
开篇思考
- Redis 为什么在系统中使用?解决了哪些问题?
- Redis 如何保证和数据库同步?
- Redis 缓存操作是在操作数据库前还是操作数据库后?
话还得从上次报税说起,耳边还回绕这残留的芬芳:“SX系统,这也不能点,那也不能用!”,
身为程序员的我听到总是百感交集,程序员背锅是免不了了。。。
上线至今都能用的系统,突然就不行了,为什么?问题就在稳定性和系统架构上,发现问题就要吸取经验和血的教训。
我也特别喜欢吐槽,我觉得正确的吐槽姿势有助于系统的良性发展,就像父母的爱强烈扎刺着程序员面临崩溃的心灵,流出的爱的液体浇灌给系统茁壮成长。

系统稳定,快速,美如画谁都想追求,可是往往美好的东西后面代价也不小。
追求可靠,我们需要+集群部署,容错容灾,那么就需要更多的机器设施及其他附属服务。
追求快速,我们需要解决地域限制,全球部署战斗机,DNS 快速定位访问,软件层面缓存技术。
那么接下来我们就来扒一扒分布式系统架构中 Redis 的使用,进入正题,不扯蛋了。
让我们看看 Redis 给分布式系统带来哪些好处和问题的解决方案,看看这些代价是否值得。
Redis 简介
- 内存存储,速度极快
- key-value 存储结构
- 支持 string,list,set,zset,hash 类型,其实还有一些不常用的
- 基于 epoll 多路复用,串行执行效率高
- 可以持久化数据,遇到宕机可以快速恢复
- redis 支持主从模式、哨兵模式
- 使用场景丰富:热点数据缓存、临时会话存储、消息发布订阅、网页计数
上面的介绍中,我基本扒出了 redis 的主要特点,外衣都给你扒了,这么赤裸的诱惑你们都不要吗?觉得还是不够吸引吗?
那我们就继续来扒拉扒拉。。。

内存
Redis 都是通过计算机内存来存取的,不用多解释。它为什么快? JMM java 中的内存模型大家了解吧,java 中每个线程会有自己的内存,要想达成可见性,需要同步主内存,这一操作听起来
很简单,但其实里面数据被拷贝了多次。这里简单介绍下传统的磁盘到网络的数据拷贝流程:
- 磁盘到 read buffer, 快
- read buffer 到 user buffer ,此处很慢,上下文有切换
- user buffer 到 socket buffer ,快
- socket buffer 写入到网卡 buffer 发送,快
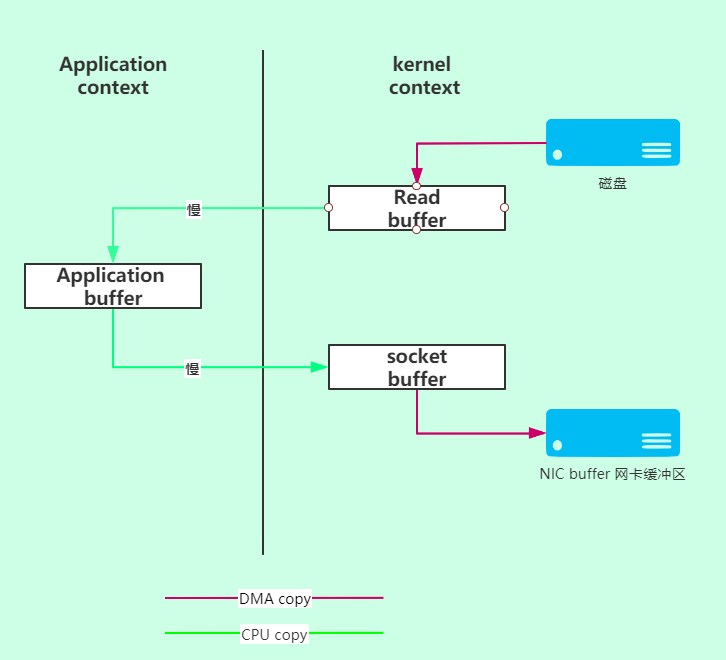
好家伙,不扒不知道,原来底层数据是这么传输的。Redis 为什么快呢,因为它官方只支持 linux 系统,而 Linux
本身还支持零拷贝技术,并且这里都是纯内存操作,所有的数据操作都非常快。那么究竟有多快呢,
一秒真男人:读 10 w/s;写 8w/s; 当然数据只能是小数据流量的。
零拷贝技术被广泛应用在 Java NIO,netty,kafka 等。
redis 实现系统的接口幂等控制
每个工程师都应该知道接口幂等的重要性,在分布式系统中,接口幂等的设计原则贯彻始终。 所谓接口幂等就是无论我在某个业务执行过程中调用多少次接口,得到的结果都应该和调用一次接口得到的结果一样。 因此我们知道查询、删除这些是天然幂等的,没有必要再做幂等性控制。 那么一般哪些接口需要实现幂等控制呢?redis 是起了什么作用?
- 新增接口
- 更新接口
- 任何内部包含新增、修改操作接口
redis 的串行机制,可以帮助我们轻松实现接口幂等性控制。我们在访问接口的时候,通过设置唯一性的 key token 来判断,
如果 redis 当前存有该 key 和 token, 那么就不执行业务逻辑,如果不存在则继续执行业务逻辑。
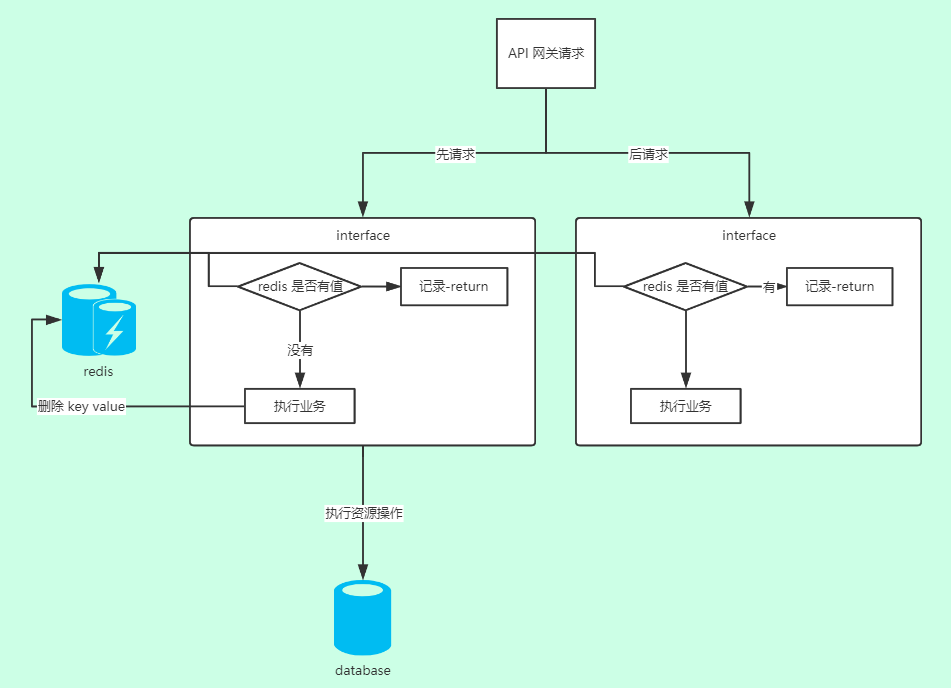
以上是一个简单的系统访问流程图,先执行的接口因为没有对应的 token 值,所以会继续执行业务,而另一个接口因为其他的接口没有执行结束,没有删除对应的 key value,所以不会执行资源操作。
实际的开发中,我们可能不会在每个接口中都通过这么一个逻辑来判断,而是通过拦截器、自定义注解来实现统一的判断逻辑.
当然 redis 不是唯一的方式来确保接口幂等,接口幂等的设计还可以通过数据库去重表、表中的状态机等机制来实现。
redis 实现分布式锁
在分布式集群系统中,我们不能也不会让所有的请求都在同一个服务上,那么高并发请求下,
如何给接口上锁来保证接口的串行执行? redis string 类型有个方法可以在接口中使用, setnx : set if not exit。 通过此函数来设置分布式锁。
在接口中通过 setnx 给当前接口设置一个全局唯一的值,可以是 商品Id + 接口信息;
当并发访问该接口的时候,会再次调用 setnx 来判断是否存在值:
- 第一次设值,成功,返回 1 ;
- 有值,设置失败,返回 0;
下面的例子是基于 lettuce 连接的 RedisTemplete 设置锁代码,其中 tryLock 是伪代码,具体使用根据实际情况。
/**
* 尝试获取锁 ,并返回结果
* @param key
* @param value
* @param expireTime (此处为秒)
* @return boolean
* @author holy
* @date 2020年4月08日
*
*/
public boolean tryAcquire(String key, String value, long expireTime){
return redisTemplate.opsForValue().setIfAbsent(key,value, Duration.ofSeconds(expireTime));
}
/**
* 设置分布式锁
* @param key
* @param value
* @param expireTime (此处为秒)
* @return boolean
* @author holy
* @date 2020年4月08日
*
*/
public boolean tryLock(String key, String value, long expireTime){
boolean tryAcquire = tryAcquire(key, value, expireTime);
// 伪代码,根据实际情况谨慎使用
// 根据实际情况使用,如果不需要自旋,不理解自旋锁,或者不够了解 AQS 的不建议使用
// 此处主要是自旋固定 10 次
int i = 10;
if (!tryAcquire){
for (;;){
i--;
if (tryAcquire){
return Boolean.TRUE;
}
if (i < 1){
return Boolean.FALSE;
}
}
}
return Boolean.TRUE;
}
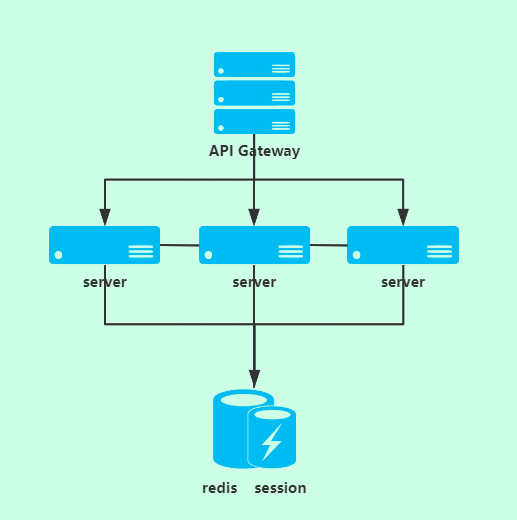
redis 管理分布式共享 session
在分布式系统中,因为我们的服务是集群部署,服务可能不是在同一台机器上面。这时候就会发现 session 引发的问题: * 如果请求是链路结构,请求可能会分发到不同的机器不同的服务上,多个服务无法共享 session
- 一旦服务不可用,即使恢复服务,也无法恢复 session
- session 管理困难
因此引入 session 共享被广泛的应用,redis 就是非常好的一种选择,而且据说和 spring session 完美结合。
这个非常简单,以前使用 springboot 1.5 的时候是通过引入依赖,添加配置进行的,这里简单贴下代码,
springboot 2.X 的应该差不多,支持应该只会更好、更简单的配置。
<!-- spring session redis -->
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
# ============ srping session ============
spring.session.store-type=redis
spring.session.redis.flush-mode=on_save
spring.session.redis.namespace=madmin
@EnableRedisHttpSession(maxInactiveIntervalInSeconds = 10800)
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args); } }
redis 在架构中的缓存中间件
redis 因为高并发、快速的特性,还被广泛应用在系统的缓存架构中。 在流量分布式系统中,我们的请求如果全部访问数据库将会是一场灾难, 数据库很可能会因为不堪重负被干趴,而数据库的不可用会造成更严重的服务不可用甚至雪崩效应。
因此在系统架构设计都会加入缓存中间件来缓解数据库压力,减少请求直接到数据库,提高系统性能。 尤其在大流量的系统设计的时候,例如秒杀系统,缓存中间件就必不可少。 redis 的特性天然的成为了缓存中间件的首选。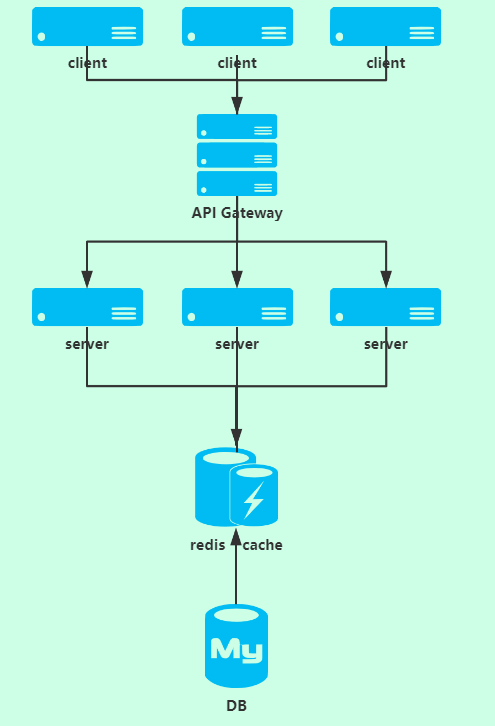
那么 redis 里到底存什么呢?下面我以秒杀系统为例列出:
- 秒杀商品具体信息
- 秒杀商品热门排行榜列表
- 秒杀商品库存信息
在秒杀系统中,大部分会请求会去查询商品信息,排行榜等信息,这些信息并不会经常变动,也不会要求非常高的一致性,
因此十分适合放入缓存中。那么怎么接口中如何设计呢?
接口设计的时候,用户请求的数据,全部都在 redis 中获取,如果 redis 中没有,才去数据库中获取,然后更新 redis。 这样在请求接口的时候,理想的状态,如果商品全部缓存成功在 redis 里,那么用户只会从 redis 获取数据,
不会有请求到达数据库层。
但是理想状态只能是理想状态,实际上我们会遇到一些问题,比如缓存击穿、缓存穿透:
- 缓存击穿:热点数据失效,就像就像瞬间高压电击一样击穿了 redis 缓存,缓存失效直接访问数据库
- 缓存穿透:redis 里面没有数据,DB 中也没有数据,所有请求直接访问 DB,造成缓存穿透
- 缓存雪崩:说有缓存集体失效,导致服务不可用。
怎么解决?
- 缓存击穿:定时任务后台刷新;设置长久模式;加分布式锁;
- 缓存穿透:缓存空值,即使没有数据也做缓存;布隆过滤器,;
- 缓存雪崩:预热数据;redis 高可用;redis 限流;
如果对布隆过滤器不是很了解的,可以看下这篇文章
《高并发架构中一定要考虑的Bloom Filter 布隆过滤器》
思考题
用了缓存技术,那么我们更新数据的时候,是先更新缓存还是先更新数据库呢?建议大家把情况列出来然后逐一分析问题。 也欢迎大家在评论区写出自己的答案。
今天就写到这里了,晚上我还有十几个亿的生意要谈。。。再会!
喜欢文章请关注我
程序领域
共同学习,写下你的评论
评论加载中...
作者其他优质文章


