
在这篇和接下来的几篇文章中,我们将用最通俗的语言介绍机器学习中的神经网络概念和算法思路,尽可能让每个普通人都能听懂。
什么是神经网络NN(artificial neural network)?
就是用数学算法和计算机,参照动物(包括人类)大脑的神经结构,建立的模拟系统,科学家们希望以这样的方式不断进化扩展,能够模拟人类大脑的行为和能力。
简单说NN就是电子神经大脑。
人类大脑主要有三个关键要素:数以百亿的神经元,更加庞大的互相交错的神经元之间的连接,以及这些神经元和连接是如何运作的机制。
什么是神经元(neuron)?
人类大脑的神经元是我们思维的基础,我们之所以能够看听读写,进行各种思考都是大脑里800多亿神经元共同作用的结果。
粗糙的说,神经元有两种状态:激活(active),或未激活(inactive)。就像灯泡,开灯发光,还是关灯。
我们头脑里的每个念头,本质上都是不同组合的神经元被点亮。
比如我们脑海里浮现出“猫”这个概念的时候,可能只是第187、2933、1223、90、22323...3912等几千万个神经元被点亮。就像我们看到电视屏幕上出现一个“猫”字的画面,但本质上是电视屏幕数百万个像素被不同点亮而已。

“猫”念头示意
学习人工智能之前,请务必放下人类的高傲,从科学上认识我们自己的大脑。我们的意识之所以存在,只是神经元不停的变化而已,就像电视一直打开,像素一直闪烁变化一样。一旦电视关闭,所有神经元就很快完全停止下来,我们也就死亡了。
谁来开灯(active)?
是谁在不断点亮我们大脑中数以百亿的神经元?
当我们还未出生时候,当细胞还在分裂的时候,我们的神经元才出现的时候,它就启动了。
每个神经元不仅自己忽明忽暗的变化着,而且能够通过通过连接向其他数以千计的神经元传递信号,也能接受其他神经元传递过来的信号,并且能够根据这些传入的信号再调整发出新的信号。
这就像一张网,所有神经元互相影响,互为输出输入,互为因果,互相激活,互相抑制。
神经元互相激活互相抑制
这里仅是粗糙的说法,即使目前科学家也还没有能完全准确的描述人类大脑活动的细节机制。
如何形成意识?
首先我们必须明确,脑海里闪现的念头只不过是不同神经元组合被激活。
对于某一批神经元被激活的这个状态,我们可能叫做猫,也可能叫cat,也可以叫第87893中激活组合。
不停的有神经元被重新激活,同时也有很多已经激活神经元被抑制,变为未激活状态。这种不停的变化,就是我们的思想。
如果我们用心体验,就会发现,我们脑海里闪现的只是文字概念,而不是曾经被记忆的现实事物。我们脑海里会浮现“绿”字,但并没有绿色,绿色只存在于我们的视觉系统。
所以,人类意识的最小单元是文字字符,或者说是数字符号而已。
神经元的激活值Activation
目前人工神经网络中的神经元还是极简陋的,原则上只是一个数字,代表了这个神经元被激活的程度,比如我们规定0是未激活,1是全激活,那么0.5就是半激活的中间状态。
这个数字我们就叫做激活值activation。

神经元的不同的激活值状态
激活函数Activation function
由于我们使用计算机来模拟神经元,通过外部输入过来的信号计算这个activation激活值,有时候可能计算得到很大的数字比如几百多,那么就会导致各个神经元的激活值有的很大有的很小,而我们还是希望把它缩小到0~1之间更合理。
这时候我们会对直接计算的激活值进行一下处理,把它对应到0~1之间,最常用来做这个处理的函数就是Sigmoid函数:
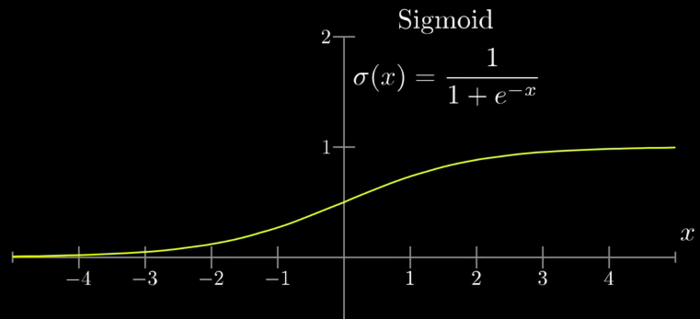
Sigmoid函数
也就是说:
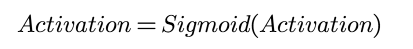
这里e是自然常数,固定值,就像π那样,e的近似值2.718。e-x中的-x次方等于1/ex,这样我们知道,x无限小的时候,1/e-x趋于无限大,1/(1+e-x)趋于0;而x无限大的时候,1/e-x趋于0,1/(1+e-x)趋于1;正好落在0~1之间。
但Sigmoid是个曲线函数,要乘方还要取倒数,对于数以万亿次的计算来说还是太复杂了,而且由于曲线过渡也太平滑,不利于干净利落的区分激活或不激活两种状态。所以后来大家就更多的改用RELU函数(rectified linear unit)。
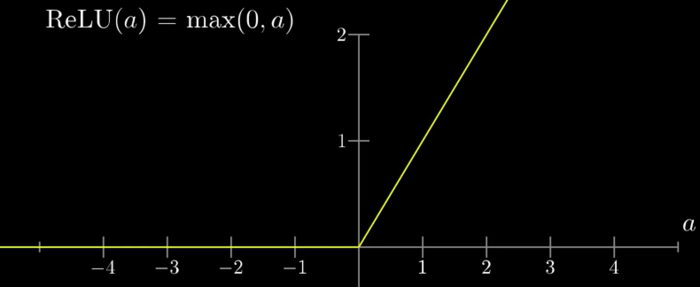
RELU函数
RELU是相当的简单粗暴,当a<0的时候,返回0;当a>0的时候,返回a。也就是如果直接算出来的激活值是负的,那么就直接改为0未激活,如果是正的,那么就保留这个值不变。——没错,它并不在01之间,而是0无穷大,所以一般还需要后续处理的,这在后面文章中会提到。
逐层抽象Layer
我们上面粗略的谈到神经元、神经网络和意识,意识就是神经网络中不同神经元被点亮的状态。
对于抽象的字符,人类大脑需要经过大量反复的训练,才能把眼睛看到的其他人随手写下的9字抽象成为“9”这个概念的。
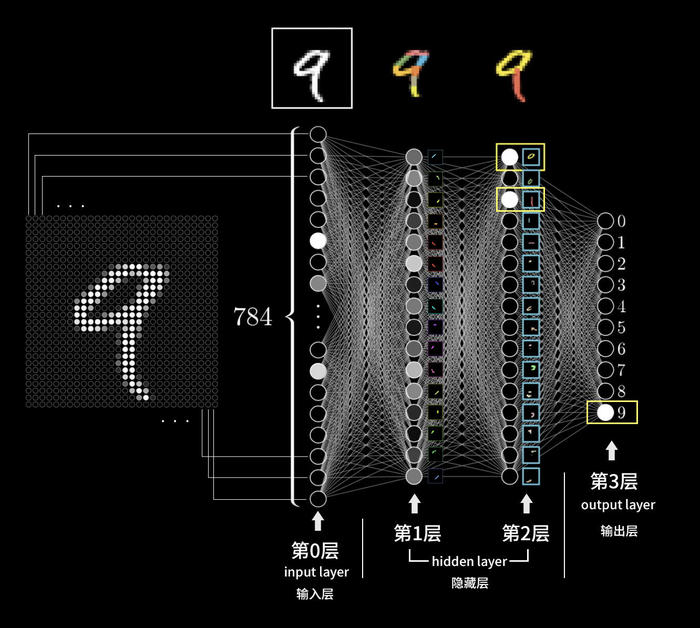
数字9图像被识别为“9”概念的过程
我们来逐层分解上面这个图。
首先是视网膜获得数以千万计的颜色信息(我们假设黑白图片只有亮度信息),我们可以理解每个视网膜细胞就是一个神经元,代表着一个表示颜色的数字,视网膜细胞就是一个神经元,它的亮度数字就是激活值。
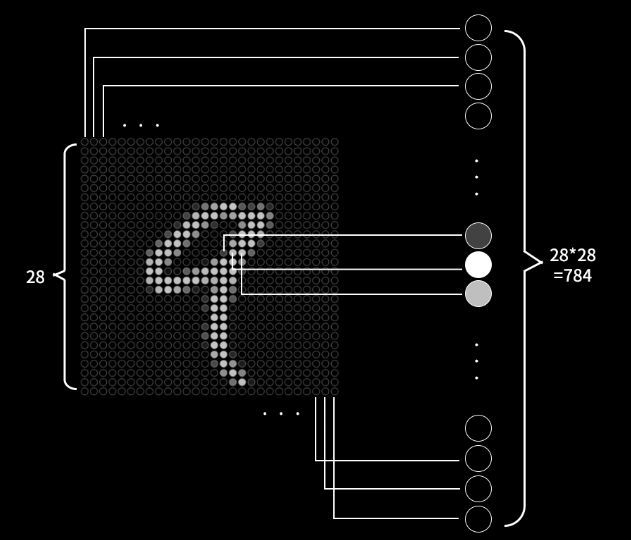
第0层 影像转换为神经元数据
视网膜层上的神经元捕获了图像,但并不能思考。它们把数据通过神经元连接传递到下一层,下一层也包含了很多的神经元,并且每个神经元会从视网膜层数千万的激活值中寻找到一些小的图案,比如一个小横线、小弧线之类。
每个不同小图案对应了不同的神经元,比如靠近下面的小横线对应这一层的第3个神经元,当我们发现视网膜传来的图像数据中包含靠下的小横线的时候,就点亮它。当然,我们看到的图像是复杂的,包含很多小图案,所以在这一层也就会点亮很多神经元,但肯定不会有前面视网膜层数千万那么多。

第一层 感知的一些小图案示意
从输入层数千万输入数据,变为第1层数千个,这就是神经元逐层抽象的过程。
我们把视网膜层叫输入层Input layer,计做第0层,识别小图案的一层算是第1层,因为我们实际上也搞不懂这一层到底是怎么识别的是哪些具体图案,这层很神秘,我们把这样的神秘层叫做隐藏层Hidden layer。你可以自己体验一下,我们看到猫的时候直接就识别了,完全不知道自己怎么做到的。
然后,第1层又会继续传递下去到达后面一层神经元,到达第2层。
第2层会用同样的方法,利用从第1层传来的数千神经元激活值(表示各种各样的小图案),从中识别出更高级一些的图形内容,比如小图案拼接成的小圆圈。

小图案拼接成大一级的图形
第2层我们也搞不懂到底是具体怎么进行的,也是神秘的,仍然是隐藏层。
如果继续下去,可能有很多隐藏层,逐层抽象。直到最后一层,从前一层是别的图形中直接可以识别出我们想要的“9”数字概念。

多个被激活的图案再激活输出层的最终结果
最后这一层我们叫做输出层,在上面的示意图中是最右面的第3层。
这里中间第1和第2两个隐藏层都是任意示意的16个神经元;最右面只有0~9共10个神经元,这也是极简化的示意情况。
权重weight和偏置bias
让我们回到神经网层级图。
数字9图像被识别为“9”概念的过程
我们看到每一个神经元的激活值都是前一层所有神经元连接激活的结果(输入层除外):
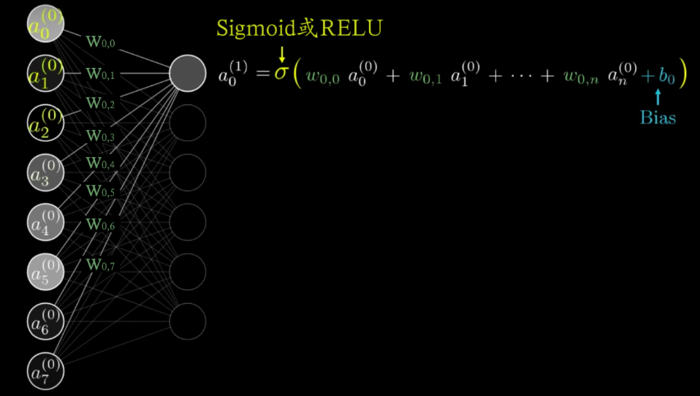
每个神经元激活值的计算方法
这个算法很简单,每个神经元都等于前一层所有神经元的加权和(每个前一层神经元激活值a,乘以它的权重w,然后加在一起),再经过激活函数Sigmoid或RELU处理。
注意上图还包含了一个Bias偏置值,用来限定被激活函数处理之前的最小值。
我们进一步考虑整个第n层的情况,那么就可以把它表示成一个由前一层所有神经元权重组成的矩阵,乘以前一层所有神经元激活值组成的向量,然后加上第n层每个神经元对应的偏置值,得到的是一个向量,对应了第n层每个神经元的激活值。
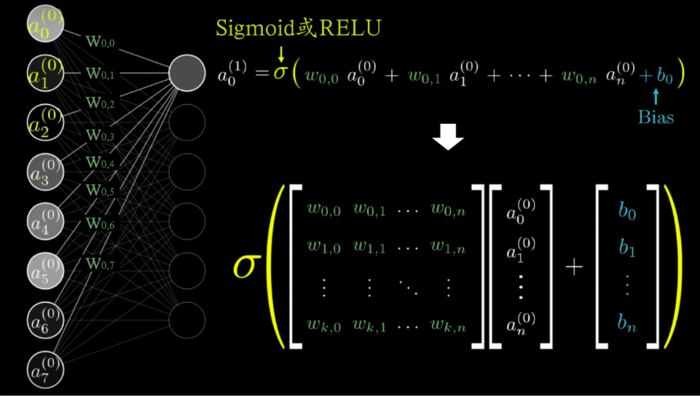
每层神经元激活值向量的计算方法
矩阵乘以向量规定:
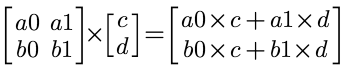
向量加法规定A(X1,Y1) B(X2,Y2),则A+B=(X1+X2,Y1+Y2),得到新的向量。
图中的σ(希腊字母西格玛)代表的就是激活函数:
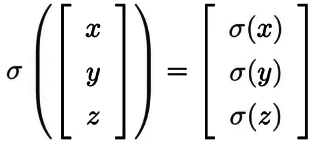
将以上算法整合展开就是:

每层神经元激活值向量的计算方法展开
远未结束
我们再回看这个图:
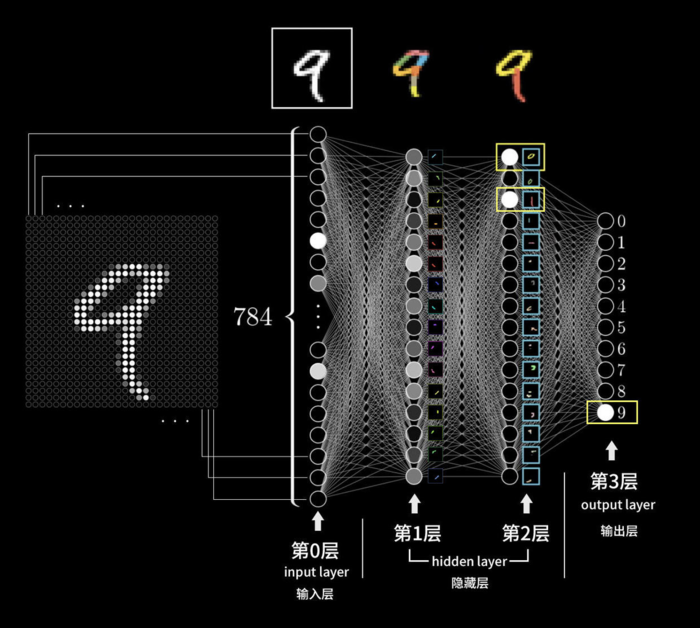
神经网络结构图
似乎我们已经完全掌握了每个神经元的算法,但根本没有!
因为这张图只是我们希望的样子,也就是每个权重w和每个偏置b都是恰恰好的时候,最终右侧输出层才能像我我们细微的那样点亮正确代表数字的神经元。
什么样的权重和偏置才是恰恰好的?
先说我们有多少个权重和偏置需要恰恰好呢?对于这个28x28=784个像素的输入值,如果我们如图有2个隐藏层每层16个神经元,那么第1层每个神经元需要784个权重w,共784x16=12544个w,以及16个偏置b;第2层需要16x16+16=256个权重w和16个偏置b;第三层需要10x16=160个权重和10个偏置b;这些加在一起是:
12544+256+160+16+16+10=13002
共有1万3千多个数字要恰恰好才能实现正确的分类!
机器学习的过程其实就是寻找着1万3千多个恰恰好的数字的过程,在下一篇文章中继续介绍。
本篇回顾
意识就是不同批次神经元不断被激活或被抑制
神经元就是一个决定它是否被激活的数字
或者一个可以计算出数字的函数,比如Sigmoid或RELU
算法就是前一层所有神经元激活值的加权和再加上偏置值
神经网络层就是一个权重矩阵×激活值向量+偏移值向量得到的一个向量
作者:zhyuzh3d
链接:https://www.jianshu.com/p/85cbfba3eb7b
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



