
作者:马晓宇
论文发布之后已经有一段时间了,之前提到的这篇文章由于种种原因也是欠了有些日子,抱歉了大家。
上次说过,这次 VLDB 有好些篇都是 HTAP(Hybrid Transactional / Analytical Processing)主题。自打 2014 年 Gartner 提出这个说法,由于针对交易数据的实时分析需求越来越多,这些年来 HTAP 已经变成一个热词。除了 PingCAP 的一篇,还有 IBM 的 PingCAP 的一篇Replication at the Speed of Change – a Fast, Scalable Replication Solution for Near Real-Time HTAP Processing,和今天要说 Google F1 团队的 Lightning 论文。甚至其他一些由非 TP 角度切入的系统也向 HTAP 的模糊地带演进,例如阿里的 Hologres 论文以及 Databricks 的 PingCAP 的一篇Delta Lake 论文。
由于其超前的数据量和用户场景,Google 在诸多领域一直是明灯一样的存在。虽然 F1 近期两篇论文并没有到眼前一亮的地步,但是狗记的文章还是会受到无数关注,这次就和大家一起读一读这篇,并且结合之前的 TiDB 论文做一些对比。实际上,我们觉得仅就 HTAP 的架构设计而言,我们兼顾了 F1 Lightning 的几乎所有设计优势,并且能提供更多。
论文在 Related Work 章节引用了一篇 IBM Research 的 PingCAP 的一篇HTAP Survey 短文,总结的挺有意思的,这里推荐大家看下,我们团队写论文的时候,也是通过这篇按图索骥来调研其他人成果的。
现有的 HTAP 系统被分为两种设计类型:
- 单一系统承载 OLTP 和 OLAP(Single System for OLTP and OLAP)
- 分离的 TP 与 AP 系统(Separate OLTP and OLAP System)
市面上不少从零开始的 HTAP 项目都是由单一整合系统入手,由于从零开始,他们可以做更紧耦合的设计也没有太多历史包袱。再细分的话,这里还有选择单一存储引擎或者使用混合行列引擎的不同设计,而行列混合的设计显然更具性能优势。值得一提的是,文中没有讲到一个很关键的点,就是互相干扰的问题,单系统的设计很容易造成 AP 作业干扰 TP,这对一个需要在严肃场景下运作的 HTAP 系统其实是无法忍受的。
分离系统的好处是可以单独针对 TP 和 AP 进行设计,互相之间侵入较小,但在既有的架构下,往往需要通过离线 ETL 来转运数据(原因分析可以参考我们这篇对存储部分的分析)。而 F1 Lightning 设计也落在分离系统的范畴,使用了 CDC 进行实时数据勾兑而非离线 ETL,那毫无疑问,F1 的列存部分设计也需要和我们一样针对列存变更进行设计。
顺口提一下,论文中分析相关工作时也提到了 TiDB 和 TiFlash,不过这部分描述却是错误的,TiDB 和 Lightning 一样可以提供 Strong Snapshot Consistency,甚至由于它的独特设计,还能提供更强的一致性和新鲜度。
Lightning 相对于既有 HTAP 系统,提供了如下几个(TiDB HTAP 也一样拥有的甚至更好)优势:
- 拥有只读的列存副本,提供了更好的执行效率以
- 相对于 ETL 流程,提供了更简单的配置和去重
- 无需修改 SQL 直接查询 HTAP
- 一致性和新鲜度
- 安全方面 TP 与 AP 两部分统一
- 设计关注点分离,TP 和 AP 可以分别针对性优化自己的领域而不过多牵扯
- 扩展性,提供了对接除了 F1 DB 和 Spanner 以外不同的 TP 数据库的可能性
系统架构
由于项目立项的前提是对 TP 系统无侵入性,因此作为 HTAP 来说,F1 Lightning 的架构设计相对保守。现有 HTAP 的研究领域,大多数项目都是以所谓 Greenfield 方案(不受前序方案约束)为假设,但 F1 Lightning 需要在对现有业务不做任何迁移且设计方案最大程度不对 TP 系统做修改(组织架构层面,F1 Lightning 团队也不管 TP 系统的代码),所以他们做出了一个 「A loosely coupled HTAP solution」,这是一个犹如驴标蛇皮袋一般巨朴实的方案:通过 CDC 做 HTAP。所以实际上,F1 Lightning 是一个 CDC + 可变更列存的方案。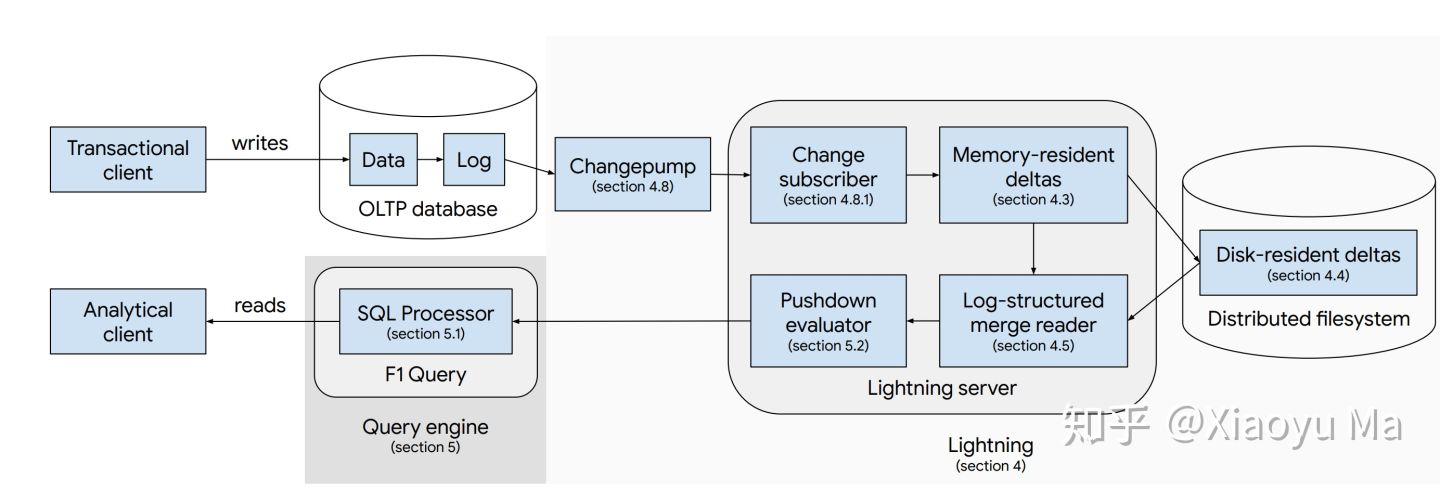
Lightning 分为这么几个模块:
- 数据存储:持续接受 CDC 的变更信息并存储到 Lightning 的读优化(列存)副本。
- 变更复制:一个分布式的 CDC 通道,从 OLTP 系统接受事务日志,并将他们分发到不同的存储服务器,并且按需对新接入表进行数据历史回放。
- Metadata 数据库:存放存储节点和变更复制的状态。
- Lightning Master:全组件协同和管理。
不过,构成完整的 HTAP 系统而言,还有两个隐含的模块:
- OLTP 数据源:不断发布 CDC 信息。
- 查询引擎:使用 F1 Query,负责从 Lightning 中捞取数据响应查询。
由于 Google 的现有 TP 系统大多选用 MVCC 模型(实际上 MVCC 在分布式 TP 系统中也是一个流行的选择),对于读取语义,Lightning 也选择了 MVCC 和相应的快照隔离:由 TP 发出的 CDC 如果带着时间戳向 Lightning 进行复制,MVCC 会是一个最自然而且最方便的设计。而由于分布式 CDC 架构的天然约束和特性,Lightning 选择提供 Safe Timestamps 来保持一致性。这是一个类似水位线的设计,因为经过一次分布式分发,因此不同存储服务器接收到数据将会带来不等同的延迟,因此无法简单保证一致性。所以类似这样水位线的设计可以以数据新鲜度为代价换取查询的快照一致性。相对来说,TiDB HTAP 选择了更底层的复制方案,借助 Raft 的一致性特型提供了最新鲜且一致的数据,可以说是一种更优雅的方案。
存储
之前的文章分析过为何列存需要进行特殊的 Delta-Main 设计才能提供实时变更,Lightning 的设计也一样体现了相关的思路。这是一个类 LSM 架构,其中 Delta 信息直接存储于内存中,一旦就位就可以被查询。由于副本和 TiDB 一样位于 OLTP 系统中可以随时补数据,因此这部分数据也并不会单独记录 WAL。哪怕可以随时补数据,但如果需要回放成吨的数据将会带来巨大的恢复延迟。因此这里也毫无意外地引入了 Checkpoint 机制。由于 Delta 部分由 B+Tree 结构在内存中组织,可以随时无变更写入磁盘作为 Checkpoint。除了 Checkpoint 外,当 Delta 太大占用太多内存的时候,它们也会经过行列转置后写到磁盘上。和 TiFlash 或者 Parquet 等类似,Lightning 的 Delta 磁盘格式选用了很流行的类似 PAX 格式列存:先将一组行组成 Row Bundle,然后再按列切割,其中每个行组附加了一个针对主键的稀疏 B+Tree 索引,这个方案可以兼顾点查以及范围查询。
要支持一致性的读取,Lightning 也和 TiFlash 一样必然会遇到 MVCC 读取版本去重,并且不同存储(磁盘 Delta 和内存 Delta)之间需要进行读取时归并。由于支持了实时 DDL 带来的 Schema 物理多版本,列存处理相对多了一份表结构苟合(Schema Coercion)的考量:在归并的过程中,数据会被规整为同一 Schema。顺便提一句,由于同样需要考虑动态 Schema 变更的支持,TiFlash 的列存引擎也支持了同表不同结构存储。Lightning 采用了类 LSM 的架构,因此读取也会触发一个 K 路归并,有可能会带来可观的读取性能损失。为了减小归并读取的代价,与 LSM 和 Delta Main 设计类似,Lightning 需要不断整理数据,处理 Delta 的 Compaction。这部分比较有意思的点是,因此除了较小的归并操作,其他所有 Compaction 都将交给专门的 Compaction Worker 资源处理。关于这部分的相关原理讨论可以参考我们的前序博文。
由于 Lightning 需要接入不同的 OLTP 系统,因此除了多版本 Schema 支持之外,它还有特别的 Logical Schema 和 Physical Schema 的两层映射设计。其中第一层 Logical Schema 对应 OLTP 系统内的原生 Schema,包含了诸如 Protobuf,结构体之类的复杂类型,而第二层的物理 Schema 则只包含 Lightning 本身的原生类型,比如整数,浮点,字串等。这使得系统实现可以和数据源的 OLTP 类型系统大幅解耦。而两者之间靠 Logical Mapping 进行串联,这个映射定义了各个数据类型之间如何从源类型向 F1 类型系统进行来回翻译(写时由源向 F1 翻译,读时由 F1 翻译回源类型)。
Lightning 使用范围分片,支持在线 Repartitioning 以期达到负载均衡,而所谓在线就是不会打断数据注入以及查询。Lightning 的分区在大小触或者写入压力触及阈值的时候会进行分裂,而这种分裂是 Metadata Only 的(只修改 Metadata 中分片的范围而不是物理切割数据),而分裂产生的分片数据则由老分片的 Delta 继承而来。当查询发生的时候,由于数据 Delta 是原始分片继承,因此需要根据新分片的范围进行过滤才能读到正确的数据(TiKV 的逻辑 Region 分裂也是类似处理)。在新老交替的档口,新分片会等到同步连接建立并且数据追上之后才真正变成活动分片,而老的分片也会等涉及到的查询完成再停止工作。类似方式,Lightning 也支持分片合并。文章并没有说在分裂和合并之外分片如何在节点之间迁移。不过由于 Delta 落盘之后存在云存上,因此看起来只要重新为分片重新分配容器,并让分片回放一小段 Checkpoint 之后的新 Memory Delta 就能完成数据迁移。
总的来说,列存变更要考虑的点都是类似的,做的设计也都是类似的。无非是用一个写优化区去缓冲直接写入,而主数据区则是整理好的大块列存。不断由背景作业将写区向读区归并,以保持读取速度。不管是我们还是 Lightning 亦或上古的喜士多系统都是这么做的。这部分没有太多可以说的。Compaction 看起来有大小和时间维度的考量,但论文并没有太细致描述 Compaction 的策略。Compaction 设计需要联合考虑写放大和读取效率:频繁的 Compaction 可以用资源和写放大来换取性能(更激进的数据整理,让数据更好地维持在一个更优的读取状态,但消耗更多的计算资源以及磁盘写放大)。不过看起来由于是云架构,写云存且可以外挂额外的 Compation Worker,因此哪怕比较粗暴分层设计和 Compaction 算法应该也可以满足需求。
复制
F1 Lightning 主要依赖的是 CDC 层面的复制,这种复制得以屏蔽很多前端 TP 系统不同带来的复杂度。组件上来说,变更复制物理上依赖两部分:
- Changepump:内置了从不同源 CDC 到 Changepump 能接受的格式间的转换;并且将 Transaction Log 转换成面向 Partition 的变更日志。由于 Lightning 存储也是分片的,因此源系统事务的回放可能横跨多个分片和服务器,在回放的同时,Changepump 需要维持事务的信息以保持一致性。
- Change subscriber:Changepump 的 Client。Lightning 将一个表分为多个分片,每个分片都维护了一个对 Changepump 的订阅。这个订阅传输维护了一个起始时间戳(可以指向历史数据),而 Changepump 会根据这个时间戳来回放变更,由此,这套机制是支持断点续传的。
针对同 Primary Key 的传输是保证前后有序的,但跨 Primary Key 则没有这个保障。这应该使得不同主键数据可以同过不同节点分布式传输而不用经过中央单点来定序。不过随之而来的是,最新的数据跨越主键而言往往无法维持一致性,因此这套机制还借助了安全水位线来确保可查询的数据是一致的。Changepump 会定期进行产生一个 Checkpoint Timestamp 发送给所有订阅者:所有比这个时间戳更古老的数据都已经送达,Lightning 服务器本身就会根据这个信息来修正它本身的安全查询水位线。但这个 Checkpoint 时间戳的产生在并发环境下并不可能每条变更都修正(Coordinate Cost 会非常高),因此系统在新鲜度和处理高效性之间做了折中:越快越精准修正水位线必然带来更新鲜的可查询水位线以及处理效率下降,反之亦然。
Changepump 本身是分布式的,在源头上同一个变更日志可能被不同的 Changepump 服务器处理,目的地上同一个订阅也可能连接不同的 Pump。Changepump 和 Lightning Server 并不是对应的,因为 Changepump 需要均衡的是写入的量,而 Lightning 服务器则是要均衡存储的量。
F1 Lightning 和 TiDB HTAP 最大的不同在于复制设计。TiDB 的复制基于更底层的 Raft Log 设计,这种实现使得 TiDB 可以提供更好的一致性与新鲜度,且几乎不需要修改 OLTP 部分的设计。而 F1 的设计则采取了一种更松的耦合,使用 CDC 进行复制。越是底层的复制协议能越大程度保持复制本身的细节和一致性,而越高层的协议则需要一些勾兑手段来保持一致性,但好处是 OLAP 的存储层可以不用考虑太多 OLTP 的设计约束(例如 TiDB 需要以相同大小的 Region 为单位进行复制而 F1 Lightning 则不需要)。很可惜的是对于 Change Replication 部分论文并没有非常详细的描述,这部分对于如何维持一致性以及容错实际上还存在不少可以探讨的细节。例如如何判断一个服务器是没有事务发生,还是回放卡住还是 CDC 没有产生?是否通过心跳发空包来确定存活以推进时间戳?如何追踪源分区和目标分区之间的映射以推进时间戳?实际上,对于一个类似 Spanner 这样分布式 OLTP 源库通过 CDC 回放要保持一致性,并不是那么容易的。而这些论文的阐述都稍显太省略,有些遗憾。
容错
由于使用了云存,云存本身保证了数据的高可用,所以 Lightning Server 只需要保障服务高可用即可。因此每个分片会被指派多个 Lightning Server,而这些 Server 分别从 Changepump 拖拽相同的变更日志(Changepump 内做了内存 Cache 以优化这样重复的拉取),并维护独立的 Memory Delta。但是仅仅有一个主分片会向云存写入数据(包括 disk-resident delta 以及 memory delta checkpoint),当主分片完成写入则会向其他副本服务器发出通知以更新 LSM。这些所有的多个副本都可以同时响应读取服务。当有服务器宕机的时候,新节点会尝试先从分片的其他副本获取数据(这些数据是已经整理好的形式,天然的 Checkpoint)而非直接从 Changepump 进行回放。而当轮滚升级的时候,Lightning 也会很小心地不同时重启同分片的多个服务器。
Lightning 配有表级 Failover。当某些时候某张表不可用(压力太大被黑名单,或者数据坏了等),系统可以自动将查询路由回 OLTP 系统(由于查询和数据都基本等价)。但用户可以选择是否进行这样的容错,以防 AP 查询压力打垮 TP。
简单来说容错部分,没有太多新意,不过借助云存容错,可以从 Pump 随时回溯历史,以及无需保障最新数据给了 F1 Lightning 很大的设计空间,不用精细的一致性复制协议也不用太担心会造成读取不一致。
F1 Query 集成
F1 Query 论文可以在这里找到,它可以算作是一个 Federated Query Engine,类似 Apache Spark 和 Presto,可以横跨多个不同的存储引擎以及源数据库。这里使用 F1 Query 作为查询引擎也是题中应有之义。由于联邦查询的特型,用户可以无感知 Query 由行存还是列存来响应。与 TiDB 的处理方式类似,F1 Lightning 可以作为一个特殊的 Access Path 暴露给优化器,以便利用 CBO 的方式来决定是否读取列存。不过有意思的是,F1 Query 并不会在逻辑计划阶段对查询进行区分:它会产生一个读取行列都一样的逻辑计划,而在物理计划阶段再选择具体的 Access Path。这里看起来还是有更深的优化空间,例如根据不同索引以及列存共同考量选择不同 JOIN 顺序。另外 F1 Lightning 也同样可以将 Subplan 下推,类似 TiFlash 的协处理器功能,本地化无需 Shuffle 的辅助计算,例如 Filter,Partial Aggregation 以及 Projection。
这部分设计类似 TiFlash + TiSpark / TiDB 的组合。单就 F1 Query 的形态,在 TiDB HTAP 中可以用 TiSpark 代替,两者都同样具备桥接不同存储以及 Subplan 下推的能力。
工程实践
- 组件复用:系统中诸多可能被复用的组件都抽成了单独的库,在多个其他产品中被复用,另外类似 Changepump 这样原本为 Lightning 设计的组件也被类似 TableCache 这样的产品所利用。
- 正确性验证:加入了针对行列系统对比的校验机制。
收益与代价
无疑列存使用会加入额外的副本占用额外的空间,但列存的计算效率更高,而计算资源却是比存储更昂贵的。经过分析,对于 Read Intensive 应用来说,额外的存储能带来大量的计算资源节省,看起来是值得的。对于混合 Workload 的查询,诸如小型的分布式查询,或者人肉写的 Adhoc 查询,异或 ETL 类作业,Lightning 的列存副本以及计算下推都可以节省很多计算资源以及时间。这部分对 TiDB HTAP 也是类似,我们有用户反馈使用 TiFlash 之后反而用了更少的服务器。
对比 TiDB HTAP
下面是吹捧自家产品环节 :)
总体来说,TiDB HTAP 使用了完全不同的设计但是达到甚至超越了 F1 Lightning 论文所阐述优势。犹如之前文章所说,我们最初版的 TiFlash 设计也是基于 CDC 的。但是由于种种原因,这个设计「进化」成了现在基于 Multi-Raft 的样子。两者都立足于解决由行存到列存的异构数据复制的问题,并且两端都可能是分布式系统。类似 SAP Hana 这样由单点 OLTP 到分布式 OLAP 的异构复制无疑会更简单,因为输出的日志是有单机产生,保序和一致性都能以很简单的方式解决。而由多主的分布式系统所产生的日志,要保证一致性则颇费思量。由于源头是多点的分布式系统,那么传输无疑无法经由单点收纳,那样吞吐必然不够,但多点收纳又很难保证全局的一致性。由此 F1 Lightning 的 CDC 方案设计了复杂的时间戳水位线,用牺牲新鲜度的方式提供一致性查询机制,但由于本人水平不够,还没有完全洞悉其背后所有的设计要点,但以 CDC 方式进行异构复制而要确保一致性大致会是一个相对复杂的设计。相对而言,Raft 的异构复制却有截然不同的特性。经由 Multi-Raft + PD 调度,TiFlash 的复制体系自动达成了负载均衡,无论日志传输,还是是源端写入压力,异或目标端的存储均衡。也由于 Raft 协议提供了 Follower / Learner 副本的一致性读取算法,通过对线性日志的索引校对,TiFlash 可以很容易提供最新数据的读取而无需维护复杂的水位线,并且几乎完全等同的 Sharding(Region) 设计也使得 Shard 之间的全局一致性可以仅仅靠 Raft 加 MVCC 两重机制就能完整保障,并且确保读取到「最新鲜」的数据。最新鲜和较新鲜看似只是一小段时间的差异,但实际上和 TiKV 几乎相同的一致性保障使得 TiDB 的行存和列存可以在在线业务甚至同一查询中混合使用而无需考虑两者可能提供不同的数据服务,在我看来,这个才算是真正的 HTAP。另外也由于这样的设计,TiFlash 不需要设计另一套天差地别的存储架构,无需额外设计负载均衡无需额外的存储调度,只需要通过现有的 PD,以 TiKV 引擎几乎一致的行为运转和运维,大大减小了部署和运维的负担。总之,个人觉得 TiDB HTAP 的设计是更优雅且优秀 :) 当然这里也欢迎各位看官在评论区做出自己的评价。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



