
一:背景
1. 讲故事
最近看各大技术社区,不管是知乎,掘金,博客园,csdn基本上看不到有小伙伴分享sqlserver类的文章,看样子这些年sqlserver没落了,已经后继无人了,再写sqlserver是不可能再写了,这辈子都不会写了,只能靠技术输出mysql维持生活这样子。
二:了解架构图
mysql最大的好处就是开源, 手握百万源码,有什么问题搞不定呢? 这一点要比sqlserver爽多了,不用再dbcc捣来捣去。
1. 从架构图入手
大家都知道做/装修房子都要有一张图纸,其实软件也是一样,只要有了这么一张图纸,大方向就定下来了,再深入到细节也不会乱了方向,然后给大家看一下我自己画的架构图,画的不对请轻拍。

其实SqlServer,Oracle,MySql架构都大同小异,MySql的鲜明特点就是存储引擎做成了插拔式,这就牛逼了,现行最常用的是InnoDB,这就让我有了一个想法,有一套业务准备用 InMemory 模式跑一下,厉害了~~~
2. 功能点介绍
MySql其实就两大块,一块是MySql Server层,一块就是Storage Engines层。
<1> Client
不同语言的sdk遵守mysql协议就可以与mysqld进行互通。
<2> Connection/Thread Pool
MySql使用C++编写,Connection是非常宝贵的,在初始化的时候维护一个池。
<3> SqlInterface,Parse,Optimizer,Cache
对sql处理,解析,优化,缓存等处理和过滤模块,了解了解即可。
<4> Storage Engines
负责存储的模块,官方,第三方,甚至是你自己都可以自定义实现这个数据存储,这就把生态做起来了,🐮👃。
三: 源码分析
关于怎么去下载mysql源码,这里就不说了,大家自己去官网捣鼓捣鼓哈,本系列使用经典的 mysql 5.7.14版本。
1. 了解mysql是如何启动监听的
手握百万行源码,怎么找入口函数呢??? 😁😁😁,其实很简单,在mysqld进程上生成一个dump文件,然后看它的托管堆不就好啦。。。

从图中可以看到,入口函数就是 mysqld!mysqld_main+0x227 中的 mysqld_main, 接下来就可以在源码中全文检索下。
<1> mysqld_main 入口函数 => sql/main.cc
extern int mysqld_main(int argc, char **argv);
int main(int argc, char **argv)
{
return mysqld_main(argc, argv);
}
这里大家可以用visualstudio打开C++源码,使用查看定义功能,非常好用。
<2> 创建监听
int mysqld_main(int argc, char **argv)
{
//创建服务监听线程
handle_connections_sockets();
}
void handle_connections_sockets()
{
//监听连接
new_sock= mysql_socket_accept(key_socket_client_connection, sock,
(struct sockaddr *)(&cAddr), &length);
if (mysql_socket_getfd(sock) == mysql_socket_getfd(unix_sock))
thd->security_ctx->set_host((char*) my_localhost);
//创建连接
create_new_thread(thd);
}
//创建新线程处理处理用户连接
static void create_new_thread(THD *thd){
thd->thread_id= thd->variables.pseudo_thread_id= thread_id++;
//线程进了线程调度器
MYSQL_CALLBACK(thread_scheduler, add_connection, (thd));
}
至此mysql就开启了一个线程对 3306 端口进行监控,等待客户端请求触发 add_connection 回调。
2. 理解mysql是如何处理sql请求
这里我以Insert操作为例稍微解剖下处理流程:
当用户有请求sql过来之后,就会触发 thread_scheduler的回调函数add_connection。
static scheduler_functions one_thread_per_connection_scheduler_functions=
{
0, // max_threads
NULL, // init
init_new_connection_handler_thread, // init_new_connection_thread
create_thread_to_handle_connection, // add_connection
NULL, // thd_wait_begin
NULL, // thd_wait_end
NULL, // post_kill_notification
one_thread_per_connection_end, // end_thread
NULL, // end
};
从 scheduler_functions 中可以看到,add_connection 对应了 create_thread_to_handle_connection,也就是请求来了会触发这个函数,从名字也可以看出,用一个线程处理一个用户连接。
<1> 客户端请求被 create_thread_to_handle_connection 接管及调用栈追踪
void create_thread_to_handle_connection(THD *thd)
{
if ((error= mysql_thread_create(key_thread_one_connection, &thd->real_id, &connection_attrib,
handle_one_connection,(void*) thd))){}
}
//触发回调函数 handle_one_connection
pthread_handler_t handle_one_connection(void *arg)
{
do_handle_one_connection(thd);
}
//继续处理
void do_handle_one_connection(THD *thd_arg){
while (thd_is_connection_alive(thd))
{
mysql_audit_release(thd);
if (do_command(thd)) break; //这里的 do_command 继续处理
}
}
//继续分发
bool do_command(THD *thd)
{
return_value= dispatch_command(command, thd, packet+1, (uint) (packet_length-1));
}
bool dispatch_command(enum enum_server_command command, THD *thd, char* packet, uint packet_length)
{
switch (command) {
case COM_INIT_DB: .... break;
...
case COM_QUERY: //查询语句: insert xxxx
mysql_parse(thd, thd->query(), thd->query_length(), &parser_state); //sql解析
break;
}
}
//sql解析模块
void mysql_parse(THD *thd, char *rawbuf, uint length, Parser_state *parser_state)
{
error= mysql_execute_command(thd);
}
<2> 到这里它的Parse,Optimizer,Cache都追完了,接下来看sql的CURD类型,继续追。。。
//继续执行
int mysql_execute_command(THD *thd)
{
switch (lex->sql_command)
{
case SQLCOM_SELECT: res= execute_sqlcom_select(thd, all_tables); break;
//这个 insert 就是我要追的
case SQLCOM_INSERT: res= mysql_insert(thd, all_tables, lex->field_list, lex->many_values,
lex->update_list, lex->value_list,
lex->duplicates, lex->ignore);
}
}
//insert插入操作处理
bool mysql_insert(THD *thd,TABLE_LIST *table_list,List<Item> &fields, List<List_item> &values_list,
List<Item> &update_fields, List<Item> &update_values,
enum_duplicates duplic, bool ignore)
{
while ((values= its++))
{
error= write_record(thd, table, &info, &update);
}
}
//写入记录
int write_record(THD *thd, TABLE *table, COPY_INFO *info, COPY_INFO *update)
{
if (duplicate_handling == DUP_REPLACE || duplicate_handling == DUP_UPDATE)
{
// ha_write_row 重点是这个函数
while ((error=table->file->ha_write_row(table->record[0])))
{
....
}
}
}
可以看到,调用链还是挺深的,追到 ha_write_row 方法基本上算是追到头了,再往下的话就是 MySql Server 给 Storage Engine提供的接口实现了,不信的话继续看呗。。。
<3> 继续挖 ha_write_row
int handler::ha_write_row(uchar *buf)
{
MYSQL_TABLE_IO_WAIT(m_psi, PSI_TABLE_WRITE_ROW, MAX_KEY, 0,{ error= write_row(buf); })
}
//这是一个虚方法
virtual int write_row(uchar *buf __attribute__((unused)))
{
return HA_ERR_WRONG_COMMAND;
}
看到没有,write_row是个虚方法,也就是给底层方法实现的,在这里就是给各大Storage Engines的哈。😁😁😁
3. 调用链图
这么多方法,看起来有点懵懵的吧,我来画一张图,帮助大家理解下这个调用堆栈。
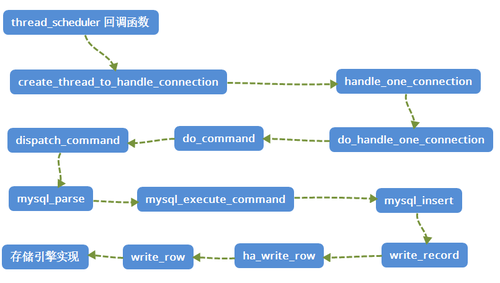
三:总结
大家一定要熟读架构图,有了架构图从源码中找信息就方便多了,总之学习mysql成就感还是满满的😁。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


