
性能优化的核心思路
一、背景
平时技术交流的时候,很多同学都会问一些性能优化方面的问题。
比如:
有一张订单表为了保持订单记录,更新数据时不能删除,需要打算加上版本号,查询时取版本号最新的给前端,还有场景是查询订单历史给前端。 订单表量一般不会太小,每次先分组查询取出最大的一条,然后外层再去取对应的数据再分页显然性能不好。 怎么办?
可能也会有人会给出一些建议,然后呢?下次在遇到怎么办?
网上很少有文章系统讲解性能优化的相关方法论,所以借着这次机会总结出来,分享给大家。
俗话说授人以鱼不如授人以渔,本文将自己的性能优化方法论总结在这里,将自己理解的性能优化的概念和核心思想整理在这里,帮助大家能系统地应对性能优化方面的问题,能够更清晰地理解性能优化的原则。
二、干货
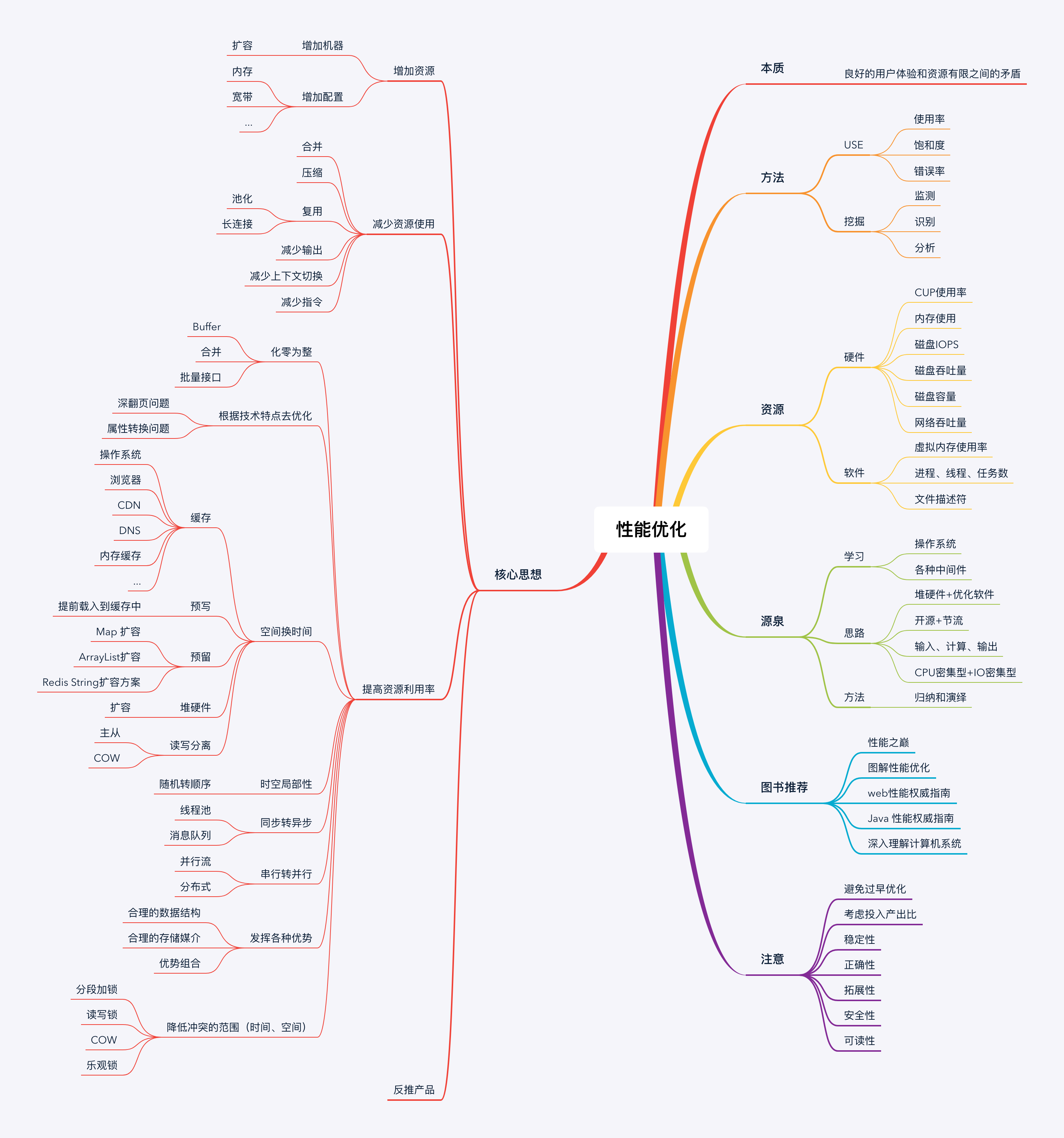
2.1本质
良好的用户体验和有限的资源之间的矛盾
2.2 性能优化的思维源泉
2.2.1 学习操作系统和各种中间件的优化手法
操作系统有很多性能优化的经典案例
各种中间件也会进行各种优化来提高性能
这需要大家主动去学习,去积累。
2.2.2 核心思路
【1】堆硬件 +优化软件(算法、步骤)
【2】开源(堆机器) + 节流(提高资源利用率,少占资源)
【3】输入、计算、输出
【4】权衡
很难三全其美,往往只能三选二!

2.2.3 归纳和演绎
在读书、工作中将一类的优化案例归总到一起,总结出最核心的规律,然后遇到新的问题时,看这些核心规律,去针对某个实际问题设计对应的解决方案。
2.2.4 核心思想
化整为零
分布式 读写分离
化零为整
批量接口
Buffer
空间换时间(缓存、预写、预留空间、堆硬件)
缓存(浏览器缓存、CDN加速、内存缓存、CPU缓存…)
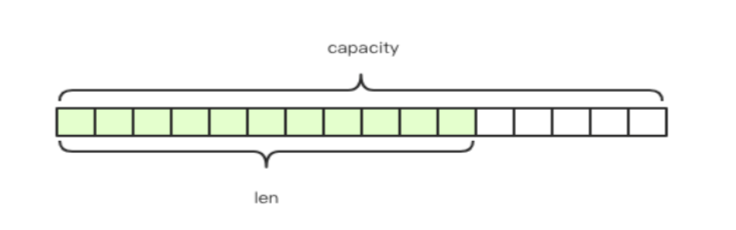
预写(将一些操作提前准备好) 预留空间(ArrayList 扩容 1.5 倍; HashMap 的扩容机制;Redis String 也会预留空间,避免频繁扩容)
堆硬件(通过添加更多机器,增加集群机器数量,抗更多流量)
提高配置(给更多内存、宽带等)
读写分离(写主读从;COW写时复制)
 堆硬件(通过添加更多机器,增加集群机器数量,抗更多流量)
堆硬件(通过添加更多机器,增加集群机器数量,抗更多流量)串行转并行
使用并行 API 将消息发到MQ中,负载均衡给多个消费者,增加消费能力
同步转异步
减少资源利用(压缩、合并、复用、减少输出、减少上下文切换、减少指令)
池化(线程池、连接池、对象池)
压缩、合并、复用、减少输出、减少上下文切换、减少指令
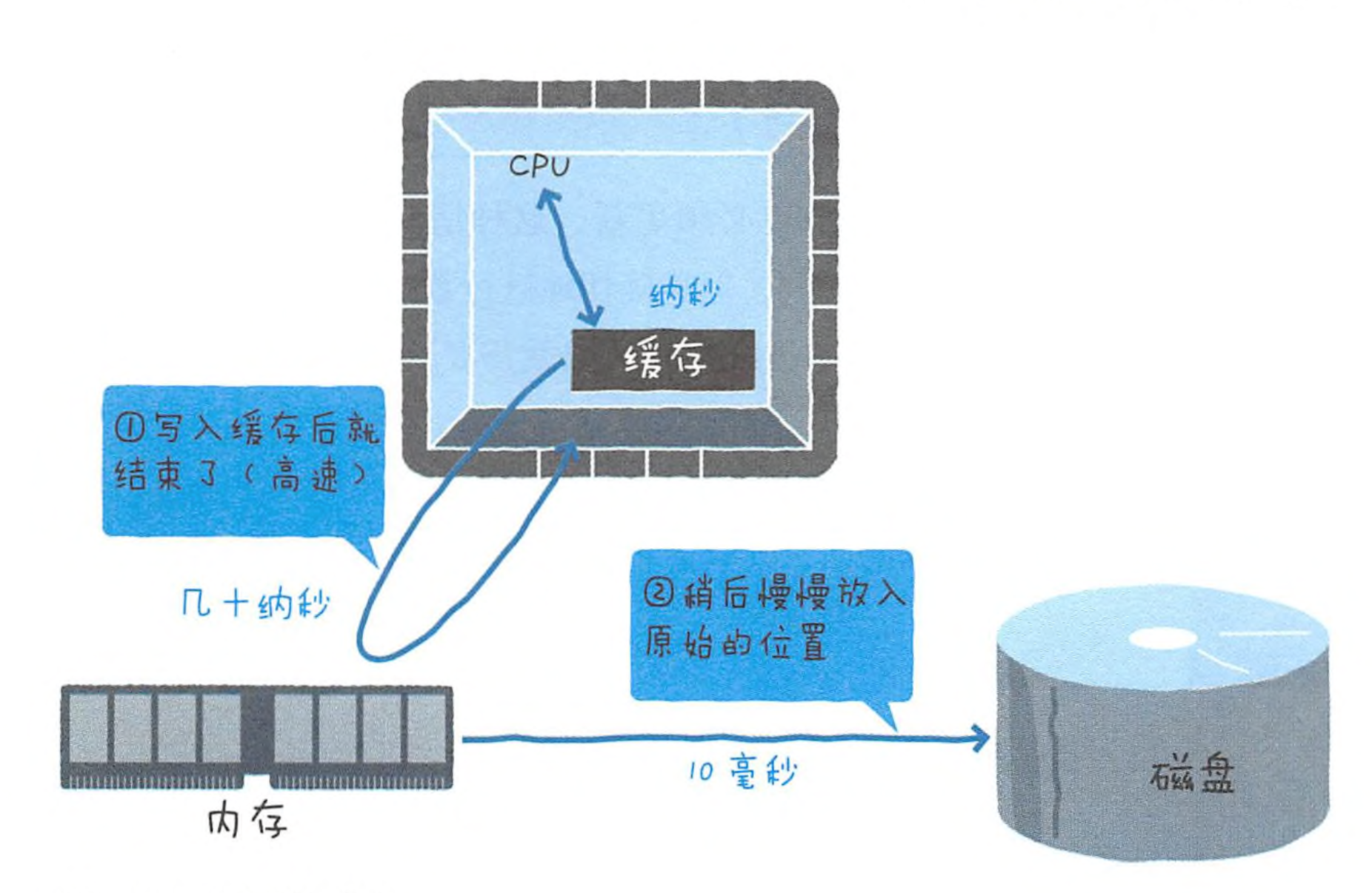
时空局部性
发挥各方面的优势(选择合理的数据结构、合理的中间件等)
比如开发时要用 Set 去重,而不是 List
比如 HashMap 冲突时拉链,链表大于 8个 转为红黑树
使用 Redis,如果适合用 Set 结构的就不要每次都拼接成 String 存储,每次取出来再切割再用。
比如 MySQL 的 InnoDB 选用 B+ 树,主要是层数低,这样IO次数就少,每个叶子节点构成链表,那么范围查找就比较容易。
根据技术特点进行优化(深翻页问题、属性转换问题)
深翻页问题,通过移动 where 条件来实现永远只查第一页,提高性能 手动写 get/set 转换方法或者使用基于字节码增强的属性转换工具,比基于反射的属性转换工具性能好
降低冲突(时间、空间)的范围
分段加锁
COW
乐观锁
反推产品来优化性能(加限制条件)
比如消息推送即使优化,千万的消息也得发3分钟,产品本来想要提前5分钟发到用户手中。是不是可以和产品商量提前10分钟发? 比如 ES深翻页有性能问题,是不是和产品商量下限制只能搜出2000条?
2. 4 注意事项
2.4.1 避免过早优化
过早优化是万恶之源。
比如业务发展初期,最重要的是迎合市场,抢占市场份额,那么如果某个功能性能一般,但是不特别影响用户体验,也可以后面再优化。
2.4.2 考虑投入产出比
如果一个功能投入很大,优化效果不好,那么是不是要三思而后行呢?
2.4.3 考虑正确性
性能优化的同时一定要考虑正确性,如果优化之后连正确性都无法保证优化有啥意义呢?
性能优化要伴随着更多的测试来保证正确性。
2.4.4 考虑稳定性
2.4.5 考虑拓展性、可读性、考虑安全性
性能很好,但是可读性很差,可拓展性、安全性很差,那么就容易埋下很多隐患。
比如为什么外国人很少用 fastjson,其中一个重要原因是里面有很多硬编码的东西,而且总是爆出安全漏洞。
等
2.5 图书推荐
性能之巅(强力土建)
图解性能优化
web性能权威指南
java 性能权威指南
深入理解计算机系统
3、案例
3.1 版本号导致性能问题
回到开头的案例
有一张订单表为了保持订单记录,更新数据时不能删除,需要打算加上版本号,查询时取版本号最新的给前端,还有场景是查询订单历史给前端。 订单表量一般不会太小,每次先分组查询取出最大的一条,然后外层再去取对应的数据再分页显然性能不好。 怎么办?
1 空间换时间
另外见一个订单历史记录表,专门供查询历史记录。
首次创建,修改订单时将记录插到历史记录表中,然后直接更新订单表记录即可。
这样加上索引,查询订单列表很快,查询订单历史记录也很快。
2 选择合适技术(存储方式)
订单表可能比较大,订单历史更大,虽然有索引,但是数据量超过千万也会很慢。
可能要考虑分库分表。
那么可以将订单表使用MySQL,订单历史表使用 HBase。 这样订单历史表数据量大也不慢。
3 根据技术特点进行优化
如 rowkey 设计 shopid_order_id 如果某个店铺数据量超大,容易成为热点,
数据会倾斜 那么可以设计为 reverse(shopid_order_id) 作为 rowkey
可能还有更好的方案,这里知识举一个例子。
3.2 直播优化
比如直播业务,预计会有几百万用户在几分钟时间内涌入,直播前几天陆续会有一些用户订阅直播,大多数用户会在直播开始前后5分钟进入。 如何优化?
1 压力测试,服务器扩容(硬件方面)
2 活动前预热(软件方面)
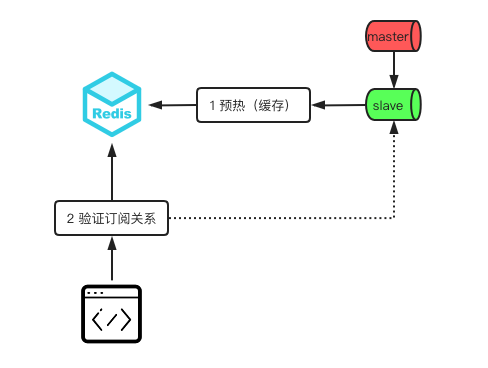
根据直播id 和活动时间,设置直播前 N 分钟预热,将购买的结果缓存起来;
如果退订也可以删除缓存,退订毕竟是少数 下图的 redis 为 redis 集群 通过预热的方式,用户短时间涌入直播间鉴权时,大多数流量打到缓存集群中,DB 压力会很小。
3 基于 Hytrix 降级(到重试页面)或者限流
3.3 报表导出
比如某个场景,假设某个节点用户必然会下载某个文件,这个文件的生成比较耗时。
两种常见的选择
-
异步
-
预先生成
那么可以在用户下载某个文件之前的某个事件提前生成好待下载的文件,用户需要下载的时候就可以迅速下载,体验极佳。
这也体现了用空间换时间的概念。
更多示例,请直接看配套的直播录屏。
4、汇总
5、总结
本文主要讲解我的性能优化方法论,最根本的思考方向到核心的优化原则再到具体的优化案例,希望能够帮助大家理解性能优化的本质,掌握性能优化的核心思路,帮助大家在实际的工作中少走弯路。
大家在考虑性能优化时,可以把多个核心原则结合在一起,另外要考虑自己设计的局限性或者缺点,还要进行充分的测试保证正确性。
文章配套资料:https://gitee.com/mingmingruyue/live_share
文章配套的直播录屏:https://www.bilibili.com/video/BV1Wi4y137Ge/
创作不易,如果你觉得本文对你有帮助,欢迎关注、点赞、评论。你的支持和鼓励是我创作的最大动力。
想了解更多开发和避坑技巧,经验,学习方法少走弯路,
欢迎关注本人的慕课专栏:
再学经典:《Effective Java》独家解析
解锁大厂思维:剖析《阿里巴巴 Java 开发手册》
共同学习,写下你的评论
评论加载中...
作者其他优质文章


