
好几天没有更新文章,主要这几天都在赶网盘系统的客户端功能,已经完成一版同步到了gitee里面,因此把这几天开发的思路、遇到的问题等等记录下来。
本章的内容是跟上一篇文章是有关联的如何设计一款中间件客户端,体验一把架构师的瘾,上一篇文章主要是讲解客户端的规划思路,这里主要讲解技术落地的实现。
一、本节内容的需求分析
第一)了解网盘系统的架构和业务,方便理解本节内容
https://gitee.com/zwyyf/netdisk
第二)<<如何设计一款中间件客户端,体验一把架构师的瘾>>这篇文件讲解了相关的架构思想
本节主要实现一个jar,这个jar提供给其他业务系统集成,举例说明:某个单位它内部由不同的厂商开发了不同的项目,这些项目独立管理自己的文件,这些项目运行了若干年之后,发现文件太多太乱了,根本没有统一的管理,文件散落在不同的服务器,想查找某个文件,根本不懂其在哪个系统里面,因此,领导要求开发一套内部文件管理系统,各个厂商不能再独立管理自己的文件了,全部统一注册到网盘来统一管理。这样的好处如下:
第一)简化了各个业务系统的开发难度、不再需要独自维护文件,全部接口对接
第二)文件如何存储、海量文件如何存储和查找,这些业务系统根本不需要管理
第三)统一管理文件,有效的利用文件,为后期大数据分析做基础建设
二、业务系统采用什么方式对接网盘呢?
这个上一篇文件也详细讲解了思路,这里基于Http和TCP协议封装的客户端,而不是采用基于Dubbo和SpringCloud技术提供的API客户端,主要弊端如下:
①Dubbo、SpringCloud集成的jar太多,导致最终打包的太过臃肿
②技术限制,如果业务系统采用的不是Java开发的,或者Java开发但是人家有自己的技术框架,这样的话我们强制别的系统加入我们依赖的技术,非常的不友好
③采用自己开发sdk,依赖少量的第三方jar,打出来的包很小
主要封装了两套方案,基于HttpClient和Netty两种通讯模式,一个是短链接、一个是长连接。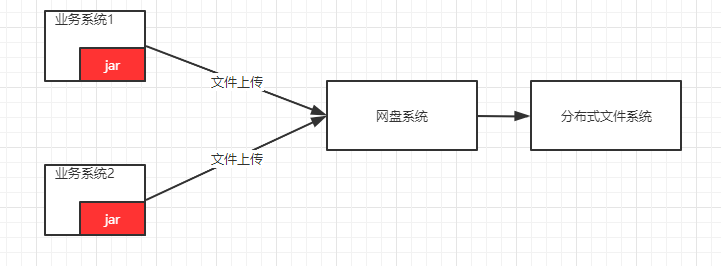
三、具体实现细节分析
3.1、项目创建:
netdisk
|-- netdisk-client
|-- netdisk-client-javasdk(真正核心代码实现)
|-- netdisk-spring-boot-starter(封装的SpringBootStarter)
|-- netdisk-client-provider(独立部署)
|-- netdisk-service-provider(独立部署)
为什么采用这种项目结构呢?
①网盘主要分为服务端和客户端,客户端是给业务系统集成,业务系统是一个未知的存在,因此我们可能会封装的sdk种类非常的多,因此使用一个netdisk-client父工程进行管理,下面的子工程则是具体的实现
②网盘的服务端独立netdisk-client-provider,controller工程的划分可以是按业务模块进行划分(比如:订单、商品),也可以按照客户端的种类进行划分(比如:h5、app、sdk、pc)
3.2、基本技术难点分析:
①netdisk-client-javasdk和netdisk-client-provider的通讯模式,主要两种,一种是基于HttpClient;另外一种是基于Netty来实现。
②Fastjson框架,远程通讯是基于byte[]传输的,我们需要把通讯层给封装起来,对应业务层来说,它是不知道byte[]存在的,因此需要通过json框架解析成实体,业务层面对的是实体编程。
③负载均衡,netdisk-client-provider工程压力将会非常的大,因此需要集群部署,那么业务系统需要传递的是多个路径,例如:host=ip1:port,ip2:port,sdk采用负载策略选择其中一个调用。【负载均衡前面的文件已经详细讲解过了】
④动态感知,业务系统配置host=ip1:port,ip2:port,如果其中ip2服务器宕机了,但是业务系统不知道其宕机了,可能还是会进行对其访问,导致访问超时。因此,sdk内部需要封装一个定时线程池,每隔一段时间对这些地址进行心跳检查,如果宕机了则剔除。
//定义线程池
private volatile static ScheduledExecutorService heartBeanEs=null;
heartBeanEs=Executors.newScheduledThreadPool(1);
//延迟1s,每隔5s检查一次
heartBeanEs.scheduleWithFixedDelay(new HeartBeatThread(), 1,5, TimeUnit.SECONDS);
//为了代码 整洁性,把相关异常、判断给去掉了
public class HeartBeatThread implements Runnable{
@Override
public void run() {
//1.用户配置的host信息
Set<HostBean> sets=FileFactory.hosts;
//2.存活的host信息,【Set是不可重复的】
Set<HostBean> actives=FileFactory.hosts;
Iterator<HostBean> it = sets.iterator();
while(it.hasNext()){
HostBean bean=it.next();
Socket s = new Socket();
SocketAddress add = new InetSocketAddress(bean.getIp(), bean.getPort());
s.connect(add, 1000);// 超时1秒
//如果连接成功,则往activeHosts新增
actives.add(bean);
//如果连接失败,则剔除
actives.remove(bean);
//关闭
s.close();
}
}
}
⑤单例+volatile,sdk内部所有的类都采用单例模式,避免业务系统大量的new对象造成内存浪费。volatile保证变量的内存可见性。
⑥多线程+线程池,由于sdk是处理文件上传的,因此属于IO密集型,因此线程池的核心线程数量应该根据IO密集型的公式来技术(大家可以网上搜索了解一下IO密集型)
3.3、文件上传分析
sdk的真正核心难点是大文件、甚至超大文件的上传,因此如何来进行上传呢?我们前面一篇文件已经大概讲解过核心思路了,这里再重复的讲解一下。
方案一:业务系统调用sdk上传接口上传文件,会存在一下缺点:
①如果业务系统不做切块(对别人进行技术要求,其实是很费劲的),直接上传整个完整文件,那么我们的网盘后端直接废掉
②即使业务系统做切块处理,但是标准的切块大小是多少合适?不同的业务系统可能的分片标准不一样,导致网盘系统其实很混乱。
③步骤繁琐,计算md5->判断md5是否存在->存在则秒传,否则继续上传->进行切块->上传切块->切块上传完成再合并切块。这一序列的繁琐步骤,增加了厂商的复杂度。弄不好还会被吐槽。
方案二:业务系统把文件上传到临时目录,sdk读取该文件上传,具体如下:
优点:
①厂商只需要把文件保存到其服务器的临时目录,然后告诉sdk文件路径,剩下的就不需要管了。
②sdk对文件进行以下处理,计算md5->判断md5是否存在,如果存在则秒传->获取文件大小->根据文件大小计算切块数量->开启子线程获取每个切块往服务器上传->所有子线程处理完成,则合并接口->删除文件
缺点:
①如果业务系统集群部署,业务系统前端传递过来的切块就会散落在各个服务器上,只能使用ip_hash策略模式,但是其实,我们不需要管这些,就是给业务系统定一个标准就是告诉我文件所在目录即可。
②如果文件很大,那么耗时可能会很长(测试:500M大概30s)
②消耗业务系统服务器资源
3.4、核心难点分析和解决
①如何计算大文件的MD5并且不会内存溢出,参考这个类
netdisk-client-javasdk
src/main/java
com.micro.netdisk.javasdk.fileutils.FileMd5Utils
②如何高效的读取文件呢?
- 使用NIO来读取文件,采用的是ByteBuffer+FileChannel模式,而不是传统的FileInputStream
③子线程处理切块上传,主线程如何进行堵塞,等所有子线程进行上传完成,主线程才进行接口合并呢?
- 方式一:J.U.C工具包,CountDownLatch、Semphore
- 方式二:Callable+Future
④HttpClient通讯模式,如何传递byte[]数组呢?
netdisk-client-javasdk
src/main/java
com.micro.netdisk.javasdk.transport.HttpTransport
⑤合适使用多线程+线程池+线程之间通讯,像文件上传这种操作如果光靠主线程一撸到底,那么肯定抗不住;如果不集成线程池,每个切块上传创建一个子线程,那么cpu直接卡死;线程之间需要通讯,比如,一旦发生异常,主线程如何去中断子线程等等问题。
⑥如何对文件进行切块呢?很多同学可能会感觉不懂怎么切分,其实非常的简单,只是大家可能会IO不够了解。
方案一:
- 把文件加载到内存,然后截取byte[],如果小文件则ok,大文件直接耗完内存
方案二:BIO,以下是伪代码
File file=new File("E:/a.zip");
FileInputStream fis=new FileInputStream(file);
int chunkNum=0;
//定义一个数组,这个其实就是切块的过程
byte[] bytes=new byte[1024];
//每次往bytes里面读取数据
while(fis.read(bytes)>0){
//把bytes数组上传服务器,然后清空bytes即可
//切块序号地址
chunkNum++;
}
方案三:NIO(推荐),以下是伪代码
File file=new File("E:/a.zip");
FileInputStream fis=new FileInputStream(file);
FileChannel fileChannel=fis.getChannel();
ByteBuffer buffer=ByteBuffer.allocate(1024);
int chunkNum=0;
while(fileChannel.read(buffer)>0){
buffer.flip();
byte[] dst=new byte[buffer.limit()];
buffer.get(dst, buffer.position(), buffer.limit());
buffer.clear();
//把dst往服务器上传即可
//切块序号地址
chunkNum++;
}
四、最后总结
好了,大概内容就到这里吧,由于涉及的内容比较多,只是把核心问题、解决方案梳理清楚,如果大家有兴趣可以自己去关注项目阅读源码。
慕课网专栏(架构思想之微服务+仿百度网盘源码):
https://www.imooc.com/read/73
感谢您的阅读,希望您多多支持,这样我在原创的道路上才能更加的有信心。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


