
全是干货的技术号:
本文已收录在github,欢迎 star/fork:
explain或者desc获取MySQL如何执行select语句的信息。
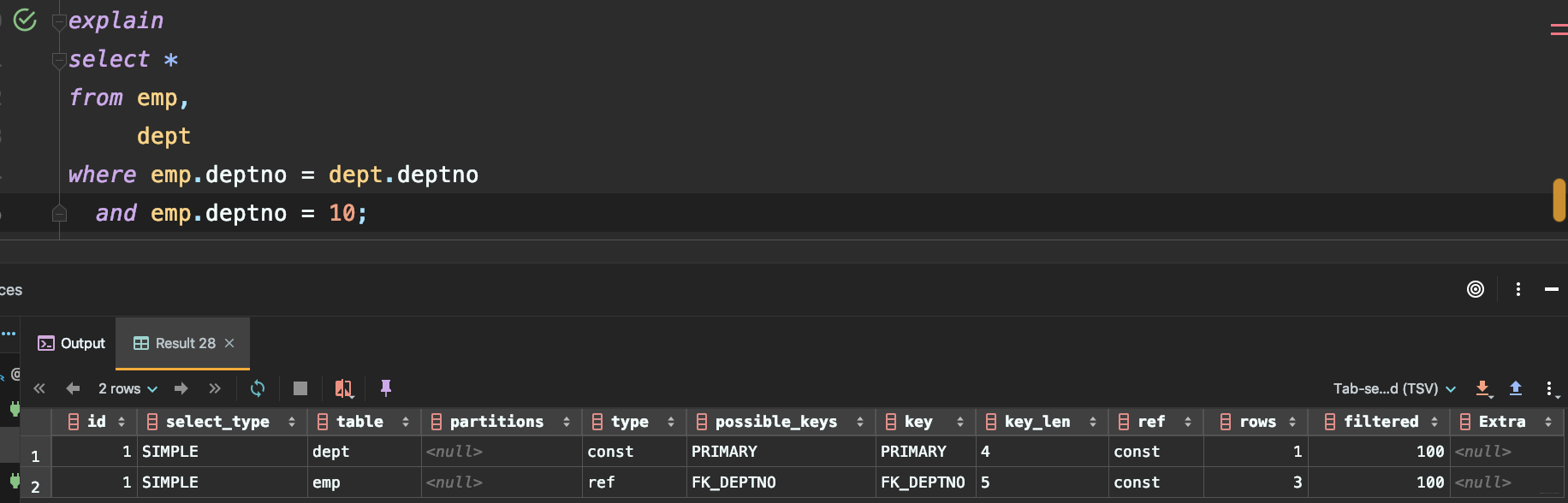
结果包含很多列
1 各列字段说明
1.1 id
SELECT标识符。这是查询中SELECT的序列号,表示查询中执行select子句或者操作表的顺序。如果该行引用其他行的并集结果,则该值可为NULL。
id号分为三种情况:
- id相同,那么执行顺序从上到下
explain se1ect * from emp e join dept d on e.deptno = d.deptno
join salgrade sg on e.sa1 between sg.1osal and sg.hisal;
- id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
explain select * from emp e where e.deptno in
(select d.deptno from dept d where d.dname = 'SALES');
- id相同和不同的,同时存在:相同的可以认为是一组,从上往下顺序执行,在所有组中,id值越大, 越先执行
exp1ain select * from emp e join dept d on e.deptno = d.deptno join salgrade sg on e.sa1
between sg.1osal and sg.hisal where e. deptno in (select d.deptno from dept d where
d.dname = 'SALES');
select_ type
1.2 select_type
主要用来分辨SELECT的类型,是普通查询还是联合查询还是子查询:
-
simple(简单表,即不用表连接或子查询)
-
primary(主查询,即外部查询)
-
union(union中的第二个或者后面的查询语句)
-
subquery(子查询中的第一个select)
1.3 table
输出结果集。对应行正在访问哪个表,表名或者别名,可能是临时表或者union合并结果集。
-
如果是具体表名,则表明从实际的物理表中获取数据,当然也可是表的别名
-
表名是derivedN的形式,表示使用了id为N的查询产生的衍生表
-
当有union result时,表名是union n1,n2等的形式,n1,n2表示参与union的id
1.4 type
type列描述如何连接表。
表示MySQL在表中找到所需行的方式,或者叫访问类型。
常见类型:all,index,range,ref,eq_ref,const,system,null,性能由差到好。
一般需要保证查询至少达到range级,最好能达到ref。
1.4.1 ALL
最简单暴力的全表扫描,MySQL遍历全表找到匹配行,效率最差。
对来自先前表的行的每个组合进行全表扫描。如果该表是未标记为const的第一个表,则通常不好,并且在所有其他情况下通常性能也非常糟糕。一般来说,可以通过添加索引来避免ALL,这些索引允许基于早期表中的常量值或列值从表中检索行。
explain select * from film where rating > 9;
1.4.2 index
连接类型与ALL相同,除了扫描索引树外。这发生于两种方式:
- 如果索引是查询的覆盖索引,并且可用于满足表中所需的所有数据,则仅扫描索引树。
在这种情况下,Extra列显示Using index。仅索引扫描通常比ALL更快,因为索引的大小通常小于表数据。
- 使用对索引的读取执行全表扫描,以按索引顺序查找数据行。Extra列不显示
Using index。
当查询仅使用属于单个索引一部分的列时,MySQL可以使用此连接类型。
explain select title from film;
1.4.3 range
使用索引查询行,仅检索给定范围内的行。输出行中的key列指示使用的哪个索引。key_len包含使用的最长的键部分。此类型的ref列为NULL。
当使用 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, LIKE, or IN()操作符将key列与常量进行比较时,可以使用range:
索引范围扫描,常见<,<=,>,>=,between
SELECT * FROM tbl_name
WHERE key_column = 10;
SELECT * FROM tbl_name
WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name
WHERE key_column IN (10,20,30);
SELECT * FROM tbl_name
WHERE key_part1 = 10 AND key_part2 IN (10,20,30);
1.4.4 index_subquery
此连接类型类似于unique_subquery。它代替了IN子查询,但适用于以下形式的子查询中的非唯一索引:
value IN (SELECT key_column FROM single_table WHERE some_expr)
1.4.5 unique_subquery
此类型将eq_ref替换为以下形式的某些IN子查询:
value IN (SELECT primary_key FROM single_table WHERE some_expr)
unique_subquery只是一个索引查找函数,可以完全替换子查询以提高效率。
1.4.6 index_merge
此联接类型指示使用索引合并优化。在这种情况下,输出行中的键列包含使用的索引列表,而key_len包含使用的索引的最长键部分的列表。
1.4.7 ref_or_null
这种连接类型类似于ref,但是MySQL会额外搜索包含NULL值的行。此联接类型优化最常用于解析子查询。在以下示例中,MySQL可以使用ref_or_null连接来处理ref_table:
SELECT * FROM ref_table
WHERE key_column=expr OR key_column IS NULL;
1.4.8 fulltext
使用FULLTEXT索引执行连接。
1.4.9 ref
对于先前表中的每个行组合,将从该表中读取具有匹配索引值的所有行。
如果连接仅使用键的最左前缀,或者如果该键不是PRIMARY KEY(主键)或UNIQUE(唯一)索引(即如果连接无法根据键值选择单行),则会使用ref。
如果使用的键仅匹配几行,则这是一种很好的联接类型。
ref可以用于使用= or <=> 运算符进行比较的索引列。在以下示例中,MySQL可以使用ref联接来处理ref_table:
SELECT * FROM ref_table WHERE key_column=expr;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
1.4.10 eq_ref
对于先前表中的每行组合,从此表中读取一行。除了system和const类型,这是最好的连接类型。
当连接使用索引的所有部分并且索引是PRIMARY KEY或UNIQUE NOT NULL索引时,将使用它。
类似ref,区别在于所用索引是唯一索引,对于每个索引键值,表中有一条记录匹配;
简单来说就是多表连接使用primary key或者unique index作为关联条件。
eq_ref可用于使用=运算符进行比较的索引列。比较值可以是常量,也可以是使用在此表之前读取的表中列的表达式。在以下示例中,MySQL可以使用eq_ref连接来处理ref_table:
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
1.4.11 const
表最多有一个匹配行,该行在查询开始时读取。因为只有一行,所以优化器的其余部分可以将这一行中列的值视为常量。 const表非常快,因为它们仅读取一次。
当将PRIMARY KEY或UNIQUE索引的所有部分与常量值进行比较时,将使用const。在以下查询中,tbl_name可以用作const表:
SELECT * FROM tbl_name WHERE primary_key=1;
SELECT * FROM tbl_name
WHERE primary_key_part1=1 AND primary_key_part2=2;
1.4.12 system
该表只有一行(系统表)。这是const 连接类型的特例。
type null,MySQL不用访问数据库直接得到结果。
1.5 possible_keys
此次查询中可能选用的索引
1.6 key
此次查询中确切使用到的索引
1.7 ref
哪个字段或常数与 key 一起被使用
1.8 rows
此查询一共扫描了多少行,这个是一个估计值,不准确。
1.9 filtered
此查询条件所过滤的数据的百分比
1.10 extra
额外的信息。
using filesort
使用EXPLAIN可以检查MySQL是否可以使用索引来解析ORDER BY子句:
-
如果EXPLAIN输出的Extra列不包含Using filesort,则使用索引,并且不执行文件排序
-
如果EXPLAIN输出的Extra列包含正在使用文件排序,则不使用索引,而是执行全文件的排序

EXPLAIN不能区分优化器是否在内存中执行文件排序。在优化程序trace输出中可以看到内存文件排序的使用。查找filesort_priority_queue_optimization即可。
using temporary
建立临时表保存中间结果,查询完成之后把临时表剧除

using index
表示当前的查询是覆盖索引,直接从索明中读取数据,而不用访问数据表。
如果阿时出现using where表示索引被用来执行索引健值的查找;
如果没有,表示索引被用来读取数据,而不是真的查找
using where
使用where进行条件过滤
using join buffer
使用连接缓存
impossible where
where语句的结果总是false
no matching row in const table
对于具有联接的查询,存在一个空表或没有满足唯一索引条件的行的表。

其实还有很多,不再过多描述。
explain extended
MySQL 4.1引入explain extended命令,通过explain extended 加上show warnings可以查看MySQL 真正被执行之前优化器所做的操作
explain select * from users;
show warnings;
可从warning字段看到,会去除一些恒成立的条件,可以利用explain extended的结果来迅速的获取一个更清晰易读的sql语句。
2 show profile
SHOW PROFILE和SHOW PROFILES语句显示概要信息,该信息指示在当前会话过程中执行的语句的资源使用情况。
SHOW PROFILE和SHOW PROFILES语句已被弃用,并将在以后的MySQL版本中删除,而改用性能模式。此处我们就简单介绍一下,大家知道有这个东西就行了。
- 查看是否开启profile
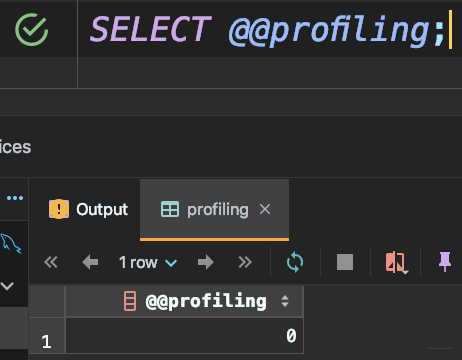
可见,默认profiling是关闭的。
可通过set语句在session级别启动profiling:
set profiling=1;
可查看执行过程中每个线程的状态和耗时。
其中的 sendingdata 状态表示MySQL线程开始访问数据行并把结果返回给客户端,而不仅仅是返回给客户端,由于在sending data状态下,MySQL线程往往需要做大量的磁盘读取操作;所以经常是整个查询中最耗时的状态。
支持选择all,cpu,block io,context,switch,page faults等明细,来查看MySQL在使用什么资源上耗费了过高的时间,例如,选择查看cpu的耗费时间
show profile cpu for query 6;
对比MyISAM的操作,同样执行count(*)操作,检查profile,Innodb表经历了Sending data状态,而MyISAM的表完全不需要访问数据
如果对MySQL 源码感兴趣,可以通过show profile source for query查看sql解析执行过程的每个步骤对应的源码文件
show profile source for query 6
3 trace分析优化器
MySQL 5.6提供。通过trace文件能够进一步了解优化器的选择,更好地理解优化器的行为。
使用方式
开启trace,设置格式为json,设置trace最大能够使用的内存,避免解析过程中因为默认内存小而不能完整显示
set optimizer_trace="enabled=on",end_markers_in_json=on;
set optimizer_trace_max_mem_size=1000000;
接下来执行trace的sql语句
select * from ....where....
最后检查information_schema.optimizer_trace就可以知道Mysql如何执行sql
select * from information_schema.optimizer_trace
参考
共同学习,写下你的评论
评论加载中...
作者其他优质文章


