
阻塞IO模型(Blocking I/O)
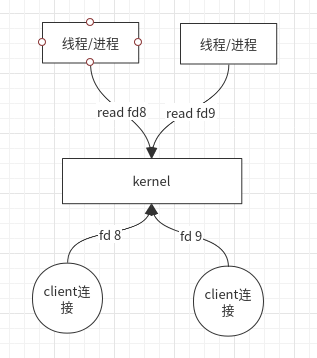
Linux 内核一开始提供了 read 与 write 阻塞式操作。
- 当客户端连接时,会在对应进程的文件描述符目录(/proc/进程号/fd)生成对应的文件描述符(0 标准输入;1 标准输出;2 标准错误输出;),比如 fd 8 , fd 9;
- 应用程序需要读取的时候,通过系统调用
read (fd8)读取,如果数据还没到来,此应用程序的进程或线程会阻塞等待。
man 2 read
概述
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
描述
read() 从文件描述符 fd 中读取 count 字节的数据并放入从 buf 开始的缓冲区中.
如果 count 为零,read()返回0,不执行其他任何操作. 如果 count 大于SSIZE_MAX,那么结果将不可预料.
返回值
成功时返回读取到的字节数(为零表示读到文件描述符), 此返回值受文件剩余字节数限制.当返回值小于指定的字节数时 并不意味着错误;这可能是因为当前可读取的字节数小于指定的 字节数(比如已经接近文件结尾,或
者正在从管道或者终端读取数 据,或者 read()被信号中断). 发生错误时返回-1,并置 errno 为相应值.在这种情况下无法得知文件偏移位置是否有变化.
问题
如果出现了很多的客户端连接,比如1000个,那么应用程序就会启用1000个进程或线程阻塞等待。此时会出现性能问题:
- CPU 会不停的切换,造成进程或线程上下文切换开销,实际读取IO的时间占比会下降,造成CPU算力浪费。
因此,推动了 non-blocking I/O 的诞生。
非阻塞IO模型(non-blocking I/O)
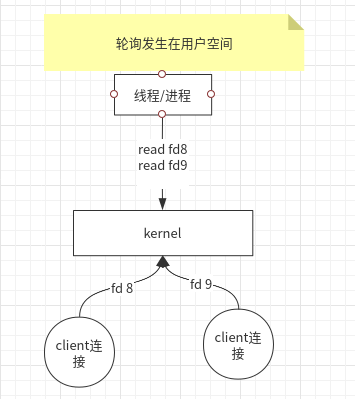
此时,Linux 内核一开始提供了 read 与 write 非阻塞式操作,可以通过socket设置SOCK_NONBLOCK标记 。
- 此时应用程序就不需要每一个文件描述符一个线程去处理,可以只有一个线程不停轮询去读取
read,如果没有数据到来,也会直接返回。 - 如果有数据,则可以调度去处理业务逻辑。
man 2 socket
Since Linux 2.6.27, the type argument serves a second purpose: in addition to specifying a socket type, it may include the bitwise OR of any of the following values, to modify the behavior of
socket():
SOCK_NONBLOCK Set the O_NONBLOCK file status flag on the open file description (see open(2)) referred to by the new file descriptor. Using this flag saves extra calls to fcntl(2) to achieve
the same result.
从这里可以看出来 socket Linux 2.6.27内核开始支持非阻塞模式。
问题
同理,当出现了很多的客户端连接,比如1000个,那就会触发1000次系统调用。(1000次系统调用开销也很客观)
因此,有了 select。
IO复用模型(I/O multiplexing) - select
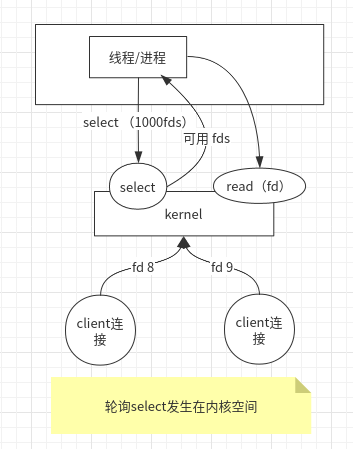
此时,Linux 内核一开始提供了 select 操作,可以把1000次的系统调用,简化为一次系统调用,轮询发生在内核空间。
select系统调用会返回可用的 fd集合,应用程序此时只需要遍历可用的 fd 集合, 去读取数据进行业务处理即可。
man 2 select
SYNOPSIS
#include <sys/select.h>
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
DESCRIPTION
select() allows a program to monitor multiple file descriptors, waiting until one or more of the file descriptors become "ready" for some class of I/O operation (e.g., input possible). A file
descriptor is considered ready if it is possible to perform a corresponding I/O operation (e.g., read(2), or a sufficiently small write(2)) without blocking.
select() can monitor only file descriptors numbers that are less than FD_SETSIZE; poll(2) and epoll(7) do not have this limitation. See BUGS.
可以看到支持传输多个文件描述符交由内核轮询。
问题
虽然从1000次系统调用,降为一次系统调用的开销,但是系统调用开销中需要传参1000个文件描述符。这也会造成一定的内存开销。
因此,有了 epoll。
select() can monitor only file descriptors numbers that are less than FD_SETSIZE; poll(2) and epoll(7) do not have this limitation. See BUGS.
IO复用模型(I/O multiplexing) - epoll
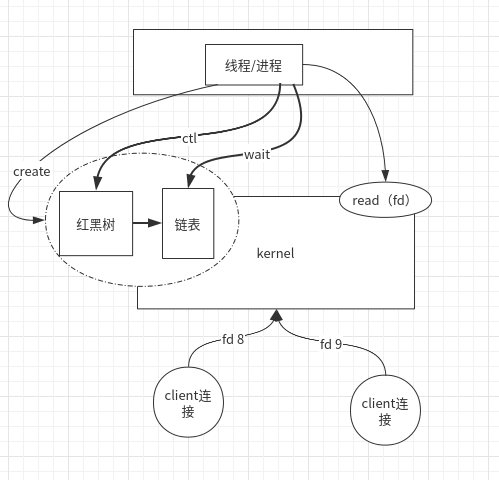
man epoll
man 2 epoll_create
man 2 epoll_ctl
man 2 epoll_wait
- epoll:
SYNOPSIS
#include <sys/epoll.h>
DESCRIPTION
The epoll API performs a similar task to poll(2): monitoring multiple file descriptors to see if I/O is possible on any of them. The epoll API can be used either as an edge-triggered or a
level-triggered interface and scales well to large numbers of watched file descriptors.
The central concept of the epoll API is the epoll instance, an in-kernel data structure which, from a user-space perspective, can be considered as a container for two lists:
• The interest list (sometimes also called the epoll set): the set of file descriptors that the process has registered an interest in monitoring.
• The ready list: the set of file descriptors that are "ready" for I/O. The ready list is a subset of (or, more precisely, a set of references to) the file descriptors in the interest list.
The ready list is dynamically populated by the kernel as a result of I/O activity on those file descriptors.
- epoll_create :
内核会产生一个epoll 实例数据结构并返回一个文件描述符epfd。
- epoll_ctl :
对文件描述符 fd 和 其监听事件 epoll_event 进行注册,删除,或者修改其监听事件 epoll_event 。
SYNOPSIS
#include <sys/epoll.h>
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
DESCRIPTION
This system call is used to add, modify, or remove entries in the interest list of the epoll(7) instance referred to by the file descriptor epfd. It requests that the operation op be performed
for the target file descriptor, fd.
Valid values for the op argument are:
EPOLL_CTL_ADD
Add an entry to the interest list of the epoll file descriptor, epfd. The entry includes the file descriptor, fd, a reference to the corresponding open file description (see epoll(7)
and open(2)), and the settings specified in event.
EPOLL_CTL_MOD
Change the settings associated with fd in the interest list to the new settings specified in event.
EPOLL_CTL_DEL
Remove (deregister) the target file descriptor fd from the interest list. The event argument is ignored and can be NULL (but see BUGS below).
- epoll_wait :
阻塞等待注册的事件发生,返回事件的数目,并将触发的可用事件写入epoll_events数组中。
扩展
其他IO优化技术
man 2 mmap
man 2 sendfile
man 2 fork
mmap:
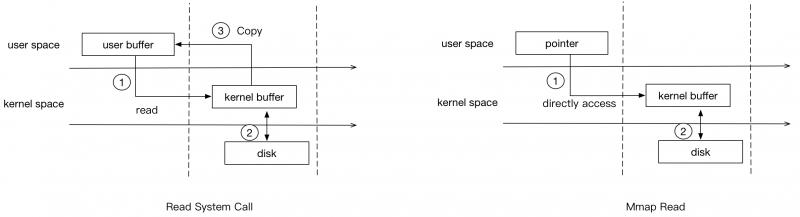
就是在用户的虚拟地址空间中寻找空闲的一段地址进行对文件的操作,不必再调用read、write系统调用,它的最终目的是将磁盘中的文件映射到用户进程的虚拟地址空间,实现用户进程对文件的直接读写,减少了文件复制的开销,提高了用户的访问效率。
以读为例:
-
深入剖析mmap原理 - 从三个关键问题说起: https://www.jianshu.com/p/eece39beee20
-
使用场景
kafka的数据文件就是用的mmap,写入文件,可以不经过用户空间到内核的拷贝,直接内核空间落盘。
再比如Java中的MappedByteBuffer底层在Linux就是mmap。
sendfile:
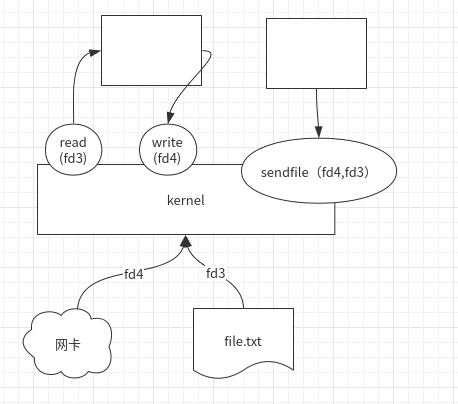
sendfile系统调用在两个文件描述符之间直接传递数据(完全在内核中操作),从而避免了数据在内核缓冲区和用户缓冲区之间的拷贝,操作效率很高,被称之为零拷贝。
- 使用场景
比如 kafka,消费者进行消费时,kafka直接调用 sendfile(Java中的FileChannel.transferTo),实现内核数据从内存或数据文件中读出,直接发送到网卡,而不需要经过用户空间的两次拷贝,实现了所谓"零拷贝"。
再比如Tomcat、Nginx、Apache等web服务器返回静态资源等,将数据用网络发送出去,都运用了sendfile。
fork
man 2 fork
创建子进程有三种方式:
fork,调用后,子进程有自己的pid和task_struct结构,基于父进程的所有数据资源进行副本拷贝,主要是复制自己的指针,并不会复制父进程的虚存空间,并且父子进程同时进行,变量互相隔离,互不干扰。
现在Linux中是采取了Copy-On-Write(COW,写时复制)技术,为了降低开销,fork最初并不会真的产生两个不同的拷贝,因为在那个时候,大量的数据其实完全是一样的。
写时复制是在推迟真正的数据拷贝。若后来确实发生了写入,那意味着父进程和子进程的数据不一致了,于是产生复制动作,每个进程拿到属于自己的那一份,这样就可以降低系统调用的开销。
NOTES
Under Linux, fork() is implemented using copy-on-write pages, so the only penalty that it incurs is the time and memory required to duplicate the parent's page tables, and to create a unique
task structure for the child.
-
vfork,vfork系统调用不同于fork,用vfork创建的子进程与父进程共享地址空间,也就是说子进程完全运行在父进程的地址空间上,也就是子进程对虚拟地址空间任何数据的修改同样为父进程所见。并且vfork完子进程,父进程是阻塞等待子进程结束才会继续。 -
clone,可以认为是fork与vfork的混合用法。由用户通过参clone_flags 的设置来决定哪些资源共享,哪些资源副本拷贝。 由标志CLONE_VFORK来决定子进程在执行时父进程是阻塞还是运行,若没有设置该标志,则父子进程同时运行,设置了该标志,则父进程挂起,直到子进程结束为止。 -
总结
fork的用途
一个进程希望对自身进行副本拷贝,从而父子进程能同时执行不同段的代码。
比如redis的RDB持久化就是采用的就是fork,保证副本拷贝的时点准确,并且速度快,不影响父进程继续提供服务。vfork的用途
用vfork创建的进程主要目的是用exec函数先执行另外的程序。clone的用途
用于有选择地设置父子进程之间哪些资源需要共享,哪些资源需要副本拷贝。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



