
前 言
解决的问题
我们在路边看到萌犬可爱至极,然后却不知道这个是哪种狗;看见路边的一个野花却不知道叫什么名字,吃着一种瓜,却不知道是甜瓜还是香瓜傻傻分不清……
细粒度图像分析任务相对通用图像任务的区别和难点在于其图像所属类别的粒度更为精细。
大体分类
细粒度分类目前的应用场景很广泛,现在的网络大多分为有监督的和半监督的。
有监督的做法基于强监督信息的细粒度图像分类模型,是在模型训练时,为了获得更好的分类精度,除了图像的类别标签外,还使用了物体标注框(bounding box)和部位标注点(part annotation)等额外的人工标注信息。
基于弱监督信息的细粒度图像分类模型,基于强监督信息的分类模型虽然取得了较满意的分类精度,但由于标注信息的获取代价十分昂贵,在一定程度上也局限了这类算法的实际应用。因此,目前细粒度图像分类的一个明显趋势是,希望在模型训练时仅使用图像级别标注信息,而不再使用额外的part annotation信息时,也能取得与强监督分类模型可比的分类精度。
了解了大体的做法,我将从一些paper入手,讲解目前细粒度图像分析的具体实现。
01
SCDA(Selective Convolutional Descriptor Aggregation)
是基于深度学习的细粒度图像检索方法。在SCDA中,细粒度图像作为输入送入Pre-Trained CNN模型得到卷积特征/全连接特征,如下图所示。
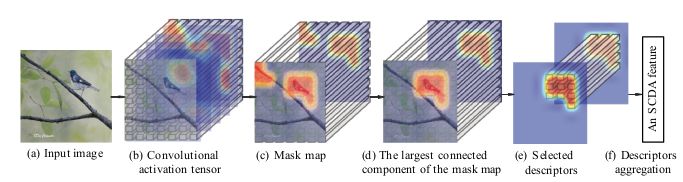
区别于传统图像检索的深度学习方法,针对细粒度图像检索问题,作者发现卷积特征优于全连接层特征,同时创新性的提出要对卷积描述子进行选择。
不过SCDA与之前提到的Mask-CNN的不同点在于,在图像检索问题中,不仅没有精细的Part Annotation,就连图像级别标记都无从获取。这就要求算法在无监督条件下依然可以完成物体的定位,根据定位结果进行卷积特征描述子的选择。对保留下来的深度特征,分别做以平均和最大池化操作,之后级联组成最终的图像表示。
很明显,在SCDA中,最重要的就是如何在无监督条件下对物体进行定位。
通过观察得到的卷积层特征,如下图所示,可以发现明显的"分布式表示"特性。
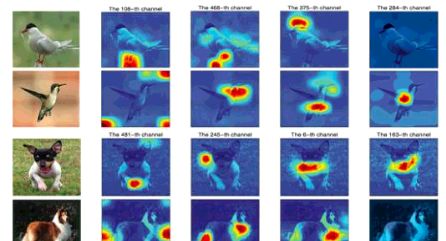
对两种不同鸟类/狗,同一层卷积层的最强响应也差异很大。如此一来,单独选择一层卷积层特征来指导无监督物体定位并不现实,同时全部卷积层特征都拿来帮助定位也不合理。例如,对于第二张鸟的图像来说,第108层卷积层较强响应竟然是一些背景的噪声。
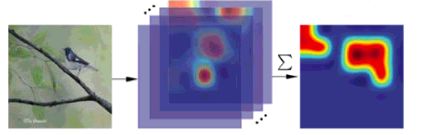
基于这样的观察,作者提出将卷积特征(HxWxD)在深度方向做加和,之后可以获得Aggregation Map(HxWx1)。
在这张二维图中,可以计算出所有HxW个元素的均值,而此均值m便是该图物体定位的关键:Aggregation Map中大于m的元素位置的卷积特征需保留;小于的则丢弃。
这一做法的一个直观解释是,细粒度物体出现的位置在卷积特征张量的多数通道都有响应,而将卷积特征在深度方向加和后,可以将这些物体位置的响应累积--有点"众人拾柴火焰高"的意味。
而均值则作为一把"尺子",将"不达标"的响应处标记为噪声,将"达标"的位置标为物体所在。而这些被保留下来的位置,也就对应了应保留卷积特征描述子的位置。
实验中,在细粒度图像检索中,SCDA同样获得了最好结果;同时SCDA在传统图像检索任务中,也可取得同目前传统图像检索任务最好方法相差无几(甚至优于)的结果,如下图所示。
02
RA-CNN (Recurrent Attention Convolutional Neural Network)
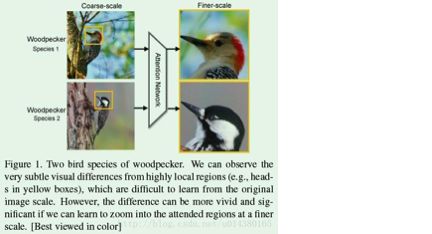
RA-CNN算法不需要对数据做类似bounding box的标注就能取得和采用类似bounding box标注的算法效果。在网络结构设计上主要包含3个scale子网络,每个scale子网络的网络结构都是一样的,只是网络参数不一样,在每个scale子网络中包含两种类型的网络:分类网络和APN网络。
数据流是这样的:输入图像通过分类网络提取特征并进行分类,然后attention proposal network(APN)网络基于提取到的特征进行训练得到attention区域信息,再将attention区域crop出来并放大,再作为第二个scale网络的输入,这样重复进行3次就能得到3个scale网络的输出结果,通过融合不同scale网络的结果能达到更好的效果。
针对分类网络和APN网络设计两个loss,通过固定一个网络的参数训练另一个网络的参数来达到交替训练的目的.
如下图所示,网络能够逐渐定位attention area,然后再将此区域放大,继续作为第二个scale网络的输入。
作者:夏敏 原文出处
共同学习,写下你的评论
评论加载中...
作者其他优质文章



