
数据是数据科学家的基础,因此了解许多加载数据进行分析的方法至关重要。在这里,我们将介绍五种Python数据输入技术,并提供代码示例供您参考。

作为初学者,您可能只知道一种使用p andas.read_csv 函数读取数据的方式(通常以CSV格式)。它是最成熟,功能最强大的功能之一,但其他方法很有帮助,有时肯定会派上用场。
我要讨论的方法是:
Manual 函数
loadtxt 函数
genfromtxtf 函数
read_csv 函数
Pickle
我们将用于加载数据的数据集可以在此处找到 。它被称为100-Sales-Records。
Imports
我们将使用Numpy,Pandas和Pickle软件包,因此将其导入。

1. Manual Function
这是最困难的,因为您必须设计一个自定义函数,该函数可以为您加载数据。您必须处理Python的常规归档概念,并使用它来读取 .csv 文件。
让我们在100个销售记录文件上执行此操作。

嗯,这是什么????似乎有点复杂的代码!!!让我们逐步打破它,以便您了解正在发生的事情,并且可以应用类似的逻辑来读取 自己的 .csv文件。
在这里,我创建了一个 load_csv 函数,该函数将要读取的文件的路径作为参数。
我有一个名为data 的列表, 它将具有我的CSV文件数据,而另一个列表 col 将具有我的列名。现在,在手动检查了csv之后,我知道列名在第一行中,因此在我的第一次迭代中,我必须将第一行的数据存储在 col中, 并将其余行存储在 data中。
为了检查第一次迭代,我使用了一个名为checkcol 的布尔变量, 它为False,并且在第一次迭代中为false时,它将第一行的数据存储在 col中 ,然后将checkcol 设置 为True,因此我们将处理 数据列表并将其余值存储在 数据列表中。
逻辑
这里的主要逻辑是,我使用readlines() Python中的函数在文件中进行了迭代 。此函数返回一个列表,其中包含文件中的所有行。
当阅读标题时,它会将新行检测为 \ n 字符,即行终止字符,因此为了删除它,我使用了 str.replace 函数。
由于这是一个 的.csv 文件,所以我必须要根据不同的东西 逗号 ,所以我会各执一个字符串, 用 string.split(“”) 。对于第一次迭代,我将存储第一行,其中包含列名的列表称为 col。然后,我会将所有数据附加到名为data的列表中 。
为了更漂亮地读取数据,我将其作为数据框格式返回,因为与numpy数组或python的列表相比,读取数据框更容易。
输出量

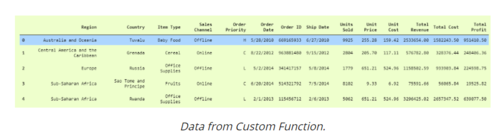
利弊
重要的好处是您具有文件结构的所有灵活性和控制权,并且可以以任何想要的格式和方式读取和存储它。
您也可以使用自己的逻辑读取不具有标准结构的文件。
它的重要缺点是,特别是对于标准类型的文件,编写起来很复杂,因为它们很容易读取。您必须对需要反复试验的逻辑进行硬编码。
仅当文件不是标准格式或想要灵活性并且以库无法提供的方式读取文件时,才应使用它。
2. Numpy.loadtxt函数
这是Python中著名的数字库Numpy中的内置函数。加载数据是一个非常简单的功能。这对于读取相同数据类型的数据非常有用。
当数据更复杂时,使用此功能很难读取,但是当文件简单时,此功能确实非常强大。
要获取单一类型的数据,可以下载 此处 虚拟数据集。让我们跳到代码。
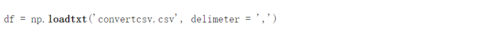
这里,我们简单地使用了在传入的定界符中 作为 ','的 loadtxt 函数 , 因为这是一个CSV文件。
现在,如果我们打印 df,我们将看到可以使用的相当不错的numpy数组中的数据。

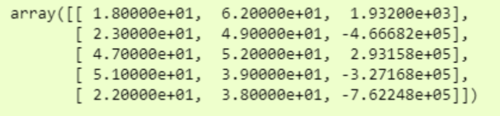
由于数据量很大,我们仅打印了前5行。
利弊
使用此功能的一个重要方面是您可以将文件中的数据快速加载到numpy数组中。
缺点是您不能有其他数据类型或数据中缺少行。
3. Numpy.genfromtxt()
我们将使用数据集,即第一个示例中使用的数据集“ 100 Sales Records.csv”,以证明其中可以包含多种数据类型。
让我们跳到代码。

为了更清楚地看到它,我们可以以数据框格式看到它,即

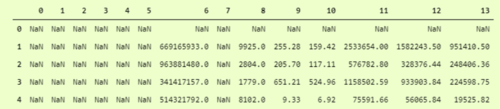
这是什么?哦,它已跳过所有具有字符串数据类型的列。怎么处理呢?
只需添加另一个 dtype 参数并将dtype 设置 为None即可,这意味着它必须照顾每一列本身的数据类型。不将整个数据转换为单个dtype。

然后输出


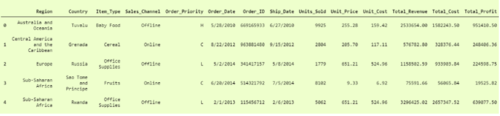
比第一个要好得多,但是这里的“列”标题是“行”,要使其成为列标题,我们必须添加另一个参数,即 名称 ,并将其设置为 True, 这样它将第一行作为“列标题”。
即
df3 = np.genfromtxt('100 Sales Records.csv', delimiter=',', dtype=None, names=True, encoding='utf-8')我们可以将其打印为

4. Pandas.read_csv()
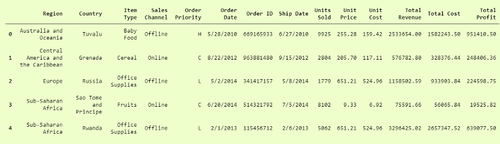
Pandas是一个非常流行的数据操作库,它非常常用。read_csv()是非常重要且成熟的 功能 之一,它 可以非常轻松地读取任何 .csv 文件并帮助我们进行操作。让我们在100个销售记录的数据集上进行操作。
此功能易于使用,因此非常受欢迎。您可以将其与我们之前的代码进行比较,然后进行检查。

你猜怎么着?我们完了。这实际上是如此简单和易于使用。Pandas.read_csv肯定提供了许多其他参数来调整我们的数据集,例如在我们的 convertcsv.csv 文件中,我们没有列名,因此我们可以将其读取为
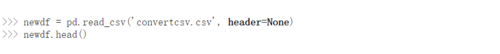
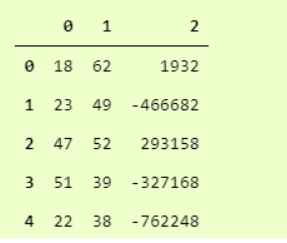
我们可以看到它已经读取了没有标题的 csv 文件。您可以在此处查看官方文档中的所有其他参数 。
5. Pickle
如果您的数据不是人类可以理解的良好格式,则可以使用pickle将其保存为二进制格式。然后,您可以使用pickle库轻松地重新加载它。
我们将获取100个销售记录的CSV文件,并首先将其保存为pickle格式,以便我们可以读取它。

这将创建一个新文件 test.pkl ,其中包含来自 Pandas 标题的 pdDf 。
现在使用pickle打开它,我们只需要使用 pickle.load 函数。

在这里,我们已成功从pandas.DataFrame 格式的pickle文件中加载了数据 。
学习成果
您现在知道了5种不同的方式来在Python中加载数据文件,这可以在您处理日常项目时以不同的方式帮助您加载数据集。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



