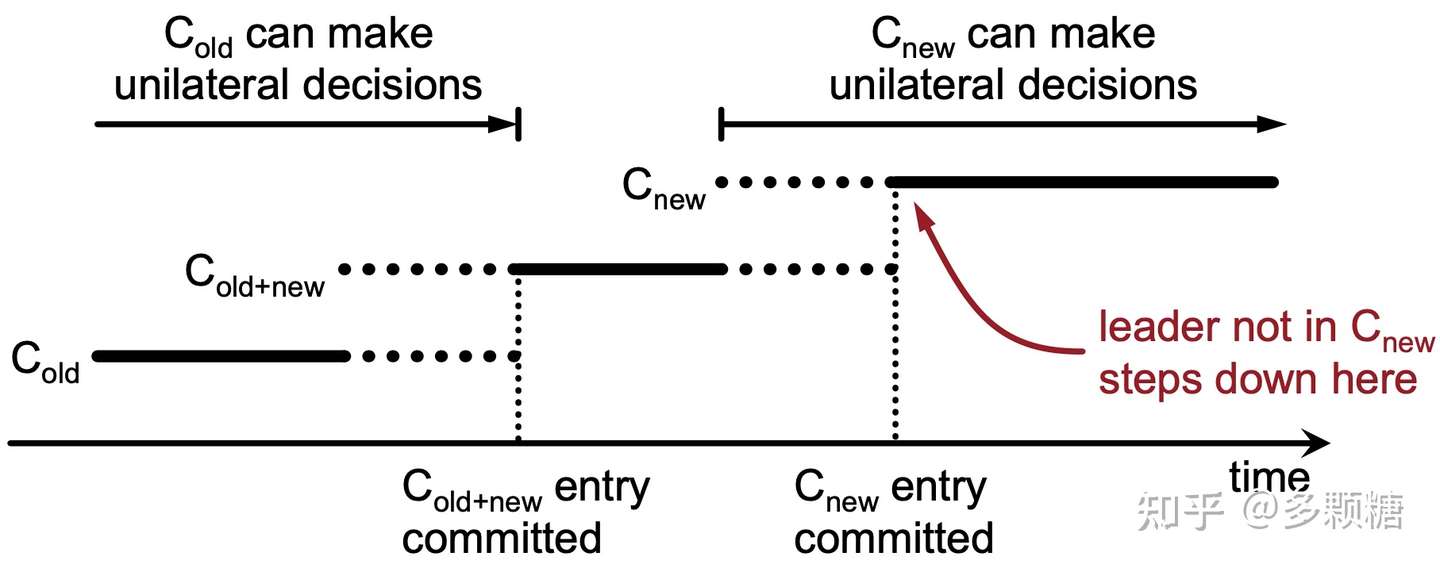
Raft 通过共同一致(Joint Consensus)来完成两阶段协议,即:新、旧两种配置上都获得多数派选票。
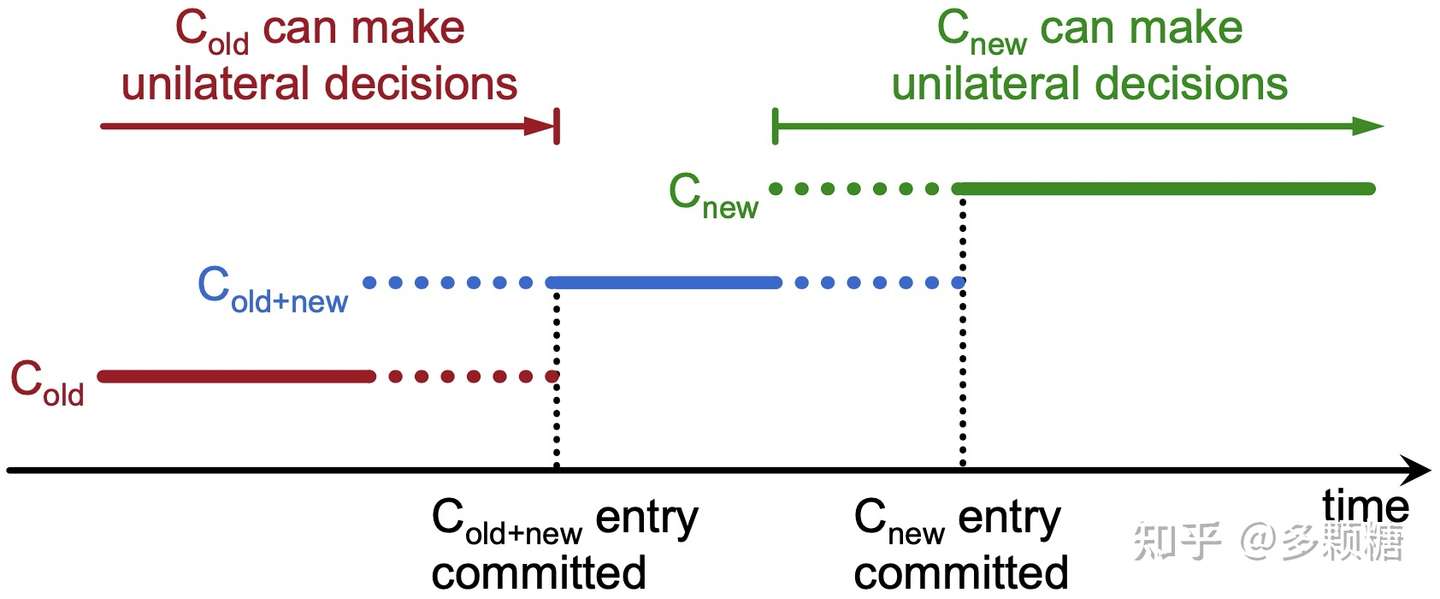
第一阶段:
- Leader 收到 Cnew 的配置变更请求后,先写入一条 Cold+new 的日志,配置变更立即生效,然后将日志通过
AppendEntries RPC复制到 Follower 中,收到该 Cold+new 的节点立即应用该配置作为当前节点的配置; - Cold+new 日志复制到多数派节点上时,Cold+new 的日志已提交;
Cold+new 日志已提交保证了后续任何 Leader 一定有 Cold+new 日志,Leader 选举过程必须获得旧配置中的多数派和新配置中的多数派同时投票。
第二阶段:
- Cold+new 日志已提交后,立即写入一条 Cnew 的日志,并将该日志通过
AppendEntries RPC复制到 Follower 中,收到 Cnew 的节点立即应用该配置作为当前节点的配置; - Cnew 日志复制到多数派节点上时,Cnew 的日志已提交;在 Cnew 日志提交以后,后续的配置都基于 Cnew 了;
共同学习,写下你的评论
评论加载中...
作者其他优质文章



