
【一、项目背景】
在素材网想找到合适图片需要一页一页往下翻,现在学会python就可以用程序把所有图片保存下来,慢慢挑选合适的图片。
【二、项目目标】
1、根据给定的网址获取网页源代码。
2、利用正则表达式把源代码中的图片地址过滤出来。
3、过滤出来的图片地址下载素材图片。
【三、涉及的库和网站】
1、网址如下:
https://www.51miz.com/
2、涉及的库:requests、lxml
【四、项目分析】
首先需要解决如何对下一页的网址进行请求的问题。可以点击下一页的按钮,观察到网站的变化分别如下所示:
https://www.51miz.com/so-sucai/1789243.html
https://www.51miz.com/so-sucai/1789243/p_2/
https://www.51miz.com/so-sucai/1789243/p_3/
我们可以发现图片页数是1789243/p{},p{}花括号数字表示图片哪一页。
【五、项目实施】
1、打开觅知网,在搜索中输入你想要的图片素材(以鼠年素材图片为例)。
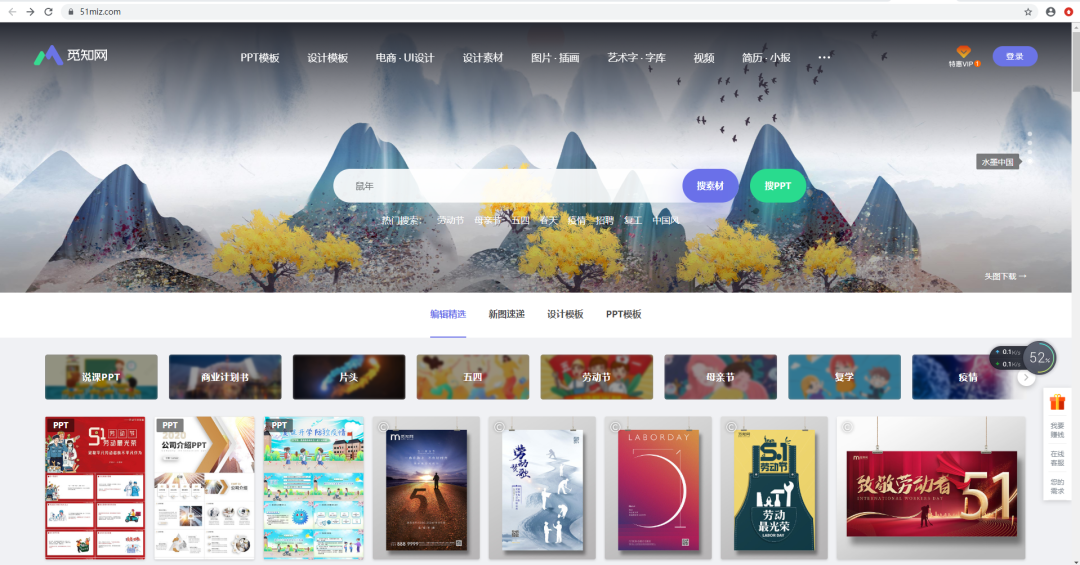
2、根据上一步对网址的分析,首先我们定义一个类叫做ImageSpider,类里面定义初始化函数、发送请求获取响应数据函数、解析函数、主函数。首先初始化函数,准备url地址和headers,代码如下图所示。

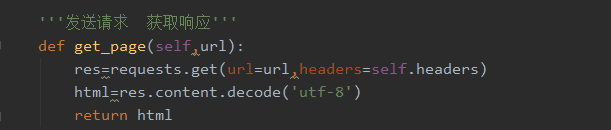
3、发送请求获取响应数据函数。
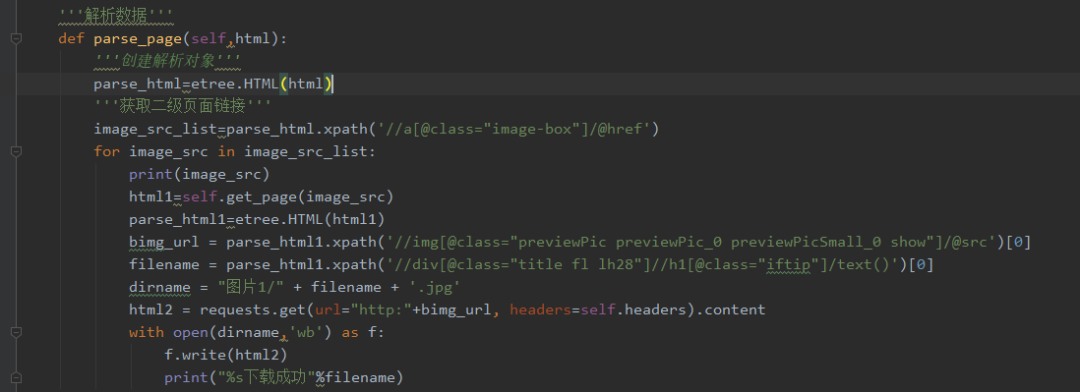
4、解析数据,使用xpath获取二级页面链接,最后把图片存储在文件夹中。使用谷歌浏览器选择开发者工具或直接按F12,发现我们需要的图片src是在img标签下的,于是用Python的requests提取该组件。

5、主函数,代码如下图所示。

【六、效果展示】
1、运行程序,在控制台输入你要爬取的页数,如下图所示。

2、在本地可以看到效果图,如下图所示。

【七、总结】
1、不建议抓取太多数据,容易对服务器造成负载,浅尝辄止即可。
2、希望通过这个项目,能够帮助大家下载到素材图片。
3、本文基于Python网络爬虫,利用爬虫库,实现素材图片的获取。实现的时候,总会有各种各样的问题,切勿眼高手低,勤动手,才可以理解的更加深刻。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



