
很多朋友在工作或者面试的时候,经常会碰到关于并发容器的问题:
- 并发容器选择问题,Java中有各式各样的并发容器,我应该选择哪一个?
- 碰到字典类型的数据结构选型时,我应该选择 HashMap 还是 ConcurrentHashMap?
- 面试中也经常会问到,Vector 是线程安全的吗?你在工作中会用到吗?为什么?
- 高并发场景下,可以使用 HashMap吗?
- 有没有看过JDK中 ConcurrentHashMap 的源码?说说它的实现原理?Java8中的实现和Java8之前的实现有什么不同?
这篇文章,学习有哪些已经过时被淘汰的同步容器vector 、 Hashtable 、SynchronizedList 与 SynchronizedMap ,通过源码分析,说说为什么它们是线程安全的,可为什么又被淘汰了?接着,学习线程安全的同步容器 ConcurrentHashMap ,它的API如何使用,通过源码剖析它的数据结构,它的核心方法的实现细节,为什么它能做到保证线程安全的同时,又能够有很好的性能。
由于篇幅问题,这篇文章分析的是 Java7 中 ConcurrentHashMap 的实现原理。
1、被淘汰的同步容器
1.1 vector 与 Hashtable
vector
线程安全
>所有的方法上都加了锁 synchronized ,在多线程下,性能不好。
public class VectorDemo {
public static void main(String[] args) {
Vector vector = new Vector<>();
vector.add("test");
System.out.println(vector.get(0));
}
}
通过 Vector 源码,可以看到,在所有涉及到 Vector 中元素读写操作的方法上,都加上了 synchronized 关键字。
Vector 源码
public class Vector
extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable{
...
//add方法添加 synchronized 关键字
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
//get方法添加 synchronized 关键字
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
...
}
Hashtable
用法类似 HashMap,也是线程安全。
>类似 Vector,也是在方法上加锁 synchronized 进行实现的
public class HashtableDemo {
public static void main(String[] args) {
Hashtable hashtable = new Hashtable<>();
hashtable.put("k1", "v1");
System.out.println(hashtable.get("k1"));
}
}
通过 Hashtable 源码,可以看到,在所有涉及到 Hashtable 中 Entry 读写操作的方法上,也都加上了 synchronized 关键字。
Hashtable 源码
//put方法添加 synchronized 关键字
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry entry = (Entry)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
//get方法添加 synchronized 关键字
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
1.2 SynchronizedList 与 SynchronizedMap
ArrayList 与 HashMap是线程不安全的,可以使用如下的方法使得安全。
Collections.synchronizedList(List) 和 Collections.synchronizedMap(Map)
为什么不用 Collections.synchronizedList 和 Collections.synchronizedMap ,因为这两个都是对方法块加锁( synchronized )。
Collections.synchronizedList(List) 分析
Collections.synchronizedList(List) 方法返回的是 SynchronizedList 或者 SynchronizedRandomAccessList,而 SynchronizedRandomAccessList 继承 SynchronizedList 。SynchronizedList 中所有的方法,都在方法的代码块上加上锁( synchronized )。
Collections.synchronizedList(List) 源码
public class Collections {
...
// 将 List 转为线程安全的 SynchronizedList
public static List synchronizedList(List list) {
return (list instanceof RandomAccess ?
new SynchronizedRandomAccessList<>(list) :
new SynchronizedList<>(list));
}
/**
* `SynchronizedList` 中所有的方法,都在方法的代码块上加上锁( `synchronized` )
*/
static class SynchronizedList
extends SynchronizedCollection
implements List {
public E get(int index) {
synchronized (mutex) {return list.get(index);}
}
public E set(int index, E element) {
synchronized (mutex) {return list.set(index, element);}
}
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}
public E remove(int index) {
synchronized (mutex) {return list.remove(index);}
}
...
}
/**
* SynchronizedRandomAccessList 继承 SynchronizedList
*/
static class SynchronizedRandomAccessList
extends SynchronizedList
implements RandomAccess {
....
}
...
}
Collections.synchronizedMap(Map) 分析
Collections.synchronizedMap(Map) 方法返回的是 SynchronizedMap, SynchronizedMap 中所有的方法,都在方法的代码块上加上锁( synchronized )。
Collections.synchronizedMap(Map) 源码
public class Collections {
...
// 将 Map 转为线程安全的 SynchronizedMap
public static Map synchronizedMap(Map m) {
return new SynchronizedMap<>(m);
}
// `SynchronizedMap` 中所有的方法,都在方法的代码块上加上锁( `synchronized` )
private static class SynchronizedMap
implements Map, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
...
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
public V remove(Object key) {
synchronized (mutex) {return m.remove(key);}
}
public void putAll(Map<? extends K, ? extends V> map) {
synchronized (mutex) {m.putAll(map);}
}
public void clear() {
synchronized (mutex) {m.clear();}
}
...
}
...
}
从源码可以看到,vector 、 Hashtable 、SynchronizedList 与 SynchronizedMap 同步容器是通过把所有对容器的状态访问都通过加 synchronized 锁来实现串行化访问,最终实现容器的线程安全,这种方式的缺点就是严重降低了容器的并发性,但在线程竞争激烈的情况下HashTable的效率非常低下。以HashTable举例:因为当一个线程访问 HashTable 的同步方法,其他线程也访问 HashTable 的同步方法时,会进入阻塞或轮询状态。如线程1使用 put 进行元素添加,线程2不但不能使用 put 方法添加元素,也不能使用 get 方法来获取元素,所以竞争越激烈效率越低。。
提示: Hashmap多线程环境下,线程不安全。Hashmap 多线程会导致 HashMap 的 Entry 链表形成环形数据结构(环形链表),一旦形成环形数据结构,Entry 的 next 节点 永远不为空,获取 Entry 就会产生死循环。
2、ConcurrentHashMap 使用
ConcurrentHashMap 实现原理是怎么样的? 或者 ConcurrentHashMap 如何在保证高并发下线程安全的同时实现了性能提升?ConcurrentHashMap 允许多个修改操作并发进行,其关键在于使用了 锁分离 技术。它使用了多个锁来控制对 hash表 的不同部分进行的修改。内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,只要多个修改操作发生在不同的段上,它们就可以并发进行。
ConcurrentHashMap 方法
| 方法 | 描述 |
|---|---|
| void clear() | 清空 map |
| boolean contains(Object value) boolean containsValue(Object value) |
如果 map 中存在某个 key 存放的值 equals 入参 value,返回true, 否则返回 false |
| boolean containsKey(Object key) | 如果 map 中存在入参 key,返回true,否则返回 false |
| V get(Object key) | 返回 key 对应的 value,不存在则返回null |
| boolean isEmpty() | map为空(元素个数为0)返回 true,否则 false |
| KeySetView keySet() | 返回 map 中所有的 key Set集合 |
| Collection values() | 返回 map 中所有的 values Collection集合 |
| V put(K key, V value) | 在map中将 key 映射到的指定value。key 和 value 都不能为null。 返回 key 在map 中映射的前一个值,没有则返回 null |
| void putAll(Map<? extends K, ? extends V> m) | 遍历 m 中的所有 Entry,一个一个地调用 V put(K key, V value) 添加到 map 中 |
| V putIfAbsent(K key, V value) | 只有当 map 中不存在 key,才 put(K key, V value) , key 和 value 都不能为null。 |
| int size() | map 的 大小 |
ConcurrentHashMap 的使用上类似 HashMap 只是 ConcurrentHashMap的所有操作是线程安全的,而 HashMap 的读操作是线程安全,写操作是非线程安全的。
还有一个区别是,ConcurrentHashMap的put操作 key 和 value 都不能为null,否则会抛出 NullPointerException,而 HashMap 的put操作允许 key 和 value 为null。
下面,我们分别从 JDK7 和 JDK8 两个Java版本看看 ConcurrentHashMap 源码。
3 JDK7 ConcurrentHashMap 源码分析
JDK7 ConcurrentHashMap 使用 Segment 数组(分段数组),每个 Segment (段)都单独有一个 table,然后 table是 HashEntry 数组,每个 HashEntry 元素又单独挂着一个 HashEntry 链表,segment 继承 ReentrantLock(可重入锁),扮演锁的角色,可以使用Lock接口的所有功能。
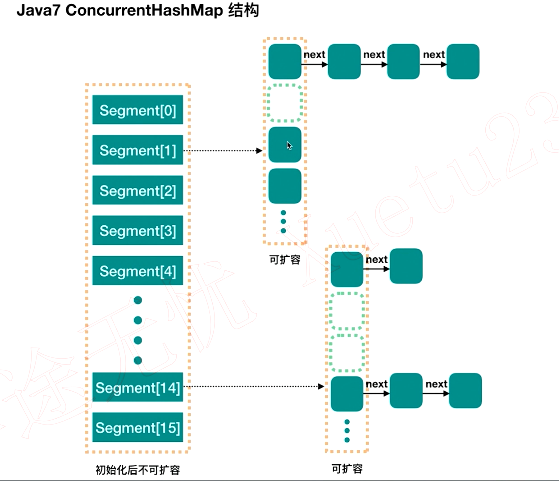
3.1、初始化有三个参数 initialCapacity、loadFactor、concurrencyLevel
concurrencyLevel 并发度,计算segment数组长度
concurrencyLevel 并发度,默认16,也就是默认有 16 个 segment,并发度最大可以设置为 65536。
并发度可以理解为程序运行时能够同时更新 ConccurentHashMap 且不产生锁竞争的最大线程数,实际上就是 ConccurentHashMap 中的分段锁个数,即 Segment[] 的数组长度。Segment[] 的数组长度(用ssize表示)只能取值为 2的幂 ,ssize >= concurrencyLevel 的最小2的幂,比如 concurrencyLevel=15,则Segment[] 的数组长度 = 16; concurrencyLevel=16,则Segment[] 的数组长度 = 16。
**提示:**如果并发度设置的过小,会带来严重的锁竞争问题;如果并发度设置的过大,原本位于同一个 Segment 内的访问会扩散到不同的 Segment 中,CPU cache命中率会下降,从而引起程序性能下降。
initialCapacity,计算 table 初始容量
>初始化时,只创建了segments[0],以后创建 Segment的所有参数都根据 Segment[0] 当前状态作为原型创建。
initialCapacity:用于计算 segments[0] 的 table 初始容量 ,initialCapacity 默认16。
segments[0] 的 table (HashEntry数组) 的**初始容量(用cap表示)**只能取值为 2的幂,且最小值是 2 ,cap的计算公式为 cap >= initialCapacity/segment数组长度,
loadFactor 扩容因子,计算 table 扩容阈值
loadFactor, table 扩容因子,默认0.75,当一个Segment的table存储的元素数量大于扩容阈值(用 threshold 表示), threshold = cap(table当前容量) * loadFactor 时,该table会进行一次扩容,而且每一次扩容都是容量翻倍 newCap = oldCap*2。
3.2 JDK7 ConcurrentHashMap 构造器源码分析
public class ConcurrentHashMap extends AbstractMap
implements ConcurrentMap, Serializable {
...
//table的默认初始容量
static final int DEFAULT_INITIAL_CAPACITY = 16;
//table 默认扩容因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 默认并发度 16
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
// 每个 table 的最大容量 2^30,如果 initialCapacity > MAXIMUM_CAPACITY,initialCapacity 赋值为 MAXIMUM_CAPACITY
static final int MAXIMUM_CAPACITY = 1 << 30;
// 每个 Segment 的 table 的最小容量
static final int MIN_SEGMENT_TABLE_CAPACITY = 2;
// Segment[] 数组的最大长度为 2^16,也就是65536
static final int MAX_SEGMENTS = 1 << 16;
// 锁之前的重试次数
static final int RETRIES_BEFORE_LOCK = 2;
// segment掩码,key的hash值的高位用于选择segment
final int segmentMask;
// segment偏移量
final int segmentShift;
/**
* segment数组, 每个 segment 都是一个专门的 hash table
*/
final Segment[] segments;
// key Set集合
transient Set keySet;
// Entry Set集合
transient Set> entrySet;
// value 集合
transient Collection values;
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, DEFAULT_CONCURRENCY_LEVEL);
}
// 下面就以默认值initialCapacity=16,loadFactor=0.75,concurrencyLevel=16讲解
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
// concurrencyLevel 最大为 MAX_SEGMENTS,也就是 2^16
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// 找到2的 sshift 次幂,作为最好的匹配参数
int sshift = 0;
// Segment[] 的长度
int ssize = 1;
// 如果concurrencyLevel=16,则 sshift=4,ssize=16
// sszie 为 大于等于 concurrencyLevel 的最小2的幂
// 比如:concurrencyLevel=13,则 sszie=16;concurrencyLevel=16,则 sszie=16;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// 段偏移量 segmentShift= 32-4 =28
this.segmentShift = 32 - sshift;
// 段掩码 segmentMask = 16-1 = 15
this.segmentMask = ssize - 1;
// initialCapacity 默认初始为 16, 最大为 MAXIMUM_CAPACITY,也就是 2^30
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//下面变量 c 和 cap 是为了计算 segment 的 table(HashEntry数组)的初始容量
//下面算法得到的结果是 cap(取值是2的幂,最小是2) >= initialCapacity/ssize
// c = 16 / 16 = 1
int c = initialCapacity / ssize;
// 只有当 initialCapacity 不是 2的 n 次幂,则 ++c
if (c * ssize < initialCapacity)
++c;
// Segment的 table 初始容量 cap = 2
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// 创建 segments[0],扩容因子 loadFactor=0.75,扩容阈值= cap * loadFactor = 2*0.75 = 1
// segments[0]的HashEntry[]容量为 cap
Segment s0 = new Segment(loadFactor, (int)(cap * loadFactor), (HashEntry[])new HashEntry[cap]);
// 创建 segments,指定长度为 ssize
Segment[] ss = (Segment[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
}
可以看到有几个重载的构造器,但最终都会调用 public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel),所以我们只需研究这个构造器就够了
构造器小结:
1、对入参 concurrencyLevel 进行最大值校验,最大为 MAX_SEGMENTS,也就是 2^16
2、根据 concurrencyLevel 计算 Segment[] 的数组长度,数组长度 ssize 为 大于等于concurrencyLevel 的最小2的幂
3、计算段偏移量 segmentShift 和 段掩码 segmentMask 这两个数值在后面计算 key 的 hash 值时需要用到
4、根据 initialCapacity 和 Segment[] 的数组长度,计算 segment 的每个 table (HashEntry数组)的初始容量 cap(取值是2的幂,最小是2) >= initialCapacity/ssize
5、创建 segments[0], 扩容因子 loadFactor=0.75,扩容阈值= cap * loadFactor = 2*0.75,segments[0]的 table (HashEntry数组)容量为 cap
6、创建 segments,指定长度为 ssize
3.3 JDK7 ConcurrentHashMap put()/putIfAbsent() 方法源码分析
put()/putIfAbsent() 方法小结:
1、求key对应的hash值,使用 Wang/Jenkins hash算法对key的hashCode进行再次计算 hash 值
2、根据 hash 值,还有构造器中的计算得到的 segmentShift、segmentMask 计算出key应该对应的segment数组中的下标是 j,从而获取到相应的 segment
3、初始化时,构造器中,只创建了segments[0],segment数组中其他的元素都还是 null。给定下标 j 的 Segment,如果不存在,则创建 Segment 并通过CAS操作存放在 Segment[] 数组中
4、将key和value的映射放入 Segment,如果是 onlyIfAbsent 模式,表示如果Segment存在key的映射,则不做任何操作,返回旧值,如果不是 onlyIfAbsent 模式,将key映射的值设置为 value,不管是否已经存在key的映射;
4.1、进行 Segment的put操作时,先加锁;
4.2、已经存在key对应的HashEntry
4.2.1、获取key映射的旧值
4.2.2、如果是 onlyIfAbsent 模式,则不做任何操作;如果不是 onlyIfAbsent 模式,将key映射的值设置为新的 value
4.2.3、释放锁,返回旧值;
4.3、还未存在key对应的HashEntry
4.3.1、如果当前 Segment 中的 HashEntry元素个数 count>threshold(扩容阈值),扩容 table,生成一个newTable,容量时oldTable的2倍,把oldTable所有的 HashEntry元素,进行再hash放入newTable中
4.3.2、如果未达到扩容阈值,还不需要扩容,新插入的node,设置为 HashEntry 链表的头节点,node 的next节点设置为旧的头节点,相当于直接插入到链表的第一位
4.4、如果未达到扩容阈值,则直接设置当前node为头节点,设置完成后,链表以当前节点为头节点开始
5、返回 key 在 Segment 中映射的旧值,没有则返回 null
public class ConcurrentHashMap extends AbstractMap
implements ConcurrentMap, Serializable {
...
// 在map中将 key 映射到的指定value。key 和 value 都不能为null。返回 key 在map 中映射的前一个值,没有则返回 null
public V put(K key, V value) {
Segment s;
if (value == null)
throw new NullPointerException();
// 求key对应的hash值,使用 Wang/Jenkins hash算法对key的hashCode进行再次计算 hash 值
int hash = hash(key);
// 根据 hash 值,还有构造器中的计算得到的 segmentShift、segmentMask 计算出key应该对应的segment数组中的哪个下标,从而获取到相应的 segment
int j = (hash >>> segmentShift) & segmentMask;
// 刚刚初始化时,构造器中,只创建了segments[0],segment数组中其他的元素都还是 null
// 如果根据下标 j ,如果获取到的 segment == null,则新建 Segment
if ((s = (Segment)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
//返回给定下标 j 的 Segment,如果不存在,则创建 Segment 并通过CAS操作存放在 Segment[] 数组中。
s = ensureSegment(j);
//将key和value的映射放入 Segment,最后一个参数为false,将key映射的值设置为 value,不管是否已经存在key的映射;
//返回 key 在 Segment 中映射的前一个值,没有则返回 null
return s.put(key, hash, value, false);
}
// 在map中将 key 映射到的指定value,如果map中存在key的映射,则不做任何操作。
// key 和 value 都不能为null。返回 key 在map 中映射的前一个值,没有则返回 null
public V putIfAbsent(K key, V value) {
Segment s;
if (value == null)
throw new NullPointerException();
// 求key对应的hash值,使用 Wang/Jenkins hash算法对key的hashCode进行再次计算 hash 值
int hash = hash(key);
// 根据 hash 值,还有构造器中的计算得到的 segmentShift、segmentMask 计算出key应该对应的segment数组中的哪个下标,从而获取到相应的 segment
int j = (hash >>> segmentShift) & segmentMask;
// 刚刚初始化时,构造器中,只创建了segments[0],segment数组中其他的元素都还是 null
// 如果根据下标 j ,如果获取到的 segment == null,则新建 Segment
if ((s = (Segment)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null)
//返回给定下标 j 的 Segment,如果不存在,则创建 Segment 并通过CAS操作存放在 Segment[] 数组中。
s = ensureSegment(j);
//将key和value的映射放入 Segment,最后一个参数为true,表示如果Segment存在key的映射,则不做任何操作;
//返回 key 在 Segment 中映射的前一个值,没有则返回 null
return s.put(key, hash, value, true);
}
// 计算 key 对应的 hash 值
private int hash(Object k) {
int h = hashSeed;
if ((0 != h) && (k instanceof String)) {
return sun.misc.Hashing.stringHash32((String) k);
}
// 得到 k的值,并进行位异或运算
h ^= k.hashCode();
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
// 再用 Wang/Jenkins hash算法计算二次计算 hash值
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
//返回给定下标 k 的 Segment,如果不存在,则创建 Segment 并通过CAS操作存放在 Segment[] 数组中。
@SuppressWarnings("unchecked")
private Segment ensureSegment(int k) {
final Segment[] ss = this.segments;
// 计算出 原始偏移量
long u = (k << SSHIFT) + SBASE; // raw offset
Segment seg;
// 检查给定下标的Segment是否null
if ((seg = (Segment)UNSAFE.getObjectVolatile(ss, u)) == null) {
// 初始化时,创建了segments[0],以后创建 Segment的所有参数都根据 Segment[0] 当前状态作为原型创建
Segment proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;//容量等于Segment[0] 当前容量
float lf = proto.loadFactor;//扩容因子等于Segment[0] 扩容因子
int threshold = (int)(cap * lf);//扩容阈值
HashEntry[] tab = (HashEntry[])new HashEntry[cap];
// 再次检查给定下标的Segment是否null
if ((seg = (Segment)UNSAFE.getObjectVolatile(ss, u))
== null) { // recheck
// 创建 Segment
Segment s = new Segment(lf, threshold, tab);
// 再次检查给定下标的Segment是否null
while ((seg = (Segment)UNSAFE.getObjectVolatile(ss, u))
== null) {
// cas 算法将刚刚创建的 Segment 保存到 Segment[] 数组中
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
// Segment 继承了 ReentrantLock,说明它可以使用Lock接口的所有功能
static final class Segment extends ReentrantLock implements Serializable {
...
//将key和value的映射放入 Segment,最后一个参数onlyIfAbsent为true,表示如果Segment存在key的映射,则不做任何操作;
//如果onlyIfAbsent为false,则将key映射的值设置为 value,不管是否已经存在key的映射
//返回 key 在 Segment 中映射的前一个值,没有则返回 null
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// tryLock(),加锁
// scanAndLockForPut()会在循环tryLock()时候创建一个新节点 node = new HashEntry,并返回 node
//当重试tryLock()次数 > MAX_SCAN_RETRIES时,调用lock();阻塞,直到获取到锁
HashEntry node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry[] tab = table;
// JDK7的ConcurrentHashMap中,table 是 HashEntry 数组,每个 HashEntry 元素又单独挂着一个 HashEntry 链表
// 根据hash值找到在 table 中hash对应的 HashEntry链表下标
int index = (tab.length - 1) & hash;
// 查询HashEntry链表的头节点HashEntry
HashEntry first = entryAt(tab, index);
for (HashEntry e = first;;) {
//头节点存在
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
//已经存在key对应的HashEntry,获取key映射的旧值
oldValue = e.value;
if (!onlyIfAbsent) {
//不是onlyIfAbsent模式,则设置为新值,覆盖旧值
e.value = value;
//修改次数+1
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
//如果是scanAndLockForPut()方法获取到锁,则node!=null,进入这个分支
//将当前节点 node(HashEntry)的next节点设置为 first
node.setNext(first);
else
// 如果是一开始tryLock()就获取到锁,则 node == null,进入这个分支
// 新建 HashEntry 并指定 next节点为first
node = new HashEntry(hash, key, value, first);
// 当前 Segment 中的 HashEntry元素个数+1
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
//如果当前 Segment 中的 HashEntry元素个数 count>threshold(扩容阈值)
// 扩容 table,生成一个newTable,容量时oldTable的2倍,把oldTable所有的 HashEntry元素,进行再hash放入newTable中
rehash(node);
else
//如果未达到扩容阈值,则直接设置当前node为头节点,设置完成后,链表以当前节点为头节点开始
setEntryAt(tab, index, node);
//修改次数+1
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
//释放锁
unlock();
}
//返回旧值
return oldValue;
}
//扩容并重hash
@SuppressWarnings("unchecked")
private void rehash(HashEntry node) {
HashEntry[] oldTable = table;
int oldCapacity = oldTable.length;
// 新容量=旧容量*2
int newCapacity = oldCapacity << 1;
// 新的扩容阈值
threshold = (int)(newCapacity * loadFactor);
// 新的table newTable
HashEntry[] newTable =
(HashEntry[]) new HashEntry[newCapacity];
// JDK7的ConcurrentHashMap中,table 是 HashEntry 数组,每个 HashEntry 元素又单独挂着一个 HashEntry 链表
//掩码,根据 HashEntry 的 hash&sizeMask 得到 HashEntry 在 table中的下标,也就是 HashEntry 链表在 table中的下标
int sizeMask = newCapacity - 1;
// 将oldTable 中的所有 HashEntry 元素根据求得的下标重新放到 newTable
for (int i = 0; i < oldCapacity ; i++) {
// HashEntry 链表,这是头节点
HashEntry e = oldTable[i];
if (e != null) {
HashEntry next = e.next;
// 根据 HashEntry 的 hash&sizeMask 得到 HashEntry 在 table中的下标,也就是 HashEntry 链表在 table中的下标
int idx = e.hash & sizeMask;
if (next == null) //表示这是单节点的 HashEntry 链表
newTable[idx] = e;//将头节点放到 newTable[idx] 对应的元素
else { // Reuse consecutive sequence at same slot
HashEntry lastRun = e;
int lastIdx = idx;
for (HashEntry last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// Clone remaining nodes
for (HashEntry p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry n = newTable[k];
newTable[k] = new HashEntry(h, p.key, v, n);
}
}
}
}
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
...
}
...
}
3.4 JDK7 ConcurrentHashMap get() 方法源码分析
get() 方法小结:
1、获取 key 的 hash 值
2、求出原始偏移量,获取key对应的 Segment 和 Segment中的 table
3、获取 table 中key hash值对应的 HashEntry 链表
4、检查 HashEntry 链表中的各个元素,检查 key 和 hash值是否匹配,如果查到key匹配的元素,则返回 value,否则找不到,返回 null
public V get(Object key) {
Segment s; // manually integrate access methods to reduce overhead
HashEntry[] tab;
// 获取 key 的 hash 值
int h = hash(key);
// 求出原始偏移量
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 获取key对应的 Segment 和 Segment中的 table
if ((s = (Segment)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// 获取 table 中key hash值对应的 HashEntry 链表
for (HashEntry e = (HashEntry) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
// 检查 HashEntry 链表中的各个元素,检查 key 和 hash值是否匹配
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
// 如果找不到,返回null
return null;
}
上面通过源码详细地分析了同步容器vector 、 Hashtable 、SynchronizedList 与 SynchronizedMap 它们是通过对每一个方法加synchronized锁来实现线程安全的,但在线程竞争激烈的情况下,效率非常低下。接着,学习线程安全的同步容器 ConcurrentHashMap ,介绍了它的API,通过源码详细地讲解了 ConcurrentHashMap 在Java7 中的实现,分析它的核心方法的实现原理,并且总结了核心方法的实现步骤。
ConcurrentHashMap 在Java8 中的实现原理,下一篇文章继续。
>代码:
>github.com/wengxingxia/002juc.git
共同学习,写下你的评论
评论加载中...
作者其他优质文章


